이 노트북은 farm-haystack 0.9.0, torch 1.8.1 버전이 필요하며 현재 코랩 인스턴스와 호환되지 않습니다.
이 노트북을 코랩에서 실행하려면 Pro 버전이 필요할 수 있습니다.
|
|
In [ ]:
# 코랩이나 캐글을 사용한다면 이 셀의 주석을 제거하고 실행하세요.
!git clone https://github.com/rickiepark/nlp-with-transformers.git
%cd nlp-with-transformers
from install import *
install_requirements(chapter=7)
Cloning into 'nlp-with-transformers'... remote: Enumerating objects: 563, done. remote: Counting objects: 100% (297/297), done. remote: Compressing objects: 100% (190/190), done. remote: Total 563 (delta 179), reused 184 (delta 107), pack-reused 266 Receiving objects: 100% (563/563), 48.83 MiB | 10.77 MiB/s, done. Resolving deltas: 100% (278/278), done. /content/nlp-with-transformers ⏳ Installing base requirements ... ✅ Base requirements installed! Using transformers v4.6.1 Using datasets v1.11.0 Using haystack
In [ ]:
%env TOKENIZERS_PARALLELISM=false
env: TOKENIZERS_PARALLELISM=false
In [ ]:
# haystack의 로깅을 끕니다.
import logging
for module in ["farm.utils", "farm.infer", "haystack.reader.farm.FARMReader",
"farm.modeling.prediction_head", "elasticsearch", "haystack.eval",
"haystack.document_store.base", "haystack.retriever.base",
"farm.data_handler.dataset"]:
module_logger = logging.getLogger(module)
module_logger.setLevel(logging.ERROR)
질문 답변¶
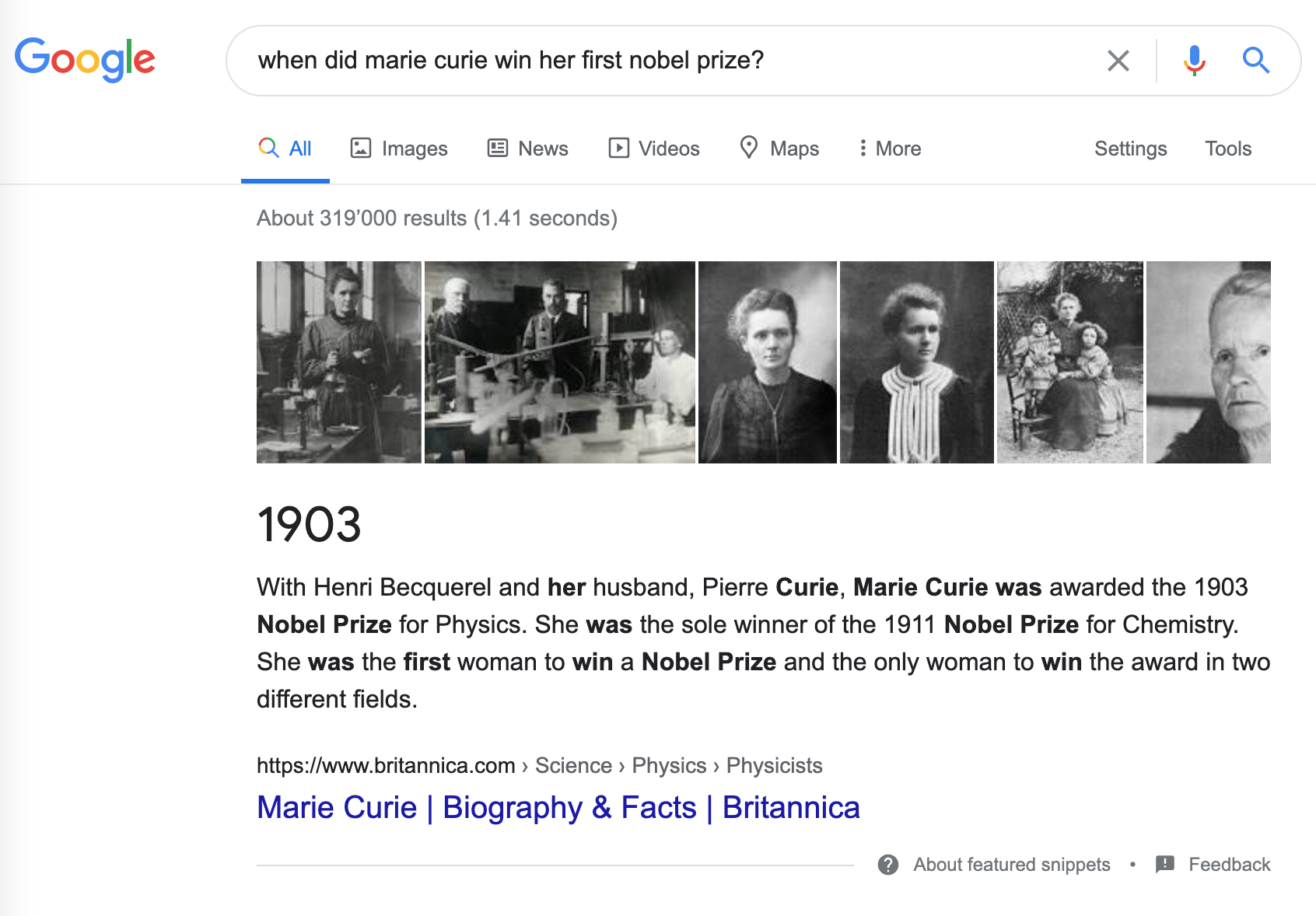
리뷰 기반 QA 시스템 구축하기¶
데이터셋¶
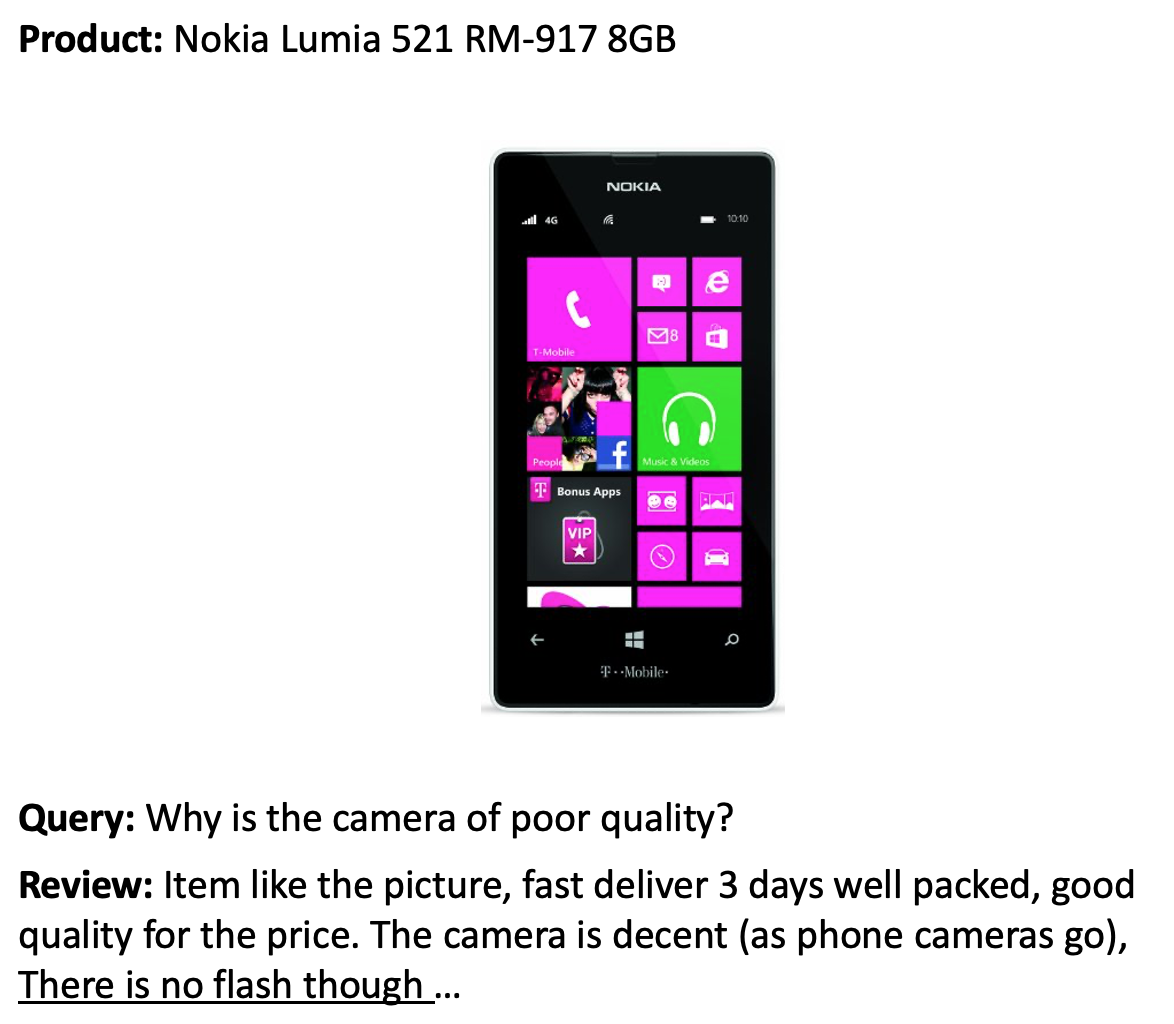
In [ ]:
from datasets import get_dataset_config_names
domains = get_dataset_config_names("subjqa")
domains
Downloading: 0%| | 0.00/2.65k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/1.46k [00:00<?, ?B/s]
Out[ ]:
['books', 'electronics', 'grocery', 'movies', 'restaurants', 'tripadvisor']
In [ ]:
from datasets import load_dataset
subjqa = load_dataset("subjqa", name="electronics")
Downloading and preparing dataset subjqa/electronics (download: 10.86 MiB, generated: 3.01 MiB, post-processed: Unknown size, total: 13.86 MiB) to /root/.cache/huggingface/datasets/subjqa/electronics/1.1.0/e5588f9298ff2d70686a00cc377e4bdccf4e32287459e3c6baf2dc5ab57fe7fd...
Downloading: 0.00B [00:00, ?B/s]
0 examples [00:00, ? examples/s]
0 examples [00:00, ? examples/s]
0 examples [00:00, ? examples/s]
