Deep Learning Models -- A collection of various deep learning architectures, models, and tips for TensorFlow and PyTorch in Jupyter Notebooks.
- Author: Sebastian Raschka
- GitHub Repository: https://github.com/rasbt/deeplearning-models
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
Sebastian Raschka CPython 3.6.8 IPython 7.2.0 torch 1.0.0
Model Zoo -- ResNet-34 CIFAR-10 Classifier with Pinned Memory¶
This is an example notebook comparing the speed of model training with and without using page-locked memory. Page-locked memory can be enabled by setting pin_memory=True in PyTorch's DataLoader class (disabled by default).
Theoretically, pinning the memory should speed up the data transfer rate but minimizing the data transfer cost between CPU and the CUDA device; hence, enabling pin_memory=True should make the model training faster by some small margin.
Host (CPU) data allocations are pageable by default. The GPU cannot access data directly from pageable host memory, so when a data transfer from pageable host memory to device memory is invoked, the CUDA driver must first allocate a temporary page-locked, or “pinned”, host array, copy the host data to the pinned array, and then transfer the data from the pinned array to device memory, as illustrated below... (Source: https://devblogs.nvidia.com/how-optimize-data-transfers-cuda-cc/)
After the Model preamble, this Notebook is divided into too subsections, "Training Without Pinned Memory" and "Training with Pinned Memory" to investigate whether there is a noticable training time difference when toggling pin_memory on and off.
Network Architecture¶
The network in this notebook is an implementation of the ResNet-34 [1] architecture on the MNIST digits dataset (http://yann.lecun.com/exdb/mnist/) to train a handwritten digit classifier.
References
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778). (CVPR Link)

The following figure illustrates residual blocks with skip connections such that the input passed via the shortcut matches the dimensions of the main path's output, which allows the network to learn identity functions.

The ResNet-34 architecture actually uses residual blocks with skip connections such that the input passed via the shortcut matches is resized to dimensions of the main path's output. Such a residual block is illustrated below:
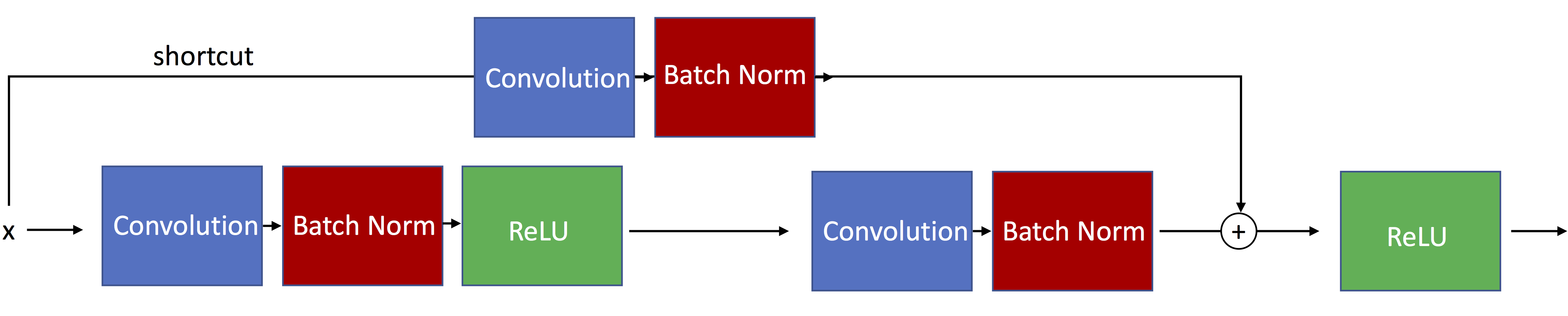
For a more detailed explanation see the other notebook, resnet-ex-1.ipynb.
Imports¶
import os
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
Model Settings¶
##########################
### SETTINGS
##########################
# Hyperparameters
RANDOM_SEED = 1
LEARNING_RATE = 0.001
BATCH_SIZE = 256
NUM_EPOCHS = 10
# Architecture
NUM_FEATURES = 28*28
NUM_CLASSES = 10
# Other
DEVICE = "cuda:1"
GRAYSCALE = False
The following code cell that implements the ResNet-34 architecture is a derivative of the code provided at https://pytorch.org/docs/0.4.0/_modules/torchvision/models/resnet.html.
