Deep Learning Models -- A collection of various deep learning architectures, models, and tips for TensorFlow and PyTorch in Jupyter Notebooks.
- Author: Sebastian Raschka
- GitHub Repository: https://github.com/rasbt/deeplearning-models
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
Sebastian Raschka CPython 3.6.8 IPython 7.2.0 torch 1.0.0
Model Zoo -- CNN Gender Classifier (ResNet-152 Architecture, CelebA) with Data Parallelism¶
Network Architecture¶
The network in this notebook is an implementation of the ResNet-152 [1] architecture on the CelebA face dataset [2] to train a gender classifier.
References
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778). (CVPR Link)
[2] Zhang, K., Tan, L., Li, Z., & Qiao, Y. (2016). Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 34-38).
The ResNet-152 architecture is similar to the ResNet-50 architecture, which is in turn similar to the ResNet-34 architecture shown below (from [1]) except that the ResNet 101 is using a Bootleneck block (compared to ResNet-34) and more layers than ResNet-50 (figure shows a screenshot from [1]):

The following figure illustrates residual blocks with skip connections such that the input passed via the shortcut matches the dimensions of the main path's output, which allows the network to learn identity functions.

The ResNet-34 architecture actually uses residual blocks with modified skip connections such that the input passed via the shortcut matches is resized to dimensions of the main path's output. Such a residual block is illustrated below:
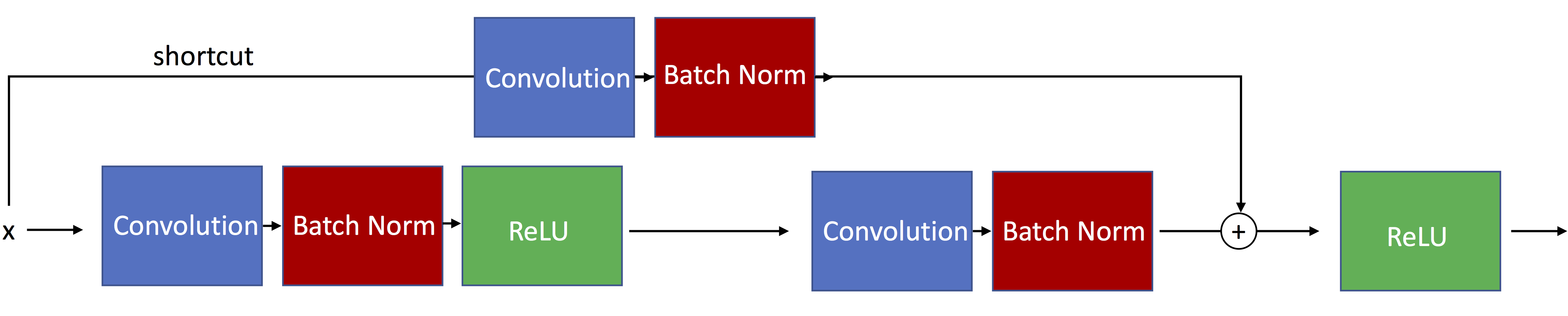
The ResNet-50/101/151 then uses a bottleneck as shown below:

For a more detailed explanation see the other notebook, resnet-ex-1.ipynb.
Imports¶
import os
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
Settings¶
##########################
### SETTINGS
##########################
# Hyperparameters
RANDOM_SEED = 1
LEARNING_RATE = 0.001
NUM_EPOCHS = 10
# Architecture
NUM_FEATURES = 128*128
NUM_CLASSES = 2
BATCH_SIZE = 128
DEVICE = 'cuda:2' # default GPU device
GRAYSCALE = False
Dataset¶
Downloading the Dataset¶
Note that the ~200,000 CelebA face image dataset is relatively large (~1.3 Gb). The download link provided below was provided by the author on the official CelebA website at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html.