Dataset subjqa downloaded and prepared to /root/.cache/huggingface/datasets/subjqa/electronics/1.1.0/e5588f9298ff2d70686a00cc377e4bdccf4e32287459e3c6baf2dc5ab57fe7fd. Subsequent calls will reuse this data.
In [ ]:
print(subjqa["train"]["answers"][1])
{'text': ['Bass is weak as expected', 'Bass is weak as expected, even with EQ
adjusted up'], 'answer_start': [1302, 1302], 'answer_subj_level': [1, 1],
'ans_subj_score': [0.5083333253860474, 0.5083333253860474], 'is_ans_subjective':
[True, True]}
In [ ]:
import pandas as pd
dfs = {split: dset.to_pandas() for split, dset in subjqa.flatten().items()}
for split, df in dfs.items():
print(f"{split}에 있는 질문 개수: {df['id'].nunique()}")
train에 있는 질문 개수: 1295 test에 있는 질문 개수: 358 validation에 있는 질문 개수: 255
In [ ]:
qa_cols = ["title", "question", "answers.text",
"answers.answer_start", "context"]
sample_df = dfs["train"][qa_cols].sample(2, random_state=7)
sample_df
Out[ ]:
| title | question | answers.text | answers.answer_start | context | |
|---|---|---|---|---|---|
| 791 | B005DKZTMG | Does the keyboard lightweight? | [this keyboard is compact] | [215] | I really like this keyboard. I give it 4 stars because it doesn't have a CA... |
| 1159 | B00AAIPT76 | How is the battery? | [] | [] | I bought this after the first spare gopro battery I bought wouldn't hold a c... |
In [ ]:
start_idx = sample_df["answers.answer_start"].iloc[0][0]
end_idx = start_idx + len(sample_df["answers.text"].iloc[0][0])
sample_df["context"].iloc[0][start_idx:end_idx]
Out[ ]:
'this keyboard is compact'
In [ ]:
counts = {}
question_types = ["What", "How", "Is", "Does", "Do", "Was", "Where", "Why"]
for q in question_types:
counts[q] = dfs["train"]["question"].str.startswith(q).value_counts()[True]
pd.Series(counts).sort_values().plot.barh()
plt.title("Frequency of Question Types")
plt.show()
In [ ]:
for question_type in ["How", "What", "Is"]:
for question in (
dfs["train"][dfs["train"].question.str.startswith(question_type)]
.sample(n=3, random_state=42)['question']):
print(question)
How is the camera? How do you like the control? How fast is the charger? What is direction? What is the quality of the construction of the bag? What is your impression of the product? Is this how zoom works? Is sound clear? Is it a wireless keyboard?
