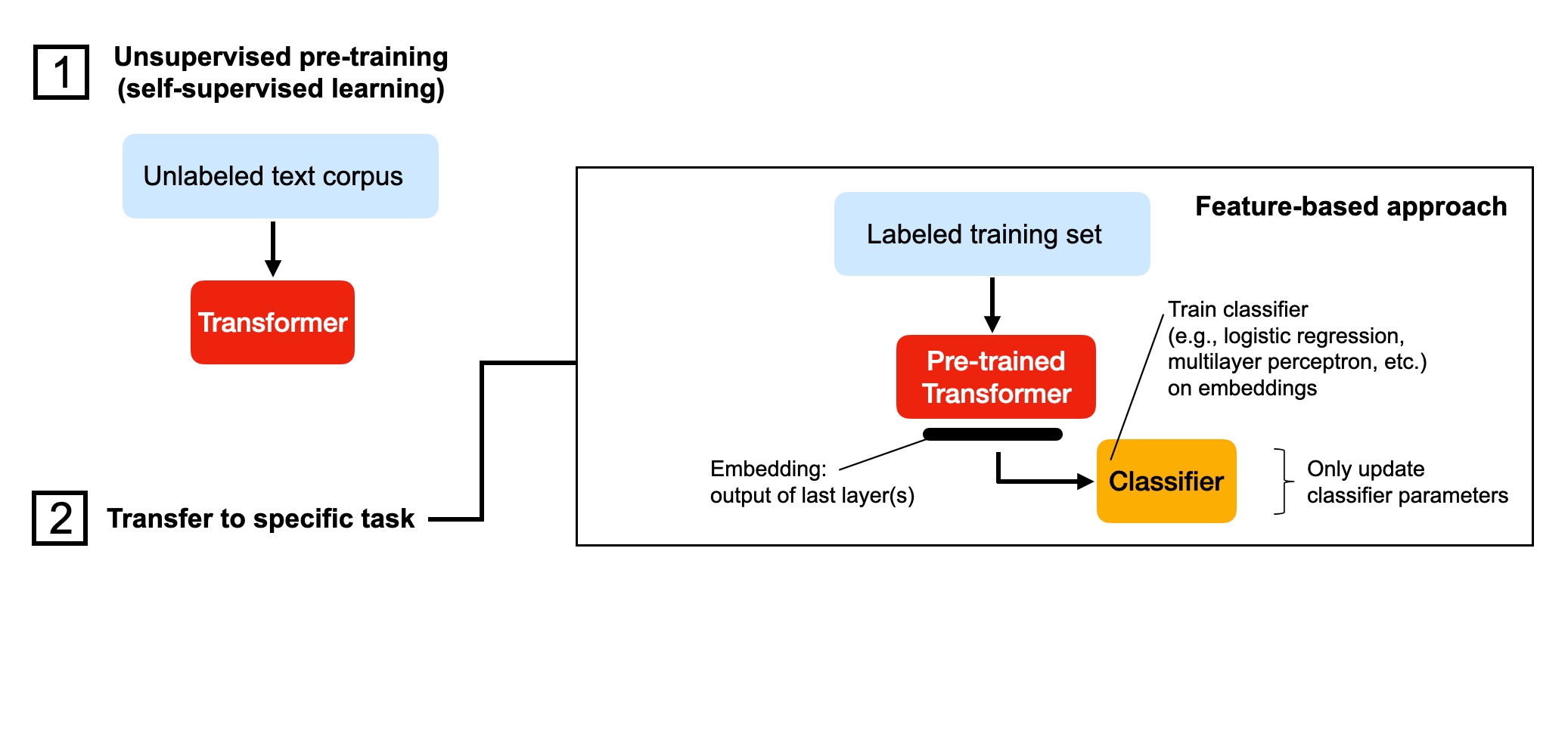
DistilBERT Classifier as Feature Extractor Using Embetter¶
In this feature-based approach, we are using the embeddings from a pretrained transormer to train a random forest and logistic regression model in scikit-learn:
# pip install transformers datasets
# conda install sklearn --yes
In addition, we will be using the embetter scikit-learn library:
%load_ext watermark
%watermark --conda -p torch,transformers,datasets,sklearn
torch : 1.12.1 transformers: 4.23.1 datasets : 2.6.1 sklearn : 0.0 conda environment: dl-fundamentals
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
cuda:0
1 Loading the Dataset¶
The IMDB movie review dataset consists of 50k movie reviews with sentiment label (0: negative, 1: positive).