Download and unzip the file
img_align_celeba.zip, which contains the images in jpeg format.Download the
list_attr_celeba.txtfile, which contains the class labelsDownload the
list_eval_partition.txtfile, which contains training/validation/test partitioning info
Preparing the Dataset¶
df1 = pd.read_csv('list_attr_celeba.txt', sep="\s+", skiprows=1, usecols=['Male'])
# Make 0 (female) & 1 (male) labels instead of -1 & 1
df1.loc[df1['Male'] == -1, 'Male'] = 0
df1.head()
| Male | |
|---|---|
| 000001.jpg | 0 |
| 000002.jpg | 0 |
| 000003.jpg | 1 |
| 000004.jpg | 0 |
| 000005.jpg | 0 |
df2 = pd.read_csv('list_eval_partition.txt', sep="\s+", skiprows=0, header=None)
df2.columns = ['Filename', 'Partition']
df2 = df2.set_index('Filename')
df2.head()
| Partition | |
|---|---|
| Filename | |
| 000001.jpg | 0 |
| 000002.jpg | 0 |
| 000003.jpg | 0 |
| 000004.jpg | 0 |
| 000005.jpg | 0 |
df3 = df1.merge(df2, left_index=True, right_index=True)
df3.head()
| Male | Partition | |
|---|---|---|
| 000001.jpg | 0 | 0 |
| 000002.jpg | 0 | 0 |
| 000003.jpg | 1 | 0 |
| 000004.jpg | 0 | 0 |
| 000005.jpg | 0 | 0 |
df3.to_csv('celeba-gender-partitions.csv')
df4 = pd.read_csv('celeba-gender-partitions.csv', index_col=0)
df4.head()
| Male | Partition | |
|---|---|---|
| 000001.jpg | 0 | 0 |
| 000002.jpg | 0 | 0 |
| 000003.jpg | 1 | 0 |
| 000004.jpg | 0 | 0 |
| 000005.jpg | 0 | 0 |
df4.loc[df4['Partition'] == 0].to_csv('celeba-gender-train.csv')
df4.loc[df4['Partition'] == 1].to_csv('celeba-gender-valid.csv')
df4.loc[df4['Partition'] == 2].to_csv('celeba-gender-test.csv')
img = Image.open('img_align_celeba/000001.jpg')
print(np.asarray(img, dtype=np.uint8).shape)
plt.imshow(img);
(218, 178, 3)

Implementing a Custom DataLoader Class¶
class CelebaDataset(Dataset):
"""Custom Dataset for loading CelebA face images"""
def __init__(self, csv_path, img_dir, transform=None):
df = pd.read_csv(csv_path, index_col=0)
self.img_dir = img_dir
self.csv_path = csv_path
self.img_names = df.index.values
self.y = df['Male'].values
self.transform = transform
def __getitem__(self, index):
img = Image.open(os.path.join(self.img_dir,
self.img_names[index]))
if self.transform is not None:
img = self.transform(img)
label = self.y[index]
return img, label
def __len__(self):
return self.y.shape[0]
# Note that transforms.ToTensor()
# already divides pixels by 255. internally
custom_transform = transforms.Compose([transforms.CenterCrop((178, 178)),
transforms.Resize((128, 128)),
#transforms.Grayscale(),
#transforms.Lambda(lambda x: x/255.),
transforms.ToTensor()])
train_dataset = CelebaDataset(csv_path='celeba-gender-train.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
valid_dataset = CelebaDataset(csv_path='celeba-gender-valid.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
test_dataset = CelebaDataset(csv_path='celeba-gender-test.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4)
torch.manual_seed(0)
for epoch in range(2):
for batch_idx, (x, y) in enumerate(train_loader):
print('Epoch:', epoch+1, end='')
print(' | Batch index:', batch_idx, end='')
print(' | Batch size:', y.size()[0])
x = x.to(DEVICE)
y = y.to(DEVICE)
time.sleep(1)
break
Epoch: 1 | Batch index: 0 | Batch size: 128 Epoch: 2 | Batch index: 0 | Batch size: 128
Model¶
The following code cell that implements the ResNet-34 architecture is a derivative of the code provided at https://pytorch.org/docs/0.4.0/_modules/torchvision/models/resnet.html.