사이드바: 스탠포드 질문 답변 데이터셋¶
사이드바 끝¶
텍스트에서 답 추출하기¶
범위 분류¶
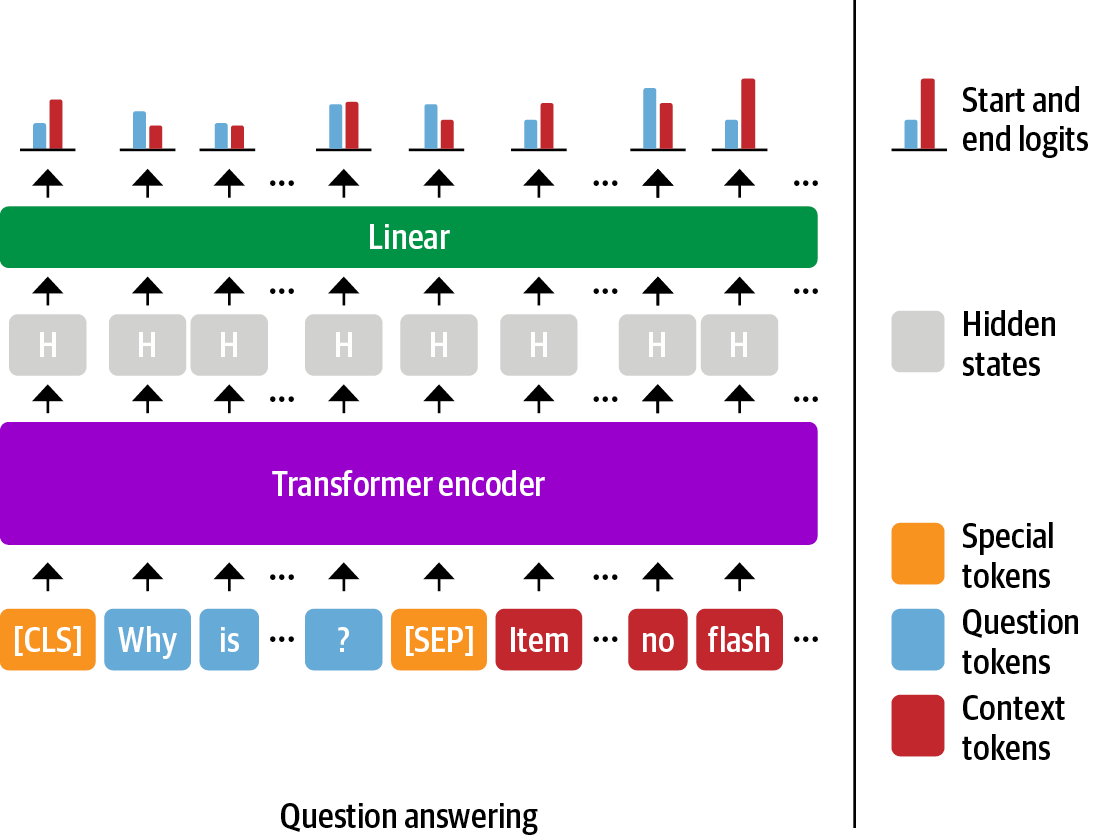
QA를 위한 텍스트 토큰화¶
In [ ]:
from transformers import AutoTokenizer
model_ckpt = "deepset/minilm-uncased-squad2"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
Downloading: 0%| | 0.00/477 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/232k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/112 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/107 [00:00<?, ?B/s]
In [ ]:
question = "How much music can this hold?"
context = """An MP3 is about 1 MB/minute, so about 6000 hours depending on \
file size."""
inputs = tokenizer(question, context, return_tensors="pt")
In [ ]:
input_df = pd.DataFrame.from_dict(tokenizer(question, context), orient="index")
input_df
Out[ ]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| input_ids | 101 | 2129 | 2172 | 2189 | 2064 | 2023 | 2907 | 1029 | 102 | 2019 | ... | 2061 | 2055 | 25961 | 2847 | 5834 | 2006 | 5371 | 2946 | 1012 | 102 |
| token_type_ids | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| attention_mask | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
3 rows × 28 columns
In [ ]:
print(tokenizer.decode(inputs["input_ids"][0]))
[CLS] how much music can this hold? [SEP] an mp3 is about 1 mb / minute, so about 6000 hours depending on file size. [SEP]
In [ ]:
import torch
from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained(model_ckpt)
with torch.no_grad():
outputs = model(**inputs)
print(outputs)
Downloading: 0%| | 0.00/133M [00:00<?, ?B/s]
QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[-0.9862, -4.7750,
-5.4025, -5.2378, -5.2863, -5.5117, -4.9819, -6.1880,
-0.9862, 0.2596, -0.2144, -1.7136, 3.7806, 4.8561, -1.0546, -3.9097,
-1.7374, -4.5944, -1.4278, 3.9949, 5.0391, -0.2018, -3.0193, -4.8549,
-2.3108, -3.5110, -3.5713, -0.9862]]), end_logits=tensor([[-0.9623,
-5.4733, -5.0326, -5.1639, -5.4278, -5.5151, -5.1749, -4.6233,
-0.9623, -3.7855, -0.8715, -3.7745, -3.0161, -1.1780, 0.1758, -2.7365,
4.8934, 0.3046, -3.1761, -3.2762, 0.8937, 5.6606, -0.3623, -4.9554,
-3.2531, -0.0914, 1.6211, -0.9623]]), hidden_states=None,
attentions=None)
In [ ]:
start_logits = outputs.start_logits
end_logits = outputs.end_logits
In [ ]:
print(f"입력 ID 크기: {inputs.input_ids.size()}")
print(f"시작 로짓 크기: {start_logits.size()}")
print(f"종료 로짓 크기: {end_logits.size()}")
입력 ID 크기: torch.Size([1, 28]) 시작 로짓 크기: torch.Size([1, 28]) 종료 로짓 크기: torch.Size([1, 28])
In [ ]:
# 시작 토큰과 종료 토큰에 대한 예측 로짓. 오렌지 색 토큰이 가장 높은 점수를 가진 토큰입니다.
# 이 그래프는 다음을 참고했습니다. https://mccormickml.com/2020/03/10/question-answering-with-a-fine-tuned-BERT
import numpy as np
import matplotlib.pyplot as plt
s_scores = start_logits.detach().numpy().flatten()
e_scores = end_logits.detach().numpy().flatten()
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
fig, (ax1, ax2) = plt.subplots(nrows=2, sharex=True)
colors = ["C0" if s != np.max(s_scores) else "C1" for s in s_scores]
ax1.bar(x=tokens, height=s_scores, color=colors)
ax1.set_ylabel("Start Scores")
colors = ["C0" if s != np.max(e_scores) else "C1" for s in e_scores]
ax2.bar(x=tokens, height=e_scores, color=colors)
ax2.set_ylabel("End Scores")
plt.xticks(rotation="vertical")
plt.show()
In [ ]:
import torch
start_idx = torch.argmax(start_logits)
end_idx = torch.argmax(end_logits) + 1
answer_span = inputs["input_ids"][0][start_idx:end_idx]
answer = tokenizer.decode(answer_span)
print(f"질문: {question}")
print(f"답변: {answer}")
질문: How much music can this hold? 답변: 6000 hours
In [ ]:
from transformers import pipeline
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer)
pipe(question=question, context=context, topk=3)
/usr/local/lib/python3.8/dist-packages/transformers/pipelines/question_answering.py:316: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:230.)
