Deep Learning Models -- A collection of various deep learning architectures, models, and tips for TensorFlow and PyTorch in Jupyter Notebooks.
- Author: Sebastian Raschka
- GitHub Repository: https://github.com/rasbt/deeplearning-models
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
Sebastian Raschka CPython 3.6.8 IPython 7.2.0 torch 1.0.0
Model Zoo -- CNN Gender Classifier (ResNet-18 Architecture, CelebA) with Data Parallelism¶
Network Architecture¶
The network in this notebook is an implementation of the ResNet-18 [1] architecture on the CelebA face dataset [2] to train a gender classifier.
References
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778). (CVPR Link)
[2] Zhang, K., Tan, L., Li, Z., & Qiao, Y. (2016). Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 34-38).
The following figure illustrates residual blocks with skip connections such that the input passed via the shortcut matches the dimensions of the main path's output, which allows the network to learn identity functions.

The ResNet-18 architecture actually uses residual blocks with skip connections such that the input passed via the shortcut matches is resized to dimensions of the main path's output. Such a residual block is illustrated below:
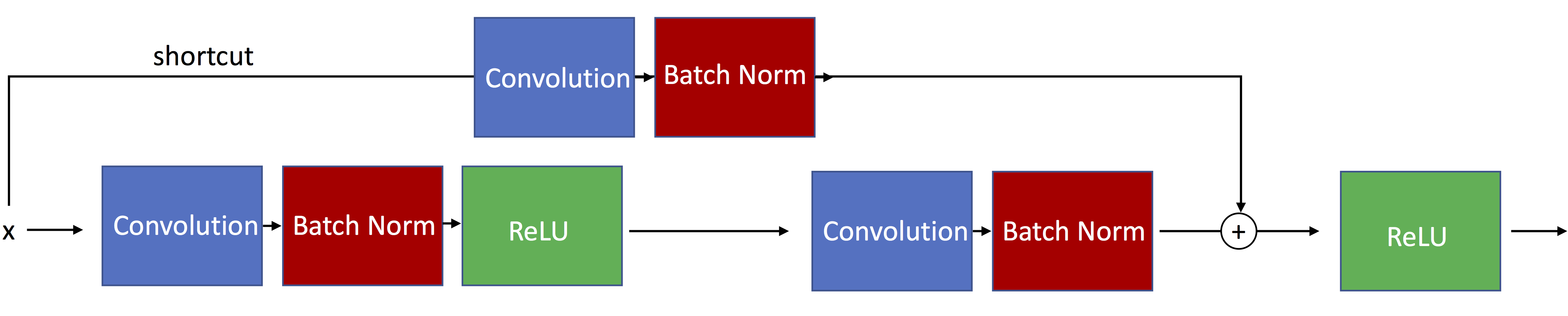
For a more detailed explanation see the other notebook, resnet-ex-1.ipynb.
Imports¶
import os
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
Settings¶
##########################
### SETTINGS
##########################
# Hyperparameters
RANDOM_SEED = 1
LEARNING_RATE = 0.001
NUM_EPOCHS = 10
# Architecture
NUM_FEATURES = 128*128
NUM_CLASSES = 2
BATCH_SIZE = 256*torch.cuda.device_count()
DEVICE = 'cuda:0' # default GPU device
GRAYSCALE = False
Dataset¶
Downloading the Dataset¶
Note that the ~200,000 CelebA face image dataset is relatively large (~1.3 Gb). The download link provided below was provided by the author on the official CelebA website at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html.