##########################
### MODEL
##########################
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes, grayscale):
self.inplanes = 64
if grayscale:
in_dim = 1
else:
in_dim = 3
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(in_dim, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1, padding=2)
self.fc = nn.Linear(2048 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, (2. / n)**.5)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
logits = self.fc(x)
probas = F.softmax(logits, dim=1)
return logits, probas
def resnet152(num_classes, grayscale):
"""Constructs a ResNet-152 model."""
model = ResNet(block=Bottleneck,
layers=[3, 4, 36, 3],
num_classes=NUM_CLASSES,
grayscale=grayscale)
return model
torch.manual_seed(RANDOM_SEED)
##########################
### COST AND OPTIMIZER
##########################
model = resnet152(NUM_CLASSES, GRAYSCALE)
model.to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
Training¶
def compute_accuracy(model, data_loader, device):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 50:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, NUM_EPOCHS, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%% | Valid: %.3f%%' % (
epoch+1, NUM_EPOCHS,
compute_accuracy(model, train_loader, device=DEVICE),
compute_accuracy(model, valid_loader, device=DEVICE)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
Epoch: 001/010 | Batch 0000/1272 | Cost: 0.7148 Epoch: 001/010 | Batch 0050/1272 | Cost: 0.6455 Epoch: 001/010 | Batch 0100/1272 | Cost: 0.4099 Epoch: 001/010 | Batch 0150/1272 | Cost: 0.2189 Epoch: 001/010 | Batch 0200/1272 | Cost: 0.2228 Epoch: 001/010 | Batch 0250/1272 | Cost: 0.2147 Epoch: 001/010 | Batch 0300/1272 | Cost: 0.1621 Epoch: 001/010 | Batch 0350/1272 | Cost: 0.1987 Epoch: 001/010 | Batch 0400/1272 | Cost: 0.1688 Epoch: 001/010 | Batch 0450/1272 | Cost: 0.2529 Epoch: 001/010 | Batch 0500/1272 | Cost: 0.2114 Epoch: 001/010 | Batch 0550/1272 | Cost: 0.1637 Epoch: 001/010 | Batch 0600/1272 | Cost: 0.1147 Epoch: 001/010 | Batch 0650/1272 | Cost: 0.2357 Epoch: 001/010 | Batch 0700/1272 | Cost: 0.1656 Epoch: 001/010 | Batch 0750/1272 | Cost: 0.0716 Epoch: 001/010 | Batch 0800/1272 | Cost: 0.0936 Epoch: 001/010 | Batch 0850/1272 | Cost: 0.2091 Epoch: 001/010 | Batch 0900/1272 | Cost: 0.0778 Epoch: 001/010 | Batch 0950/1272 | Cost: 0.1051 Epoch: 001/010 | Batch 1000/1272 | Cost: 0.2065 Epoch: 001/010 | Batch 1050/1272 | Cost: 0.1207 Epoch: 001/010 | Batch 1100/1272 | Cost: 0.1522 Epoch: 001/010 | Batch 1150/1272 | Cost: 0.1350 Epoch: 001/010 | Batch 1200/1272 | Cost: 0.0743 Epoch: 001/010 | Batch 1250/1272 | Cost: 0.1881 Epoch: 001/010 | Train: 95.689% | Valid: 96.139% Time elapsed: 17.02 min Epoch: 002/010 | Batch 