fw_args = {k: torch.tensor(v, device=self.device) for (k, v) in fw_args.items()}
Out[ ]:
[{'score': 0.26516157388687134,
'start': 38,
'end': 48,
'answer': '6000 hours'},
{'score': 0.220829576253891,
'start': 16,
'end': 48,
'answer': '1 MB/minute, so about 6000 hours'},
{'score': 0.102535180747509, 'start': 16, 'end': 27, 'answer': '1 MB/minute'}]
In [ ]:
pipe(question="Why is there no data?", context=context,
handle_impossible_answer=True)
Out[ ]:
{'score': 0.9068412780761719, 'start': 0, 'end': 0, 'answer': ''}
긴 텍스트 다루기¶
In [ ]:
# SubjQA 훈련 세트에 있는 질문-문맥 쌍의 토큰 분포
def compute_input_length(row):
inputs = tokenizer(row["question"], row["context"])
return len(inputs["input_ids"])
dfs["train"]["n_tokens"] = dfs["train"].apply(compute_input_length, axis=1)
fig, ax = plt.subplots()
dfs["train"]["n_tokens"].hist(bins=100, grid=False, ec="C0", ax=ax)
plt.xlabel("Number of tokens in question-context pair")
ax.axvline(x=512, ymin=0, ymax=1, linestyle="--", color="C1",
label="Maximum sequence length")
plt.legend()
plt.ylabel("Count")
plt.show()
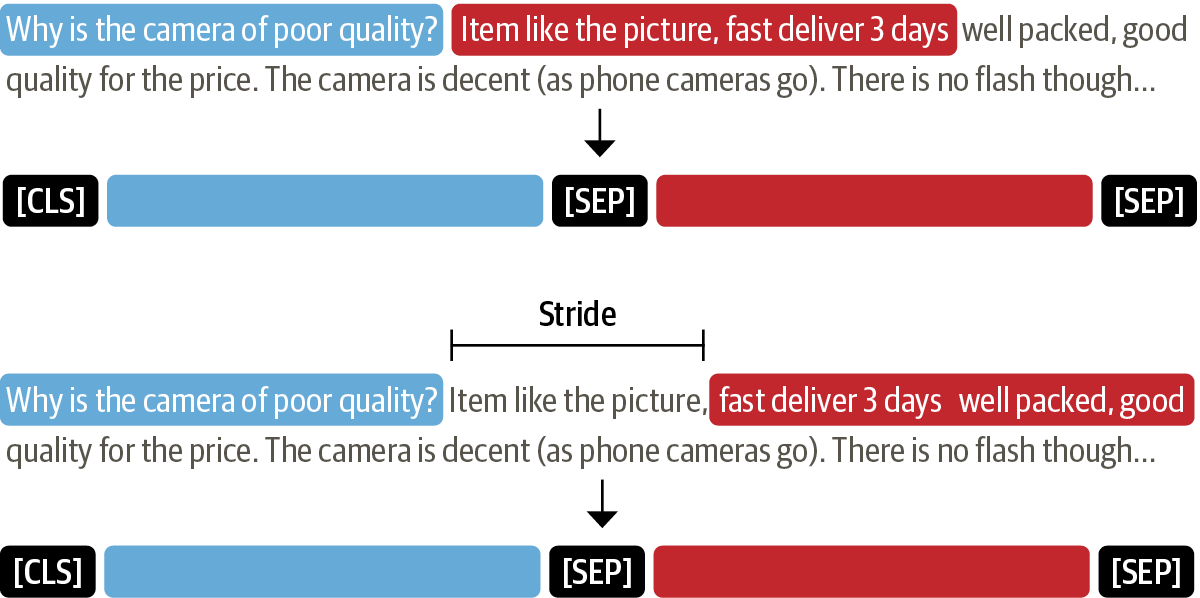
In [ ]:
example = dfs["train"].iloc[0][["question", "context"]]
tokenized_example = tokenizer(example["question"], example["context"],
return_overflowing_tokens=True, max_length=100,
stride=25)
In [ ]:
for idx, window in enumerate(tokenized_example["input_ids"]):
print(f"#{idx} 윈도에는 {len(window)}개의 토큰이 있습니다.")
#0 윈도에는 100개의 토큰이 있습니다. #1 윈도에는 88개의 토큰이 있습니다.
In [ ]:
for window in tokenized_example["input_ids"]:
print(f"{tokenizer.decode(window)} \n")
[CLS] how is the bass? [SEP] i have had koss headphones in the past, pro 4aa and qz - 99. the koss portapro is portable and has great bass response. the work great with my android phone and can be " rolled up " to be carried in my motorcycle jacket or computer bag without getting crunched. they are very light and don't feel heavy or bear down on your ears even after listening to music with them on all day. the sound is [SEP] [CLS] how is the bass? [SEP] and don't feel heavy or bear down on your ears even after listening to music with them on all day. the sound is night and day better than any ear - bud could be and are almost as good as the pro 4aa. they are " open air " headphones so you cannot match the bass to the sealed types, but it comes close. for $ 32, you cannot go wrong. [SEP]
헤이스택을 사용해 QA 파이프라인 구축하기¶
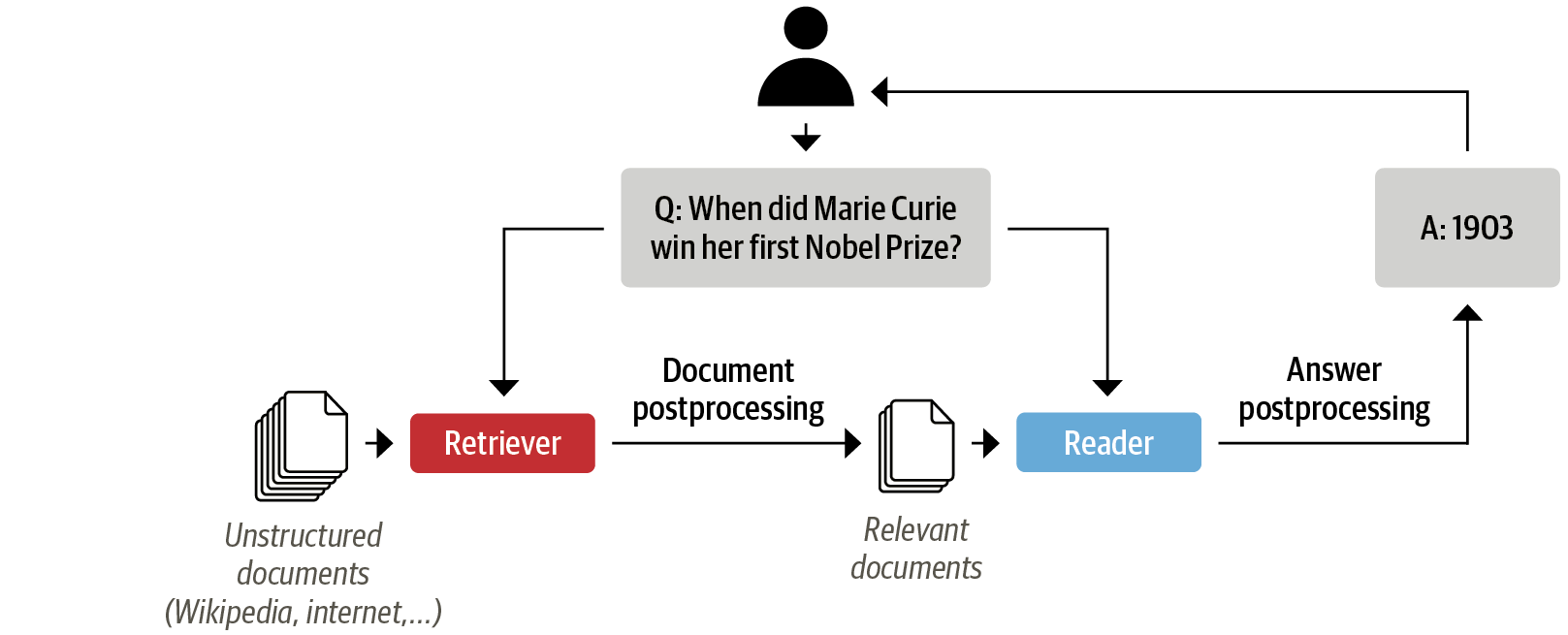
문서 저장소 초기화하기¶
In [ ]:
url = """https://artifacts.elastic.co/downloads/elasticsearch/\
elasticsearch-7.9.3-linux-x86_64.tar.gz"""
!wget -nc -q {url}
!tar -xzf elasticsearch-7.9.3-linux-x86_64.tar.gz
In [ ]:
import os
from subprocess import Popen, PIPE, STDOUT
# 백그라운드 프로세스로 일래스틱서치를 실행합니다
!chown -R daemon:daemon elasticsearch-7.9.3
es_server = Popen(args=['elasticsearch-7.9.3/bin/elasticsearch'],
stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1))
# 일래스틱서치가 시작할 때까지 기다립니다
!sleep 30
In [ ]:
# 또는 도커가 설치되어 있다면
from haystack.utils import launch_es
launch_es()
WARNING:haystack.utils:Tried to start Elasticsearch through Docker but this failed. It is likely that there is already an existing Elasticsearch instance running.
In [ ]:
!curl -X GET "localhost:9200/?pretty"
{
"name" : "5e41be2d74e7",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "OG6mo2jGQWmDRmm-VOOAHA",
"version" : {
"number" : "7.9.3",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868",
"build_date" : "2020-10-16T10:36:16.141335Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
In [ ]:
from haystack.document_store.elasticsearch import ElasticsearchDocumentStore
# 밀집 리트리버에서 사용할 문서 임베딩을 반환합니다.
document_store = ElasticsearchDocumentStore(return_embedding=True)
