File-access Experiments on TIFF File¶
TIFF File Structure¶
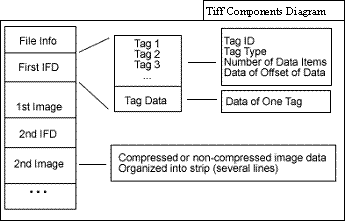
The following is the structure of the TIFF file.
Each Image File Directory (IFD) has the information of a sub-resolution (including the main/highest resolution) image as TAGs.

(Above image is from http://paulbourke.net/dataformats/tiff/tiff_summary.pdf [accessed Dec 9th, 2020])
For a tiled-multi-resolution TIFF image, TileWidth and TileLength TAGs of an IFD have tile size information, and TileOffsets and TileByteCounts TAGs include the information on each tile's the byte offset and the number of (compressed) bytes in the tile.
(This link shows all the TAGs available through the libtiff library.)

(Above image is from https://www.blackice.com/images/Cisco.GIF and https://docs.nframes.com/input-%2526-output/output-formats/ [accessed July 30th, 2020]])
{kind=link}
Since TileOffsets and TileByteCounts are an array of numbers to access each tile's raw(compressed) data, it is important to fast-read relevant tiles' compressed RAW image data from the file in any access patterns.
Access patterns¶
1. Accessing tiles sequentially (left to right, top to bottom) from one TIFF file¶
This can happen when a TIFF file is read from a single or multi threads/processes to convert/inference without any optimization.
2. Accessing tiles randomly from one TIFF file¶
This access pattern can happen usually on DeepLearning model inference use cases. For inference, only part of images are used, and accessing each tile is not done sequentially.
For example, a list of regions to be loaded/processed can be split into multiple threads/processes so accessing tiles can be out of order. Forthermore, (internal) tiles to be read for a specific region (patch) are not necessarily contiguous (e.g., tile index for position[x, y] (0, 0) and (0, 1) wouldn't be contiguous).
3. Accessing partial tiles randomly from multiple TIFF files¶
This access pattern usually happens on DeepLearning model training use cases.
To get unbiased weights of the neural network, it is necessary to provide randomized augmented training data during the model training, which means a random partial image region(patch) with the label needs to be picked from possible patch positions and file paths.
In the following experiment, we are exploring the implication of the various file access methods on reading partial images with different access patterns. We didn't experiment with access pattern #3 yet but experiment results for #1 and #2 would give us some insight about the possible improvements.
Experiment Setup¶
TIFF File Information¶
Information on the TIFF file under experiment:
# 92344 x 81017 pixels (@highest resolution) JPEG-compressed RGB image. Tile size: 256x256
# (input/image2.tif)
- file_size : 3,253,334,884
- tile_count : 114,437 (at the highest resolution)
- min_tile_bytecount: 1,677
- max_tile_bytecount: 31,361
- avg_tile_bytecount: 17,406.599404038905
- min_tile_offset : 1,373,824
- max_tile_offset : 1,993,332,840
System Information¶
- OS: Ubuntu 18.04
- CPU: Intel(R) Core(TM) i7-7800X CPU @ 3.50GHz
- Memory: 64GB (G-Skill DDR4 2133 16GB X 4)
- Storage
- NVMe SSD: Samsung SSD 970 PRO 1TB
- SATA SSD: Samsung SSD 850 EVO 1TB
- HDD: WDC WD40EZRX-00SPEB0 4TB
Procedure¶
We tried to load all tiles' raw data in the 3GB TIFF image 1) sequentially and 2) randomly with the following methods:
1) Regular POSIX¶
Using pread() with a regular file descriptor, read each tile's raw (compressed) data into CPU memory.
import cucim.clara.filesystem as fs
fd = fs.open("image2.tif", "rnp")
...
fd.close()
2) O_DIRECT¶
Using pread() with a file descriptor having O_DIRECT flag, read each tile's raw (compressed) data into CPU memory.
cuCIM's filesystem API handles unaligned memory/file offset for direct access (O_DIRECT).
import cucim.clara.filesystem as fs
fd = fs.open("image2.tif", "rp")
...
fd.close()
3) O_DIRECT pre-load¶
Load necessary whole data block at once (with O_DIRECT flag) that is necessary to access all tiles at the highest-resolution, into the temporary CPU memory. Then, copy the necessary data for each tile into the target buffer.
4) mmap¶
Use mmap() methods internally.
import cucim.clara.filesystem as fs
fd = fs.open("image2.tif", "rm")
...
fd.close()
Note:: Actual experiment was done with C++ implementation/APIs.
Results¶
Link to the spreadsheet: https://docs.google.com/spreadsheets/d/1DbPe0m2KRqlEFbZZTmP9rhDLZdG6mn_Uv8_DrZy97Uc/edit#gid=1257255419
NVMe¶