Download and unzip the file
img_align_celeba.zip, which contains the images in jpeg format.Download the
list_attr_celeba.txtfile, which contains the class labelsDownload the
list_eval_partition.txtfile, which contains training/validation/test partitioning info
Preparing the Dataset¶
df1 = pd.read_csv('list_attr_celeba.txt', sep="\s+", skiprows=1, usecols=['Male'])
# Make 0 (female) & 1 (male) labels instead of -1 & 1
df1.loc[df1['Male'] == -1, 'Male'] = 0
df1.head()
| Male | |
|---|---|
| 000001.jpg | 0 |
| 000002.jpg | 0 |
| 000003.jpg | 1 |
| 000004.jpg | 0 |
| 000005.jpg | 0 |
df2 = pd.read_csv('list_eval_partition.txt', sep="\s+", skiprows=0, header=None)
df2.columns = ['Filename', 'Partition']
df2 = df2.set_index('Filename')
df2.head()
| Partition | |
|---|---|
| Filename | |
| 000001.jpg | 0 |
| 000002.jpg | 0 |
| 000003.jpg | 0 |
| 000004.jpg | 0 |
| 000005.jpg | 0 |
df3 = df1.merge(df2, left_index=True, right_index=True)
df3.head()
| Male | Partition | |
|---|---|---|
| 000001.jpg | 0 | 0 |
| 000002.jpg | 0 | 0 |
| 000003.jpg | 1 | 0 |
| 000004.jpg | 0 | 0 |
| 000005.jpg | 0 | 0 |
df3.to_csv('celeba-gender-partitions.csv')
df4 = pd.read_csv('celeba-gender-partitions.csv', index_col=0)
df4.head()
| Male | Partition | |
|---|---|---|
| 000001.jpg | 0 | 0 |
| 000002.jpg | 0 | 0 |
| 000003.jpg | 1 | 0 |
| 000004.jpg | 0 | 0 |
| 000005.jpg | 0 | 0 |
df4.loc[df4['Partition'] == 0].to_csv('celeba-gender-train.csv')
df4.loc[df4['Partition'] == 1].to_csv('celeba-gender-valid.csv')
df4.loc[df4['Partition'] == 2].to_csv('celeba-gender-test.csv')
img = Image.open('img_align_celeba/000001.jpg')
print(np.asarray(img, dtype=np.uint8).shape)
plt.imshow(img);
(218, 178, 3)

Implementing a Custom DataLoader Class¶
class CelebaDataset(Dataset):
"""Custom Dataset for loading CelebA face images"""
def __init__(self, csv_path, img_dir, transform=None):
df = pd.read_csv(csv_path, index_col=0)
self.img_dir = img_dir
self.csv_path = csv_path
self.img_names = df.index.values
self.y = df['Male'].values
self.transform = transform
def __getitem__(self, index):
img = Image.open(os.path.join(self.img_dir,
self.img_names[index]))
if self.transform is not None:
img = self.transform(img)
label = self.y[index]
return img, label
def __len__(self):
return self.y.shape[0]
# Note that transforms.ToTensor()
# already divides pixels by 255. internally
custom_transform = transforms.Compose([transforms.CenterCrop((178, 178)),
transforms.Resize((128, 128)),
#transforms.Grayscale(),
#transforms.Lambda(lambda x: x/255.),
transforms.ToTensor()])
train_dataset = CelebaDataset(csv_path='celeba-gender-train.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
valid_dataset = CelebaDataset(csv_path='celeba-gender-valid.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
test_dataset = CelebaDataset(csv_path='celeba-gender-test.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4)
torch.manual_seed(0)
for epoch in range(2):
for batch_idx, (x, y) in enumerate(train_loader):
print('Epoch:', epoch+1, end='')
print(' | Batch index:', batch_idx, end='')
print(' | Batch size:', y.size()[0])
x = x.to(DEVICE)
y = y.to(DEVICE)
time.sleep(1)
break
Epoch: 1 | Batch index: 0 | Batch size: 1024 Epoch: 2 | Batch index: 0 | Batch size: 1024
Model¶
The following code cell that implements the ResNet-34 architecture is a derivative of the code provided at https://pytorch.org/docs/0.4.0/_modules/torchvision/models/resnet.html.
##########################
### MODEL
##########################
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes, grayscale):
self.inplanes = 64
if grayscale:
in_dim = 1
else:
in_dim = 3
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(in_dim, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1, padding=2)
self.fc = nn.Linear(2048 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, (2. / n)**.5)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
logits = self.fc(x)
probas = F.softmax(logits, dim=1)
return logits, probas
def resnet18(num_classes):
"""Constructs a ResNet-18 model."""