In [ ]:
# 노트북을 다시 시작할 때 일래스틱서치 저장소를 모두 비우는 것이 좋습니다.
if len(document_store.get_all_documents()) or len(document_store.get_all_labels()) > 0:
document_store.delete_documents("document")
document_store.delete_documents("label")
In [ ]:
for split, df in dfs.items():
# 중복 리뷰를 제외시킵니다
docs = [{"text": row["context"],
"meta":{"item_id": row["title"], "question_id": row["id"],
"split": split}}
for _,row in df.drop_duplicates(subset="context").iterrows()]
document_store.write_documents(docs, index="document")
print(f"{document_store.get_document_count()}개 문서가 저장되었습니다")
1615개 문서가 저장되었습니다
리트리버 초기화하기¶
In [ ]:
from haystack.retriever.sparse import ElasticsearchRetriever
es_retriever = ElasticsearchRetriever(document_store=document_store)
In [ ]:
item_id = "B0074BW614"
query = "Is it good for reading?"
retrieved_docs = es_retriever.retrieve(
query=query, top_k=3, filters={"item_id":[item_id], "split":["train"]})
In [ ]:
print(retrieved_docs[0])
{'text': 'This is a gift to myself. I have been a kindle user for 4 years and
this is my third one. I never thought I would want a fire for I mainly use it
for book reading. I decided to try the fire for when I travel I take my laptop,
my phone and my iPod classic. I love my iPod but watching movies on the plane
with it can be challenging because it is so small. Laptops battery life is not
as good as the Kindle. So the Fire combines for me what I needed all three to
do. So far so good.', 'score': 6.243799, 'probability': 0.6857824513476455,
'question': None, 'meta': {'item_id': 'B0074BW614', 'question_id':
'868e311275e26dbafe5af70774a300f3', 'split': 'train'}, 'embedding': None, 'id':
'252e83e25d52df7311d597dc89eef9f6'}
리더 초기화하기¶
In [ ]:
from haystack.reader.farm import FARMReader
model_ckpt = "deepset/minilm-uncased-squad2"
max_seq_length, doc_stride = 384, 128
reader = FARMReader(model_name_or_path=model_ckpt, progress_bar=False,
max_seq_len=max_seq_length, doc_stride=doc_stride,
return_no_answer=True)
In [ ]:
print(reader.predict_on_texts(question=question, texts=[context], top_k=1))
{'query': 'How much music can this hold?', 'no_ans_gap': 12.64809501171112,
'answers': [{'answer': '6000 hours', 'score': 10.699626922607422, 'probability':
0.3988155424594879, 'context': 'An MP3 is about 1 MB/minute, so about 6000 hours
depending on file size.', 'offset_start': 38, 'offset_end': 48,
'offset_start_in_doc': 38, 'offset_end_in_doc': 48, 'document_id':
'e344757014e804eff50faa3ecf1c9c75'}]}
모두 합치기¶
In [ ]:
from haystack.pipeline import ExtractiveQAPipeline
pipe = ExtractiveQAPipeline(reader, es_retriever)
In [ ]:
n_answers = 3
preds = pipe.run(query=query, top_k_retriever=3, top_k_reader=n_answers,
filters={"item_id": [item_id], "split":["train"]})
print(f"질문: {preds['query']} \n")
for idx in range(n_answers):
print(f"답변 {idx+1}: {preds['answers'][idx]['answer']}")
print(f"해당 리뷰 텍스트: ...{preds['answers'][idx]['context']}...")
print("\n\n")
질문: Is it good for reading? 답변 1: I mainly use it for book reading 해당 리뷰 텍스트: ... is my third one. I never thought I would want a fire for I mainly use it for book reading. I decided to try the fire for when I travel I take my la... 답변 2: the larger screen compared to the Kindle makes for easier reading 해당 리뷰 텍스트: ...ght enough that I can hold it to read, but the larger screen compared to the Kindle makes for easier reading. I love the color, something I never thou... 답변 3: it is great for reading books when no light is available 해당 리뷰 텍스트: ...ecoming addicted to hers! Our son LOVES it and it is great for reading books when no light is available. Amazing sound but I suggest good headphones t...