0000/1272 | Cost: 0.1336 Epoch: 002/010 | Batch 0050/1272 | Cost: 0.0961 Epoch: 002/010 | Batch 0100/1272 | Cost: 0.0340 Epoch: 002/010 | Batch 0150/1272 | Cost: 0.1562 Epoch: 002/010 | Batch 0200/1272 | Cost: 0.0968 Epoch: 002/010 | Batch 0250/1272 | Cost: 0.0795 Epoch: 002/010 | Batch 0300/1272 | Cost: 0.0635 Epoch: 002/010 | Batch 0350/1272 | Cost: 0.1017 Epoch: 002/010 | Batch 0400/1272 | Cost: 0.0406 Epoch: 002/010 | Batch 0450/1272 | Cost: 0.0972 Epoch: 002/010 | Batch 0500/1272 | Cost: 0.1341 Epoch: 002/010 | Batch 0550/1272 | Cost: 0.1311 Epoch: 002/010 | Batch 0600/1272 | Cost: 0.0875 Epoch: 002/010 | Batch 0650/1272 | Cost: 0.0430 Epoch: 002/010 | Batch 0700/1272 | Cost: 0.0517 Epoch: 002/010 | Batch 0750/1272 | Cost: 0.0735 Epoch: 002/010 | Batch 0800/1272 | Cost: 0.0446 Epoch: 002/010 | Batch 0850/1272 | Cost: 0.1644 Epoch: 002/010 | Batch 0900/1272 | Cost: 0.0575 Epoch: 002/010 | Batch 0950/1272 | Cost: 0.0547 Epoch: 002/010 | Batch 1000/1272 | Cost: 0.1019 Epoch: 002/010 | Batch 1050/1272 | Cost: 0.1229 Epoch: 002/010 | Batch 1100/1272 | Cost: 0.1009 Epoch: 002/010 | Batch 1150/1272 | Cost: 0.1092 Epoch: 002/010 | Batch 1200/1272 | Cost: 0.0293 Epoch: 002/010 | Batch 1250/1272 | Cost: 0.1025 Epoch: 002/010 | Train: 96.899% | Valid: 96.920% Time elapsed: 36.16 min Epoch: 003/010 | Batch 0000/1272 | Cost: 0.0454 Epoch: 003/010 | Batch 0050/1272 | Cost: 0.0702 Epoch: 003/010 | Batch 0100/1272 | Cost: 0.0256 Epoch: 003/010 | Batch 0150/1272 | Cost: 0.1387 Epoch: 003/010 | Batch 0200/1272 | Cost: 0.0935 Epoch: 003/010 | Batch 0250/1272 | Cost: 0.1291 Epoch: 003/010 | Batch 0300/1272 | Cost: 0.0718 Epoch: 003/010 | Batch 0350/1272 | Cost: 0.0668 Epoch: 003/010 | Batch 0400/1272 | Cost: 0.0440 Epoch: 003/010 | Batch 0450/1272 | Cost: 0.0551 Epoch: 003/010 | Batch 0500/1272 | Cost: 0.0620 Epoch: 003/010 | Batch 0550/1272 | Cost: 0.0191 Epoch: 003/010 | Batch 0600/1272 | Cost: 0.0869 Epoch: 003/010 | Batch 0650/1272 | Cost: 0.0524 Epoch: 003/010 | Batch 0700/1272 | Cost: 0.0461 Epoch: 003/010 | Batch 0750/1272 | Cost: 0.1172 Epoch: 003/010 | Batch 0800/1272 | Cost: 0.0409 Epoch: 003/010 | Batch 0850/1272 | Cost: 0.0294 Epoch: 003/010 | Batch 0900/1272 | Cost: 0.0899 Epoch: 003/010 | Batch 0950/1272 | Cost: 0.1365 Epoch: 003/010 | Batch 1000/1272 | Cost: 0.0700 Epoch: 003/010 | Batch 1050/1272 | Cost: 0.0687 Epoch: 003/010 | Batch 1100/1272 | Cost: 0.0645 Epoch: 003/010 | Batch 1150/1272 | Cost: 0.0878 Epoch: 003/010 | Batch 1200/1272 | Cost: 0.0473 Epoch: 003/010 | Batch 1250/1272 | Cost: 0.1231 Epoch: 003/010 | Train: 97.895% | Valid: 97.770% Time elapsed: 51.91 min Epoch: 004/010 | Batch 0000/1272 | Cost: 0.0516 Epoch: 004/010 | Batch 0050/1272 | Cost: 0.0579 Epoch: 004/010 | Batch 0100/1272 | Cost: 0.0487 Epoch: 004/010 | Batch 0150/1272 | Cost: 0.0394 Epoch: 004/010 | Batch 0200/1272 | Cost: 0.0205 Epoch: 004/010 | Batch 0250/1272 | Cost: 0.0628 Epoch: 004/010 | Batch 0300/1272 | Cost: 0.0522 Epoch: 004/010 | Batch 0350/1272 | Cost: 0.0456 Epoch: 004/010 | Batch 0400/1272 | Cost: 0.0370 Epoch: 004/010 | Batch 0450/1272 | Cost: 0.0460 Epoch: 004/010 | Batch 0500/1272 | Cost: 0.0784 Epoch: 004/010 | Batch 0550/1272 | Cost: 0.0632 Epoch: 004/010 | Batch 0600/1272 | Cost: 0.0721 Epoch: 004/010 | Batch 0650/1272 | Cost: 0.1943 Epoch: 004/010 | Batch 0700/1272 | Cost: 0.0365 Epoch: 004/010 | Batch 0750/1272 | Cost: 0.0437 Epoch: 004/010 | Batch 0800/1272 | Cost: 0.0335 Epoch: 004/010 | Batch 0850/1272 | Cost: 0.0897 Epoch: 004/010 | Batch 0900/1272 | Cost: 0.0661 Epoch: 004/010 | Batch 0950/1272 | Cost: 0.1020 Epoch: 004/010 | Batch 1000/1272 | Cost: 0.0935 Epoch: 004/010 | Batch 1050/1272 | Cost: 0.1341 Epoch: 004/010 | Batch 1100/1272 | Cost: 0.0694 Epoch: 004/010 | Batch 1150/1272 | Cost: 0.0634 Epoch: 004/010 | Batch 1200/1272 | Cost: 0.0721 Epoch: 004/010 | Batch 1250/1272 | Cost: 0.0504 Epoch: 004/010 | Train: 97.629% | Valid: 97.634% Time elapsed: 67.70 min Epoch: 005/010 | Batch 0000/1272 | Cost: 0.0560 Epoch: 005/010 | Batch 0050/1272 | Cost: 0.0277 Epoch: 005/010 | Batch 0100/1272 | Cost: 0.0239 Epoch: 005/010 | Batch 0150/1272 | Cost: 0.0721 Epoch: 005/010 | Batch 0200/1272 | Cost: 0.0570 Epoch: 005/010 | Batch 0250/1272 | Cost: 0.0258 Epoch: 005/010 | Batch 0300/1272 | Cost: 0.0349 Epoch: 005/010 | Batch 0350/1272 | Cost: 0.0479 Epoch: 005/010 | Batch 0400/1272 | Cost: 0.0406 Epoch: 005/010 | Batch 0450/1272 | Cost: 0.0580 Epoch: 005/010 | Batch 0500/1272 | Cost: 0.0167 Epoch: 005/010 | Batch 0550/1272 | Cost: 0.0593 Epoch: 005/010 | Batch 0600/1272 | Cost: 0.0273 Epoch: 005/010 | Batch 0650/1272 | Cost: 0.0446 Epoch: 005/010 | Batch 0700/1272 | Cost: 0.0171 Epoch: 005/010 | Batch 0750/1272 | Cost: 0.1026 Epoch: 005/010 | Batch 0800/1272 | Cost: 0.0624 Epoch: 005/010 | Batch 0850/1272 | Cost: 0.0731 Epoch: 005/010 | Batch 0900/1272 | Cost: 0.0480 Epoch: 005/010 | Batch 0950/1272 | Cost: 0.0968 Epoch: 005/010 | Batch 1000/1272 | Cost: 0.0164 Epoch: 005/010 | Batch 1050/1272 | Cost: 0.0946 Epoch: 005/010 | Batch 1100/1272 | Cost: 0.0524 Epoch: 005/010 | Batch 1150/1272 | Cost: 0.0421 Epoch: 005/010 | Batch 1200/1272 | Cost: 0.0779 Epoch: 005/010 | Batch 1250/1272 | Cost: 0.0367 Epoch: 005/010 | Train: 97.482% | Valid: 97.327% Time elapsed: 83.43 min Epoch: 006/010 | Batch 0000/1272 | Cost: 0.0753 Epoch: 006/010 | Batch 0050/1272 | Cost: 0.0498 Epoch: 006/010 | Batch 0100/1272 | Cost: 0.0319 Epoch: 006/010 | Batch 0150/1272 | Cost: 0.0550 Epoch: 