##########################
### MODEL
##########################
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes, grayscale):
self.inplanes = 64
if grayscale:
in_dim = 1
else:
in_dim = 3
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(in_dim, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, (2. / n)**.5)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# because MNIST is already 1x1 here:
# disable avg pooling
#x = self.avgpool(x)
x = x.view(x.size(0), -1)
logits = self.fc(x)
probas = F.softmax(logits, dim=1)
return logits, probas
def resnet34(num_classes):
"""Constructs a ResNet-34 model."""
model = ResNet(block=BasicBlock,
layers=[3, 4, 6, 3],
num_classes=NUM_CLASSES,
grayscale=GRAYSCALE)
return model
Training without Pinned Memory¶
##########################
### CIFAR-10 Dataset
##########################
# Note transforms.ToTensor() scales input images
# to 0-1 range
train_dataset = datasets.CIFAR10(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.CIFAR10(root='data',
train=False,
transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
num_workers=8,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
num_workers=8,
shuffle=False)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
Files already downloaded and verified Image batch dimensions: torch.Size([256, 3, 32, 32]) Image label dimensions: torch.Size([256]) Image batch dimensions: torch.Size([256, 3, 32, 32]) Image label dimensions: torch.Size([256])
torch.manual_seed(RANDOM_SEED)
model = resnet34(NUM_CLASSES)
model.to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
def compute_accuracy(model, data_loader, device):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 150:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, NUM_EPOCHS, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%%' % (
epoch+1, NUM_EPOCHS,
compute_accuracy(model, train_loader, device=DEVICE)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))
print('Total Time: %.2f min' % ((time.time() - start_time)/60))
Epoch: 001/010 | Batch 0000/0196 | Cost: 2.6021 Epoch: 001/010 | Batch 0150/0196 | Cost: 1.3961 Epoch: 001/010 | Train: 45.084% Time elapsed: 0.26 min Epoch: 002/010 | Batch 0000/0196 | Cost: 1.1228 Epoch: 002/010 | Batch 0150/0196 | Cost: 1.0426 Epoch: 002/010 | Train: 56.166% Time elapsed: 0.52 min Epoch: 003/010 | Batch 0000/0196 | Cost: 0.9980 Epoch: 003/010 | Batch 0150/0196 | Cost: 0.8279 Epoch: 003/010 | Train: 66.702% Time elapsed: 0.80 min Epoch: 004/010 | Batch 0000/0196 | Cost: 0.6384 Epoch: 004/010 | Batch 0150/0196 | Cost: 0.7103 Epoch: 004/010 | Train: 65.330% Time elapsed: 1.08 min Epoch: 005/010 | Batch 0000/0196 | Cost: 0.6308 Epoch: 005/010 | Batch 0150/0196 | Cost: 0.5913 Epoch: 005/010 | Train: 79.636% Time elapsed: 1.36 min Epoch: 006/010 | Batch 0000/0196 | Cost: 0.4409 Epoch: 006/010 | Batch 0150/0196 | Cost: 0.5557 Epoch: 006/010 | Train: 76.456% Time elapsed: 1.62 min Epoch: 007/010 | Batch 0000/0196 | Cost: 0.4778 Epoch: 007/010 | Batch 0150/0196 | Cost: 0.4815 Epoch: 007/010 | Train: 65.890% Time elapsed: 1.89 min Epoch: 008/010 | Batch 0000/0196 | Cost: 0.3782 Epoch: 008/010 | Batch 0150/0196 | Cost: 0.4339 Epoch: 008/010 | Train: 85.200% Time elapsed: 2.16 min Epoch: 009/010 | Batch 0000/0196 | Cost: 0.3083 Epoch: 009/010 | Batch 0150/0196 | Cost: 0.3290 Epoch: 009/010 | Train: 78.108% Time elapsed: 2.42 min Epoch: 010/010 | Batch 0000/0196 | Cost: 0.2229 Epoch: 010/010 | Batch 0150/0196 | Cost: 0.1945 Epoch: 010/010 | Train: 87.384% Time elapsed: 2.70 min Total Training Time: 2.70 min Test accuracy: 70.67% Total Time: 2.71 min