QA 파이프라인 개선하기¶
리트리버 평가하기¶
In [ ]:
from haystack.pipeline import Pipeline
from haystack.eval import EvalDocuments
class EvalRetrieverPipeline:
def __init__(self, retriever):
self.retriever = retriever
self.eval_retriever = EvalDocuments()
pipe = Pipeline()
pipe.add_node(component=self.retriever, name="ESRetriever",
inputs=["Query"])
pipe.add_node(component=self.eval_retriever, name="EvalRetriever",
inputs=["ESRetriever"])
self.pipeline = pipe
pipe = EvalRetrieverPipeline(es_retriever)
In [ ]:
from haystack import Label
labels = []
for i, row in dfs["test"].iterrows():
# 리트리버에서 필터링을 위해 사용하는 메타데이터
meta = {"item_id": row["title"], "question_id": row["id"]}
# 답이 있는 질문을 레이블에 추가합니다
if len(row["answers.text"]):
for answer in row["answers.text"]:
label = Label(
question=row["question"], answer=answer, id=i, origin=row["id"],
meta=meta, is_correct_answer=True, is_correct_document=True,
no_answer=False)
labels.append(label)
# 답이 없는 질문을 레이블에 추가합니다
else:
label = Label(
question=row["question"], answer="", id=i, origin=row["id"],
meta=meta, is_correct_answer=True, is_correct_document=True,
no_answer=True)
labels.append(label)
In [ ]:
print(labels[0])
{'id': '336690e2-4398-4ba8-9744-b6363b373427', 'created_at': None, 'updated_at':
None, 'question': 'What is the tonal balance of these headphones?', 'answer': 'I
have been a headphone fanatic for thirty years', 'is_correct_answer': True,
'is_correct_document': True, 'origin': 'd0781d13200014aa25860e44da9d5ea7',
'document_id': None, 'offset_start_in_doc': None, 'no_answer': False,
'model_id': None, 'meta': {'item_id': 'B00001WRSJ', 'question_id':
'd0781d13200014aa25860e44da9d5ea7'}}
In [ ]:
document_store.write_labels(labels, index="label")
print(f"""{document_store.get_label_count(index="label")}개의 \
질문 답변 쌍을 로드했습니다.""")
358개의 질문 답변 쌍을 로드했습니다.
In [ ]:
labels_agg = document_store.get_all_labels_aggregated(
index="label",
open_domain=True,
aggregate_by_meta=["item_id"]
)
print(len(labels_agg))
330
In [ ]:
def run_pipeline(pipeline, top_k_retriever=10, top_k_reader=4):
for l in labels_agg:
_ = pipeline.pipeline.run(
query=l.question,
top_k_retriever=top_k_retriever,
top_k_reader=top_k_reader,
top_k_eval_documents=top_k_retriever,
labels=l,
filters={"item_id": [l.meta["item_id"]], "split": ["test"]})
In [ ]:
run_pipeline(pipe, top_k_retriever=3)
print(f"재현율@3: {pipe.eval_retriever.recall:.2f}")
재현율@3: 0.95
In [ ]:
def evaluate_retriever(retriever, topk_values = [1,3,5,10,20]):
topk_results = {}
for topk in topk_values:
# 파이프라인을 만듭니다
p = EvalRetrieverPipeline(retriever)
# 테스트 세트에 있는 질문-답변 쌍을 반복합니다
run_pipeline(p, top_k_retriever=topk)
# 재현율을 저장합니다
topk_results[topk] = {"recall": p.eval_retriever.recall}
return pd.DataFrame.from_dict(topk_results, orient="index")
es_topk_df = evaluate_retriever(es_retriever)
In [ ]:
def plot_retriever_eval(dfs, retriever_names):
fig, ax = plt.subplots()
for df, retriever_name in zip(dfs, retriever_names):
df.plot(y="recall", ax=ax, label=retriever_name)
plt.xticks(df.index)
plt.ylabel("Top-k Recall")
plt.xlabel("k")
plt.show()
plot_retriever_eval([es_topk_df], ["BM25"])
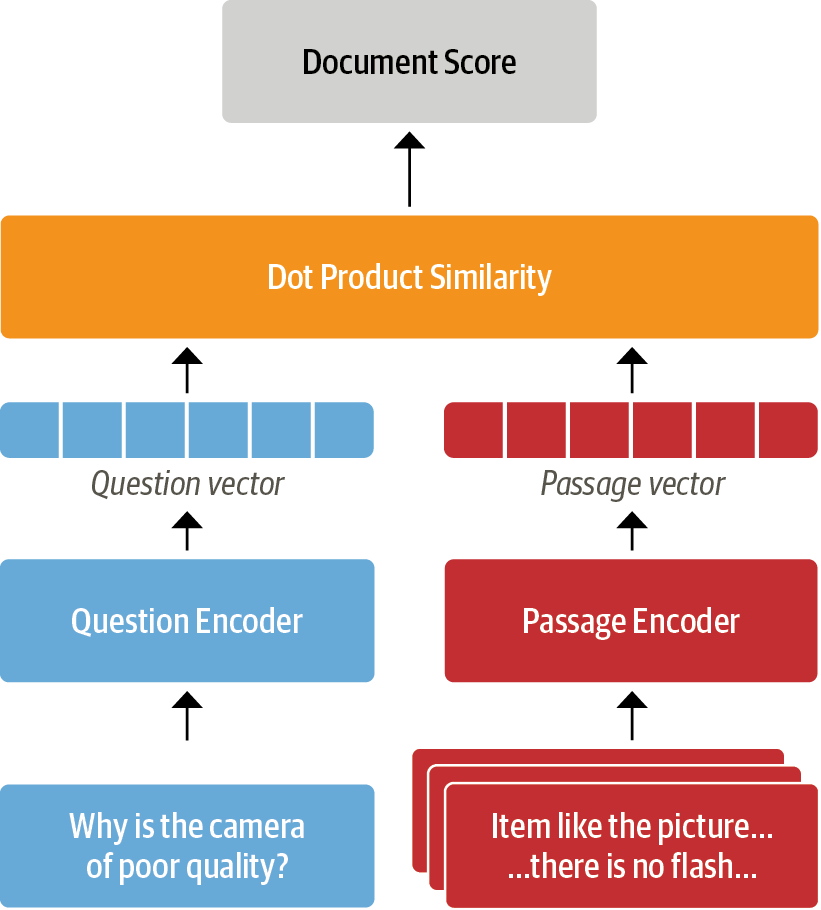
DPR¶
In [ ]:
from haystack.retriever.dense import DensePassageRetriever
dpr_retriever = DensePassageRetriever(document_store=document_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
embed_title=False)
Downloading: 0%| | 0.00/232k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/466k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/28.0 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/493 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/438M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/232k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/466k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/28.0 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/492 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/438M [00:00<?, ?B/s]
In [ ]:
document_store.update_embeddings(retriever=dpr_retriever)
Updating embeddings: 0%| | 0/1615 [00:00<?, ? Docs/s]
Create embeddings: 0%| | 0/1616 [00:00<?, ? Docs/s]
In [ ]:
dpr_topk_df = evaluate_retriever(dpr_retriever)
plot_retriever_eval([es_topk_df, dpr_topk_df], ["BM25", "DPR"])
리더 평가하기¶
In [ ]:
from farm.evaluation.squad_evaluation import compute_f1, compute_exact
pred = "about 6000 hours"
label = "6000 hours"
print(f"EM: {compute_exact(label, pred)}")
print(f"F1: {compute_f1(label, pred)}")
EM: 0 F1: 0.8
In [ ]:
pred = "about 6000 dollars"
print(f"EM: {compute_exact(label, pred)}")
print(f"F1: {compute_f1(label, pred)}")
EM: 0 F1: 0.4
In [ ]:
from time import sleep
from haystack.eval import EvalAnswers
def evaluate_reader(reader):
score_keys = ['top_1_em', 'top_1_f1']
eval_reader = EvalAnswers(skip_incorrect_retrieval=False)
pipe = Pipeline()
pipe.add_node(component=reader, name="QAReader", inputs=["Query"])
pipe.add_node(component=eval_reader, name="EvalReader", inputs=["QAReader"])
i = 0
for l in labels_agg:
doc = document_store.query(l.question,
filters={"question_id":[l.origin]})
_ = pipe.run(query=l.question, documents=doc, labels=l)
i += 1
sleep(0.01) # 쿼리 속도를 조절하기 위해
return {k:v for k,v in eval_reader.__dict__.items() if k in score_keys}
reader_eval = {}
reader_eval["Fine-tune on SQuAD"] = evaluate_reader(reader)
In [ ]:
def plot_reader_eval(reader_eval):
fig, ax = plt.subplots()
df = pd.DataFrame.from_dict(reader_eval)
df.plot(kind="bar", ylabel="Score", rot=0, ax=ax)
ax.set_xticklabels(["EM", "F1"])
plt.legend(loc='upper left')
plt.show()
plot_reader_eval(reader_eval)
도메인 적응¶
In [ ]:
def create_paragraphs(df):
paragraphs = []
id2context = dict(zip(df["review_id"], df["context"]))
for review_id, review in id2context.items():
qas = []
# Filter for all question-answer pairs about a specific context
review_df = df.query(f"review_id == '{review_id}'")