1a) Load from datasets Hub¶
from datasets import list_datasets, load_dataset
# list_datasets()
imdb_data = load_dataset("imdb")
print(imdb_data)
Found cached dataset imdb (/home/raschka/.cache/huggingface/datasets/imdb/plain_text/1.0.0/2fdd8b9bcadd6e7055e742a706876ba43f19faee861df134affd7a3f60fc38a1)
0%| | 0/3 [00:00<?, ?it/s]
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})
imdb_data["train"][99]
{'text': "This film is terrible. You don't really need to read this review further. If you are planning on watching it, suffice to say - don't (unless you are studying how not to make a good movie).<br /><br />The acting is horrendous... serious amateur hour. Throughout the movie I thought that it was interesting that they found someone who speaks and looks like Michael Madsen, only to find out that it is actually him! A new low even for him!!<br /><br />The plot is terrible. People who claim that it is original or good have probably never seen a decent movie before. Even by the standard of Hollywood action flicks, this is a terrible movie.<br /><br />Don't watch it!!! Go for a jog instead - at least you won't feel like killing yourself.",
'label': 0}
1b) Load from local directory¶
The IMDB movie review set can be downloaded from http://ai.stanford.edu/~amaas/data/sentiment/. After downloading the dataset, decompress the files.
A) If you are working with Linux or MacOS X, open a new terminal windowm cd into the download directory and execute
tar -zxf aclImdb_v1.tar.gz
B) If you are working with Windows, download an archiver such as 7Zip to extract the files from the download archive.
C) Use the following code to download and unzip the dataset via Python
Download the movie reviews
import os
import sys
import tarfile
import time
import urllib.request
source = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
target = "aclImdb_v1.tar.gz"
if os.path.exists(target):
os.remove(target)
def reporthook(count, block_size, total_size):
global start_time
if count == 0:
start_time = time.time()
return
duration = time.time() - start_time
progress_size = int(count * block_size)
speed = progress_size / (1024.0**2 * duration)
percent = count * block_size * 100.0 / total_size
sys.stdout.write(
f"\r{int(percent)}% | {progress_size / (1024.**2):.2f} MB "
f"| {speed:.2f} MB/s | {duration:.2f} sec elapsed"
)
sys.stdout.flush()
if not os.path.isdir("aclImdb") and not os.path.isfile("aclImdb_v1.tar.gz"):
urllib.request.urlretrieve(source, target, reporthook)
if not os.path.isdir("aclImdb"):
with tarfile.open(target, "r:gz") as tar:
tar.extractall()
Convert them to a pandas DataFrame and save them as CSV
import os
import sys
import numpy as np
import pandas as pd
from packaging import version
from tqdm import tqdm
# change the `basepath` to the directory of the
# unzipped movie dataset
basepath = "aclImdb"
labels = {"pos": 1, "neg": 0}
df = pd.DataFrame()
with tqdm(total=50000) as pbar:
for s in ("test", "train"):
for l in ("pos", "neg"):
path = os.path.join(basepath, s, l)
for file in sorted(os.listdir(path)):
with open(os.path.join(path, file), "r", encoding="utf-8") as infile:
txt = infile.read()
if version.parse(pd.__version__) >= version.parse("1.3.2"):
x = pd.DataFrame(
[[txt, labels[l]]], columns=["review", "sentiment"]
)
df = pd.concat([df, x], ignore_index=False)
else:
df = df.append([[txt, labels[l]]], ignore_index=True)
pbar.update()
df.columns = ["text", "label"]
100%|███████████████████████████████████████████████████████| 50000/50000 [00:55<00:00, 893.83it/s]
import numpy as np
np.random.seed(0)
df = df.reindex(np.random.permutation(df.index))
Basic datasets analysis and sanity checks
print("Class distribution:")
np.bincount(df["label"].values)
Class distribution:
array([25000, 25000])
text_len = df["text"].apply(lambda x: len(x.split()))
text_len.min(), text_len.median(), text_len.max()
(4, 173.0, 2470)
Split data into training, validation, and test sets
df_shuffled = df.sample(frac=1, random_state=1).reset_index()
df_train = df_shuffled.iloc[:35_000]
df_val = df_shuffled.iloc[35_000:40_000]
df_test = df_shuffled.iloc[40_000:]
df_train.to_csv("train.csv", index=False, encoding="utf-8")
df_val.to_csv("validation.csv", index=False, encoding="utf-8")
df_test.to_csv("test.csv", index=False, encoding="utf-8")
df_train.head()
| index | text | label | |
|---|---|---|---|
| 0 | 0 | When we started watching this series on cable,... | 1 |
| 1 | 0 | Steve Biko was a black activist who tried to r... | 1 |
| 2 | 0 | My short comment for this flick is go pick it ... | 1 |
| 3 | 0 | As a serious horror fan, I get that certain ma... | 0 |
| 4 | 0 | Robert Cummings, Laraine Day and Jean Muir sta... | 1 |
2 Train Model on Embeddings (Extracted Features)¶
import pandas as pd
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from embetter.text import SentenceEncoder
classifier = make_pipeline(
SentenceEncoder("distiluse-base-multilingual-cased-v2"),
LogisticRegression()
)
classifier.fit(df_train["text"].values, df_train["label"].values);
classifier.score(df_val["text"].values, df_val["label"].values)
0.8
classifier.score(df_test["text"].values, df_test["label"].values)
0.8032