SSD¶

HDD¶

Analysis & Implication¶
- Reading tile data sequentially doesn't show much difference across configurations (except
O_DIRECT)- Using
O_DIRECTdoesn't perform well due to its unaligned memory access
- Using
- Using
O_DIRECT pre-loadapproach performs best, and usingmmapperforms better thanRegular POSIXorO_DIRECTmethods- but
O_DIRECT pre-loadapproach requires more CPU memory for pre-loading data so it may not good for the use case where only very small numbers of patches are needed from the file or the list of the patches to load from the file is not available in advance. - Using
mmapfor accessing TIFF tiles is a viable solution (current OpenSlide and cuCIM is using Regular POSIX APIs to access tile data) for improving cuCIM's performance and we can leverageO_DIRECT pre-loadapproach depending on the workflow.
- but
Appendix¶
Code used to measure performance¶
The following variables were changed according to the configuration.
constexpr bool SHUFFLE_LIST = true;
constexpr int iter_max = 32;
constexpr int skip_count = 2;
/*
* Copyright (c) 2020, NVIDIA CORPORATION.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include "cuslide/tiff/tiff.h"
#include "config.h"
#include <catch2/catch_test_macros.hpp>
#include <fmt/format.h>
#include <cucim/filesystem/cufile_driver.h>
#include <cstdlib>
#include <ctime>
#include <fcntl.h>
#include <unistd.h>
#include <cucim/logger/timer.h>
#include <iostream>
#include <fstream>
#include <sys/stat.h>
#include <sys/mman.h>
#define ALIGN_UP(x, align_to) (((uint64_t)(x) + ((uint64_t)(align_to)-1)) & ~((uint64_t)(align_to)-1))
#define ALIGN_DOWN(x, align_to) ((uint64_t)(x) & ~((uint64_t)(align_to)-1))
static void shuffle_offsets(uint32_t count, uint64_t* offsets, uint64_t* bytecounts)
{
// Fisher-Yates shuffle
for (int i = 0; i < count; ++i)
{
int j = (std::rand() % (count - i)) + i;
std::swap(offsets[i], offsets[j]);
std::swap(bytecounts[i], bytecounts[j]);
}
}
TEST_CASE("Verify raw tiff read", "[test_read_rawtiff.cpp]")
{
cudaError_t cuda_status;
int err;
constexpr int BLOCK_SECTOR_SIZE = 4096;
constexpr bool SHUFFLE_LIST = true;
constexpr int iter_max = 32;
constexpr int skip_count = 2;
std::srand(std::time(nullptr));
auto input_file = g_config.input_file.c_str(); // "/nvme/image2.tif"
struct stat sb;
auto fd_temp = ::open(input_file, O_RDONLY);
fstat(fd_temp, &sb);
uint64_t test_file_size = sb.st_size;
::close(fd_temp);
auto tif = std::make_shared<cuslide::tiff::TIFF>(input_file, O_RDONLY);
tif->construct_ifds();
tif->ifd(0)->write_offsets_(input_file);
std::ifstream offsets(fmt::format("{}.offsets", input_file), std::ios::in | std::ios::binary);
std::ifstream bytecounts(fmt::format("{}.bytecounts", input_file), std::ios::in | std::ios::binary);
// Read image piece count
uint32_t image_piece_count_ = 0;
offsets.read(reinterpret_cast<char*>(&image_piece_count_), sizeof(image_piece_count_));
bytecounts.read(reinterpret_cast<char*>(&image_piece_count_), sizeof(image_piece_count_));
uint64_t image_piece_offsets_[image_piece_count_];
uint64_t image_piece_bytecounts_[image_piece_count_];
uint64_t min_bytecount = 9999999999;
uint64_t max_bytecount = 0;
uint64_t sum_bytecount = 0;
uint64_t min_offset = 9999999999;
uint64_t max_offset = 0;
for (uint32_t i = 0; i < image_piece_count_; i++)
{
offsets.read((char*)&image_piece_offsets_[i], sizeof(image_piece_offsets_[i]));
bytecounts.read((char*)&image_piece_bytecounts_[i], sizeof(image_piece_bytecounts_[i]));
min_bytecount = std::min(min_bytecount, image_piece_bytecounts_[i]);
max_bytecount = std::max(max_bytecount, image_piece_bytecounts_[i]);
sum_bytecount += image_piece_bytecounts_[i];
min_offset = std::min(min_offset, image_piece_offsets_[i]);
max_offset = std::max(max_offset, image_piece_offsets_[i] + image_piece_bytecounts_[i]);
}
bytecounts.close();
offsets.close();
fmt::print("file_size : {}\n", test_file_size);
fmt::print("min_bytecount: {}\n", min_bytecount);
fmt::print("max_bytecount: {}\n", max_bytecount);
fmt::print("avg_bytecount: {}\n", static_cast<double>(sum_bytecount) / image_piece_count_);
fmt::print("min_offset : {}\n", min_offset);
fmt::print("max_offset : {}\n", max_offset);
uint64_t test_size = max_offset + max_bytecount;
// Shuffle offsets
if (SHUFFLE_LIST)
{
shuffle_offsets(image_piece_count_, image_piece_offsets_, image_piece_bytecounts_);
}