id2question = dict(zip(review_df["id"], review_df["question"]))
# Build up the qas array
for qid, question in id2question.items():
# 하나의 질문 ID에 대해 필터링합니다
question_df = df.query(f"id == '{qid}'").to_dict(orient="list")
ans_start_idxs = question_df["answers.answer_start"][0].tolist()
ans_text = question_df["answers.text"][0].tolist()
# 답변 가능한 질문을 추가합니다
if len(ans_start_idxs):
answers = [
{"text": text, "answer_start": answer_start}
for text, answer_start in zip(ans_text, ans_start_idxs)]
is_impossible = False
else:
answers = []
is_impossible = True
# 질문-답 쌍을 qas에 추가합니다
qas.append({"question": question, "id": qid,
"is_impossible": is_impossible, "answers": answers})
# 문맥과 질문-답 쌍을 paragraphs에 추가합니다
paragraphs.append({"qas": qas, "context": review})
return paragraphs
In [ ]:
product = dfs["train"].query("title == 'B00001P4ZH'")
create_paragraphs(product)
Out[ ]:
[{'qas': [{'question': 'How is the bass?',
'id': '2543d296da9766d8d17d040ecc781699',
'is_impossible': True,
'answers': []}],
'context': 'I have had Koss headphones in the past, Pro 4AA and QZ-99. The Koss Portapro is portable AND has great bass response. The work great with my Android phone and can be "rolled up" to be carried in my motorcycle jacket or computer bag without getting crunched. They are very light and do not feel heavy or bear down on your ears even after listening to music with them on all day. The sound is night and day better than any ear-bud could be and are almost as good as the Pro 4AA. They are "open air" headphones so you cannot match the bass to the sealed types, but it comes close. For $32, you cannot go wrong.'},
{'qas': [{'question': 'Is this music song have a goo bass?',
'id': 'd476830bf9282e2b9033e2bb44bbb995',
'is_impossible': False,
'answers': [{'text': 'Bass is weak as expected', 'answer_start': 1302},
{'text': 'Bass is weak as expected, even with EQ adjusted up',
'answer_start': 1302}]}],
'context': 'To anyone who hasn\'t tried all the various types of headphones, it is important to remember exactly what these are: cheap portable on-ear headphones. They give a totally different sound then in-ears or closed design phones, but for what they are I would say they\'re good. I currently own six pairs of phones, from stock apple earbuds to Sennheiser HD 518s. Gave my Portapros a run on both my computer\'s sound card and mp3 player, using 256 kbps mp3s or better. The clarity is good and they\'re very lightweight. The folding design is simple but effective. The look is certainly retro and unique, although I didn\'t find it as comfortable as many have claimed. Earpads are *very* thin and made my ears sore after 30 minutes of listening, although this can be remedied to a point by adjusting the "comfort zone" feature (tightening the temple pads while loosening the ear pads). The cord seems to be an average thickness, but I wouldn\'t get too rough with these. The steel headband adjusts smoothly and easily, just watch out that the slider doesn\'t catch your hair. Despite the sore ears, the phones are very lightweight overall.Back to the sound: as you would expect, it\'s good for a portable phone, but hardly earth shattering. At flat EQ the clarity is good, although the highs can sometimes be harsh. Bass is weak as expected, even with EQ adjusted up. To be fair, a portable on-ear would have a tough time comparing to the bass of an in-ear with a good seal or a pair with larger drivers. No sound isolation offered if you\'re into that sort of thing. Cool 80s phones, though I\'ve certainly owned better portable on-ears (Sony makes excellent phones in this category). Soundstage is very narrow and lacks body. A good value if you can get them for under thirty, otherwise I\'d rather invest in a nicer pair of phones. If we\'re talking about value, they\'re a good buy compared to new stock apple buds. If you\'re trying to compare the sound quality of this product to serious headphones, there\'s really no comparison at all.Update: After 100 hours of burn-in time the sound has not been affected in any appreciable way. Highs are still harsh, and bass is still underwhelming. I sometimes use these as a convenience but they have been largely replaced in my collection.'},
{'qas': [{'question': 'How is the bass?',
'id': '455575557886d6dfeea5aa19577e5de4',
'is_impossible': False,
'answers': [{'text': 'The only fault in the sound is the bass',
'answer_start': 650}]}],
'context': "I have had many sub-$100 headphones from $5 Panasonic to $100 Sony, with Sennheiser HD 433, 202, PX100 II (I really wanted to like these PX100-II, they were so very well designed), and even a Grado SR60 for awhile. And what it basically comes down to is value. I have never heard sound as good as these headphones in the $35 range, easily the best under $75. I can't believe they're over 25 years old.It's hard to describe how much detail these headphones bring out without making it too harsh or dull. I listen to every type of music from classical to hip hop to electronic to country, and these headphones are suitable for all types of music. The only fault in the sound is the bass. It's just a *slight* bit boomy, but you get to like it after a while to be honest.The design is from the 80s as you all have probably figured out. It could use a update but it seems like Koss has tried to perfect this formula and failed in the past. I don't really care about the looks or the way it folds up or the fact that my hair gets caught up in it (I have very short hair, even for a male).But despite it's design flaws, it's the most comfortable headphones I have ever worn, and the best part is that it's also the best sounding pair of headphones I have ever heard under $75.If you can get over the design flaws or if sound is the most important feature of headphones for you, there is nothing even close to this at this price range.This one is an absolute GEM. I loved these so much I ordered two of the 25th Anniversary ones for a bit more.Update: I read some reviews about the PX100-II being much improved and better sounding than the PortaPro. Since the PX100-II is relatively new, I thought I'd give it another listen. This time I noticed something different. The sound is warm, mellow, and neutral, but it loses a lot of detail at the expense of these attributes. I still prefer higher-detail Portapro, but some may prefer the more mellow sound of the PX100-II.Oh by the way the Portapro comes in the straight plug now, not the angled plug anymore. It's supposed to be for better compatibility with the iPods and iPhones out there."}]