Training with Pinned Memory¶
##########################
### CIFAR-10 Dataset
##########################
# Note transforms.ToTensor() scales input images
# to 0-1 range
train_dataset = datasets.CIFAR10(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.CIFAR10(root='data',
train=False,
transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
pin_memory=True,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
pin_memory=True,
shuffle=False)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
Files already downloaded and verified Image batch dimensions: torch.Size([256, 3, 32, 32]) Image label dimensions: torch.Size([256]) Image batch dimensions: torch.Size([256, 3, 32, 32]) Image label dimensions: torch.Size([256])
torch.manual_seed(RANDOM_SEED)
model = resnet34(NUM_CLASSES)
model.to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
def compute_accuracy(model, data_loader, device):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 150:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, NUM_EPOCHS, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%%' % (
epoch+1, NUM_EPOCHS,
compute_accuracy(model, train_loader, device=DEVICE)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))
print('Total Time: %.2f min' % ((time.time() - start_time)/60))
Epoch: 001/010 | Batch 0000/0196 | Cost: 2.6021 Epoch: 001/010 | Batch 0150/0196 | Cost: 1.3961 Epoch: 001/010 | Train: 45.084% Time elapsed: 0.39 min Epoch: 002/010 | Batch 0000/0196 | Cost: 1.1228 Epoch: 002/010 | Batch 0150/0196 | Cost: 1.0426 Epoch: 002/010 | Train: 56.166% Time elapsed: 0.77 min Epoch: 003/010 | Batch 0000/0196 | Cost: 0.9980 Epoch: 003/010 | Batch 0150/0196 | Cost: 0.8279 Epoch: 003/010 | Train: 66.702% Time elapsed: 1.16 min Epoch: 004/010 | Batch 0000/0196 | Cost: 0.6384 Epoch: 004/010 | Batch 0150/0196 | Cost: 0.7103 Epoch: 004/010 | Train: 65.330% Time elapsed: 1.55 min Epoch: 005/010 | Batch 0000/0196 | Cost: 0.6308 Epoch: 005/010 | Batch 0150/0196 | Cost: 0.5913 Epoch: 005/010 | Train: 79.636% Time elapsed: 1.94 min Epoch: 006/010 | Batch 0000/0196 | Cost: 0.4409 Epoch: 006/010 | Batch 0150/0196 | Cost: 0.5557 Epoch: 006/010 | Train: 76.456% Time elapsed: 2.33 min Epoch: 007/010 | Batch 0000/0196 | Cost: 0.4778 Epoch: 007/010 | Batch 0150/0196 | Cost: 0.4815 Epoch: 007/010 | Train: 65.890% Time elapsed: 2.71 min Epoch: 008/010 | Batch 0000/0196 | Cost: 0.3782 Epoch: 008/010 | Batch 0150/0196 | Cost: 0.4339 Epoch: 008/010 | Train: 85.200% Time elapsed: 3.10 min Epoch: 009/010 | Batch 0000/0196 | Cost: 0.3083 Epoch: 009/010 | Batch 0150/0196 | Cost: 0.3290 Epoch: 009/010 | Train: 78.108% Time elapsed: 3.49 min Epoch: 010/010 | Batch 0000/0196 | Cost: 0.2229 Epoch: 010/010 | Batch 0150/0196 | Cost: 0.1945 Epoch: 010/010 | Train: 87.384% Time elapsed: 3.88 min Total Training Time: 3.88 min Test accuracy: 70.67% Total Time: 3.91 min
Conclusions¶
Based on the training time without and with pin_memory=True, there doesn't seem to be a speed-up when using page-locked (or "pinned") memory -- in fact, pinning the memory even slowed down the training. (I reran the code in the opposite order, i.e., pin_memory=True first, and got the same results.) This could be due to the relatively small dataset size, batch size, and hardware configuration that I was using:
- Processor: Intel Xeon® Processor E5-2650 v4 (12 core)
- GPU: NVIDIA GeForce GTX 1080Ti
- Motherboard: ASUS X99-E-10G WS with PCI-E Gen3 X16 port
- Memory: 128 GB DDR4 RAM
- Storage: SSD
%watermark -iv
numpy 1.15.4 pandas 0.23.4 torch 1.0.0 PIL.Image 5.3.0