// Allocate memory
uint8_t* unaligned_host = static_cast<uint8_t*>(malloc(test_file_size + BLOCK_SECTOR_SIZE * 2));
uint8_t* buffer_host = static_cast<uint8_t*>(malloc(test_file_size + BLOCK_SECTOR_SIZE * 2));
uint8_t* aligned_host = reinterpret_cast<uint8_t*>(ALIGN_UP(unaligned_host, BLOCK_SECTOR_SIZE));
cucim::filesystem::discard_page_cache(input_file);
fmt::print("count:{} \n", image_piece_count_);
SECTION("Regular POSIX")
{
fmt::print("Regular POSIX\n");
double total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rpn");
{
cucim::logger::Timer timer("- read whole : {:.7f}\n", true, false);
ssize_t read_cnt = fd->pread(aligned_host, test_file_size, 0);
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Read whole average: {}\n", total_elapsed_time / (iter_max - skip_count));
total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rpn");
{
cucim::logger::Timer timer("- read tiles : {:.7f}\n", true, false);
for (uint32_t i = 0; i < image_piece_count_; ++i)
{
ssize_t read_cnt = fd->pread(aligned_host, image_piece_bytecounts_[i], image_piece_offsets_[i]);
}
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Read tiles average: {}\n", total_elapsed_time / (iter_max - skip_count));
}
SECTION("O_DIRECT")
{
fmt::print("O_DIRECT\n");
double total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rp");
{
cucim::logger::Timer timer("- read whole : {:.7f}\n", true, false);
ssize_t read_cnt = fd->pread(aligned_host, test_file_size, 0);
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Read whole average: {}\n", total_elapsed_time / (iter_max - skip_count));
total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rp");
{
cucim::logger::Timer timer("- read tiles : {:.7f}\n", true, false);
for (uint32_t i = 0; i < image_piece_count_; ++i)
{
ssize_t read_cnt = fd->pread(buffer_host, image_piece_bytecounts_[i], image_piece_offsets_[i]);
}
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Read tiles average: {}\n", total_elapsed_time / (iter_max - skip_count));
}
SECTION("O_DIRECT pre-load")
{
fmt::print("O_DIRECT pre-load\n");
size_t file_start_offset = ALIGN_DOWN(min_offset, BLOCK_SECTOR_SIZE);
size_t end_boundary_offset = ALIGN_UP(max_offset + max_bytecount, BLOCK_SECTOR_SIZE);
size_t large_block_size = end_boundary_offset - file_start_offset;
fmt::print("- size:{}\n", end_boundary_offset - file_start_offset);
double total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rp");
{
cucim::logger::Timer timer("- preload : {:.7f}\n", true, false);
ssize_t read_cnt = fd->pread(aligned_host, large_block_size, file_start_offset);
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Preload average: {}\n", total_elapsed_time / (iter_max - skip_count));
total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rp");
{
cucim::logger::Timer timer("- read tiles : {:.7f}\n", true, false);
for (uint32_t i = 0; i < image_piece_count_; ++i)
{
memcpy(buffer_host, aligned_host + image_piece_offsets_[i] - file_start_offset,
image_piece_bytecounts_[i]);
}
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Read tiles average: {}\n", total_elapsed_time / (iter_max - skip_count));
}
SECTION("mmap")
{
fmt::print("mmap\n");
double total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd_mmap = open(input_file, O_RDONLY);
{
cucim::logger::Timer timer("- open/close : {:.7f}\n", true, false);
void* mmap_host = mmap((void*)0, test_file_size, PROT_READ, MAP_SHARED, fd_mmap, 0);
REQUIRE(mmap_host != MAP_FAILED);
if (mmap_host != MAP_FAILED)
{
REQUIRE(munmap(mmap_host, test_file_size) != -1);
close(fd_mmap);
}
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- mmap/munmap average: {}\n", total_elapsed_time / (iter_max - skip_count));
total_elapsed_time = 0;
for (int iter = 0; iter < iter_max; ++iter)
{
cucim::filesystem::discard_page_cache(input_file);
auto fd = cucim::filesystem::open(input_file, "rm");
{
cucim::logger::Timer timer("- read tiles : {:.7f}\n", true, false);
for (uint32_t i = 0; i < image_piece_count_; ++i)
{
ssize_t read_cnt = fd->pread(buffer_host, image_piece_bytecounts_[i], image_piece_offsets_[i]);
}
double elapsed_time = timer.stop();
if (iter >= skip_count)
{
total_elapsed_time += elapsed_time;
}
timer.print();
}
}
fmt::print("- Read tiles average: {}\n", total_elapsed_time / (iter_max - skip_count));
}
free(unaligned_host);
free(buffer_host);
}