006/010 | Batch 0200/1272 | Cost: 0.0922 Epoch: 006/010 | Batch 0250/1272 | Cost: 0.0564 Epoch: 006/010 | Batch 0300/1272 | Cost: 0.0505 Epoch: 006/010 | Batch 0350/1272 | Cost: 0.0697 Epoch: 006/010 | Batch 0400/1272 | Cost: 0.0434 Epoch: 006/010 | Batch 0450/1272 | Cost: 0.0854 Epoch: 006/010 | Batch 0500/1272 | Cost: 0.0356 Epoch: 006/010 | Batch 0550/1272 | Cost: 0.0565 Epoch: 006/010 | Batch 0600/1272 | Cost: 0.0969 Epoch: 006/010 | Batch 0650/1272 | Cost: 0.0479 Epoch: 006/010 | Batch 0700/1272 | Cost: 0.0556 Epoch: 006/010 | Batch 0750/1272 | Cost: 0.0409 Epoch: 006/010 | Batch 0800/1272 | Cost: 0.0493 Epoch: 006/010 | Batch 0850/1272 | Cost: 0.0604 Epoch: 006/010 | Batch 0900/1272 | Cost: 0.0386 Epoch: 006/010 | Batch 0950/1272 | Cost: 0.0465 Epoch: 006/010 | Batch 1000/1272 | Cost: 0.0526 Epoch: 006/010 | Batch 1050/1272 | Cost: 0.0192 Epoch: 006/010 | Batch 1100/1272 | Cost: 0.0300 Epoch: 006/010 | Batch 1150/1272 | Cost: 0.0607 Epoch: 006/010 | Batch 1200/1272 | Cost: 0.1048 Epoch: 006/010 | Batch 1250/1272 | Cost: 0.0237 Epoch: 006/010 | Train: 98.128% | Valid: 97.851% Time elapsed: 99.20 min Epoch: 007/010 | Batch 0000/1272 | Cost: 0.0240 Epoch: 007/010 | Batch 0050/1272 | Cost: 0.0638 Epoch: 007/010 | Batch 0100/1272 | Cost: 0.0192 Epoch: 007/010 | Batch 0150/1272 | Cost: 0.0800 Epoch: 007/010 | Batch 0200/1272 | Cost: 0.0562 Epoch: 007/010 | Batch 0250/1272 | Cost: 0.0293 Epoch: 007/010 | Batch 0300/1272 | Cost: 0.0558 Epoch: 007/010 | Batch 0350/1272 | Cost: 0.0206 Epoch: 007/010 | Batch 0400/1272 | Cost: 0.0315 Epoch: 007/010 | Batch 0450/1272 | Cost: 0.0339 Epoch: 007/010 | Batch 0500/1272 | Cost: 0.0311 Epoch: 007/010 | Batch 0550/1272 | Cost: 0.0366 Epoch: 007/010 | Batch 0600/1272 | Cost: 0.0638 Epoch: 007/010 | Batch 0650/1272 | Cost: 0.0610 Epoch: 007/010 | Batch 0700/1272 | Cost: 0.0597 Epoch: 007/010 | Batch 0750/1272 | Cost: 0.0489 Epoch: 007/010 | Batch 0800/1272 | Cost: 0.0512 Epoch: 007/010 | Batch 0850/1272 | Cost: 0.0995 Epoch: 007/010 | Batch 0900/1272 | Cost: 0.0364 Epoch: 007/010 | Batch 0950/1272 | Cost: 0.1224 Epoch: 007/010 | Batch 1000/1272 | Cost: 0.0514 Epoch: 007/010 | Batch 1050/1272 | Cost: 0.0663 Epoch: 007/010 | Batch 1100/1272 | Cost: 0.0514 Epoch: 007/010 | Batch 1150/1272 | Cost: 0.0148 Epoch: 007/010 | Batch 1200/1272 | Cost: 0.0304 Epoch: 007/010 | Batch 1250/1272 | Cost: 0.0482
Evaluation¶
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))
for batch_idx, (features, targets) in enumerate(test_loader):
features = features
targets = targets
break
plt.imshow(np.transpose(features[0], (1, 2, 0)))
model.eval()
logits, probas = model(features.to(DEVICE)[0, None])
print('Probability Female %.2f%%' % (probas[0][0]*100))
%watermark -iv