model = ResNet(block=BasicBlock,
layers=[2, 2, 2, 2],
num_classes=NUM_CLASSES,
grayscale=GRAYSCALE)
return model
torch.manual_seed(RANDOM_SEED)
##########################
### COST AND OPTIMIZER
##########################
model = resnet18(NUM_CLASSES)
#### DATA PARALLEL START ####
if torch.cuda.device_count() > 1:
print("Using", torch.cuda.device_count(), "GPUs")
model = nn.DataParallel(model)
#### DATA PARALLEL END ####
model.to(DEVICE)
cost_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
Using 4 GPUs
Training¶
def compute_accuracy(model, data_loader, device):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = cost_fn(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 50:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, NUM_EPOCHS, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%% | Valid: %.3f%%' % (
epoch+1, NUM_EPOCHS,
compute_accuracy(model, train_loader, device=DEVICE),
compute_accuracy(model, valid_loader, device=DEVICE)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
Epoch: 001/010 | Batch 0000/0159 | Cost: 0.6782 Epoch: 001/010 | Batch 0050/0159 | Cost: 0.1445 Epoch: 001/010 | Batch 0100/0159 | Cost: 0.1169 Epoch: 001/010 | Batch 0150/0159 | Cost: 0.0913 Epoch: 001/010 | Train: 93.687% | Valid: 94.101% Time elapsed: 3.83 min Epoch: 002/010 | Batch 0000/0159 | Cost: 0.0851 Epoch: 002/010 | Batch 0050/0159 | Cost: 0.0910 Epoch: 002/010 | Batch 0100/0159 | Cost: 0.0736 Epoch: 002/010 | Batch 0150/0159 | Cost: 0.0946 Epoch: 002/010 | Train: 96.940% | Valid: 97.025% Time elapsed: 7.60 min Epoch: 003/010 | Batch 0000/0159 | Cost: 0.0587 Epoch: 003/010 | Batch 0050/0159 | Cost: 0.0506 Epoch: 003/010 | Batch 0100/0159 | Cost: 0.0613 Epoch: 003/010 | Batch 0150/0159 | Cost: 0.0495 Epoch: 003/010 | Train: 98.260% | Valid: 97.896% Time elapsed: 11.39 min Epoch: 004/010 | Batch 0000/0159 | Cost: 0.0387 Epoch: 004/010 | Batch 0050/0159 | Cost: 0.0413 Epoch: 004/010 | Batch 0100/0159 | Cost: 0.0462 Epoch: 004/010 | Batch 0150/0159 | Cost: 0.0366 Epoch: 004/010 | Train: 98.561% | Valid: 97.705% Time elapsed: 15.21 min Epoch: 005/010 | Batch 0000/0159 | Cost: 0.0323 Epoch: 005/010 | Batch 0050/0159 | Cost: 0.0431 Epoch: 005/010 | Batch 0100/0159 | Cost: 0.0433 Epoch: 005/010 | Batch 0150/0159 | Cost: 0.0263 Epoch: 005/010 | Train: 98.692% | Valid: 97.715% Time elapsed: 18.99 min Epoch: 006/010 | Batch 0000/0159 | Cost: 0.0285 Epoch: 006/010 | Batch 0050/0159 | Cost: 0.0280 Epoch: 006/010 | Batch 0100/0159 | Cost: 0.0302 Epoch: 006/010 | Batch 0150/0159 | Cost: 0.0451 Epoch: 006/010 | Train: 98.880% | Valid: 97.730% Time elapsed: 22.76 min Epoch: 007/010 | Batch 0000/0159 | Cost: 0.0307 Epoch: 007/010 | Batch 0050/0159 | Cost: 0.0257 Epoch: 007/010 | Batch 0100/0159 | Cost: 0.0247 Epoch: 007/010 | Batch 0150/0159 | Cost: 0.0227 Epoch: 007/010 | Train: 99.276% | Valid: 97.966% Time elapsed: 26.55 min Epoch: 008/010 | Batch 0000/0159 | Cost: 0.0142 Epoch: 008/010 | Batch 0050/0159 | Cost: 0.0185 Epoch: 008/010 | Batch 0100/0159 | Cost: 0.0092 Epoch: 008/010 | Batch 0150/0159 | Cost: 0.0345 Epoch: 008/010 | Train: 99.536% | Valid: 97.972% Time elapsed: 30.36 min Epoch: 009/010 | Batch 0000/0159 | Cost: 0.0130 Epoch: 009/010 | Batch 0050/0159 | Cost: 0.0160 Epoch: 009/010 | Batch 0100/0159 | Cost: 0.0112 Epoch: 009/010 | Batch 0150/0159 | Cost: 0.0235 Epoch: 009/010 | Train: 99.211% | Valid: 97.926% Time elapsed: 34.16 min Epoch: 010/010 | Batch 0000/0159 | Cost: 0.0049 Epoch: 010/010 | Batch 0050/0159 | Cost: 0.0135 Epoch: 010/010 | Batch 0100/0159 | Cost: 0.0225 Epoch: 010/010 | Batch 0150/0159 | Cost: 0.0236 Epoch: 010/010 | Train: 99.520% | Valid: 97.972% Time elapsed: 37.94 min Total Training Time: 37.94 min
Evaluation¶
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))
Test accuracy: 97.38%
for batch_idx, (features, targets) in enumerate(test_loader):
features = features
targets = targets
break
plt.imshow(np.transpose(features[0], (1, 2, 0)))
<matplotlib.image.AxesImage at 0x7f9528f29da0>

model.eval()
logits, probas = model(features.to(DEVICE)[0, None])
print('Probability Female %.2f%%' % (probas[0][0]*100))
Probability Female 100.00%
%watermark -iv
numpy 1.15.4 pandas 0.23.4 torch 1.0.0 PIL.Image 5.3.0