[{'qas': [{'question': 'How is the bass?',
'id': '2543d296da9766d8d17d040ecc781699',
'is_impossible': True,
'answers': []}],
'context': 'I have had Koss headphones ...',
'id': 'd476830bf9282e2b9033e2bb44bbb995',
'is_impossible': False,
'answers': [{'text': 'Bass is weak as expected', 'answer_start': 1302},
{'text': 'Bass is weak as expected, even with EQ adjusted up',
'answer_start': 1302}]}],
'context': 'To anyone who hasn\'t tried all ...'},
{'qas': [{'question': 'How is the bass?',
'id': '455575557886d6dfeea5aa19577e5de4',
'is_impossible': False,
'answers': [{'text': 'The only fault in the sound is the bass',
'answer_start': 650}]}],
'context': "I have had many sub-$100 headphones ..."}]
In [ ]:
import json
def convert_to_squad(dfs):
for split, df in dfs.items():
subjqa_data = {}
# 각 제품 ID에 대해 `paragraphs`를 만듭니다
groups = (df.groupby("title").apply(create_paragraphs)
.to_frame(name="paragraphs").reset_index())
subjqa_data["data"] = groups.to_dict(orient="records")
# 결과를 디스크에 저장합니다
with open(f"electronics-{split}.json", "w+", encoding="utf-8") as f:
json.dump(subjqa_data, f)
convert_to_squad(dfs)
In [ ]:
train_filename = "electronics-train.json"
dev_filename = "electronics-validation.json"
# 코랩의 응답성을 높이기 위해 num_processes=1로 설정
reader.train(data_dir=".", use_gpu=True, n_epochs=1, batch_size=16,
train_filename=train_filename, dev_filename=dev_filename,
num_processes=1)
Preprocessing Dataset electronics-train.json: 0%| | 0/1265 [00:00<?, ? Dicts/s]WARNING:farm.data_handler.processor:Answer using start/end indices is ' Operation of the menus and contro' while gold label text is 'Operation of the menus and controls'.
Example will not be converted for training/evaluation.
WARNING:farm.data_handler.processor:Answer using start/end indices is ' This camera performs like the pros. Fast accurate and easy to operat' while gold label text is 'This camera performs like the pros. Fast accurate and easy to operated'.
Example will not be converted for training/evaluation.
Preprocessing Dataset electronics-train.json: 20%|██ | 253/1265 [00:02<00:09, 109.96 Dicts/s]
ERROR:farm.data_handler.processor:Unable to convert 2 samples to features. Their ids are : 595-0-0, 572-0-0
Preprocessing Dataset electronics-validation.json: 20%|██ | 51/252 [00:00<00:01, 132.31 Dicts/s]
ERROR:farm.data_handler.processor:Unable to convert 2 samples to features. Their ids are : 595-0-0, 572-0-0
INFO:farm.modeling.optimization:Loading optimizer `TransformersAdamW`: '{'correct_bias': False, 'weight_decay': 0.01, 'lr': 1e-05}'
INFO:farm.modeling.optimization:Using scheduler 'get_linear_schedule_with_warmup'
INFO:farm.modeling.optimization:Loading schedule `get_linear_schedule_with_warmup`: '{'num_training_steps': 164, 'num_warmup_steps': 32}'
In [ ]:
reader_eval["Fine-tune on SQuAD + SubjQA"] = evaluate_reader(reader)
plot_reader_eval(reader_eval)
In [ ]:
minilm_ckpt = "microsoft/MiniLM-L12-H384-uncased"
minilm_reader = FARMReader(model_name_or_path=minilm_ckpt, progress_bar=False,
max_seq_len=max_seq_length, doc_stride=doc_stride,
return_no_answer=True)
Downloading: 0%| | 0.00/385 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/133M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/232k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/112 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/2.00 [00:00<?, ?B/s]
In [ ]:
minilm_reader.train(data_dir=".", use_gpu=True, n_epochs=1, batch_size=16,
train_filename=train_filename, dev_filename=dev_filename)
Preprocessing Dataset electronics-train.json: 0%| | 0/1265 [00:00<?, ? Dicts/s]WARNING:farm.data_handler.processor:Answer using start/end indices is ' Operation of the menus and contro' while gold label text is 'Operation of the menus and controls'.
Example will not be converted for training/evaluation.
WARNING:farm.data_handler.processor:Answer using start/end indices is ' This camera performs like the pros. Fast accurate and easy to operat' while gold label text is 'This camera performs like the pros. Fast accurate and easy to operated'.
Example will not be converted for training/evaluation.
Preprocessing Dataset electronics-train.json: 20%|██ | 253/1265 [00:02<00:08, 120.85 Dicts/s]
ERROR:farm.data_handler.processor:Unable to convert 2 samples to features. Their ids are : 595-0-0, 572-0-0
Preprocessing Dataset electronics-validation.json: 20%|██ | 51/252 [00:00<00:01, 137.68 Dicts/s]
ERROR:farm.data_handler.processor:Unable to convert 2 samples to features. Their ids are : 595-0-0, 572-0-0
INFO:farm.modeling.optimization:Loading optimizer `TransformersAdamW`: '{'correct_bias': False, 'weight_decay': 0.01, 'lr': 1e-05}'
INFO:farm.modeling.optimization:Using scheduler 'get_linear_schedule_with_warmup'
INFO:farm.modeling.optimization:Loading schedule `get_linear_schedule_with_warmup`: '{'num_training_steps': 164, 'num_warmup_steps': 32}'
In [ ]:
reader_eval["Fine-tune on SubjQA"] = evaluate_reader(minilm_reader)
plot_reader_eval(reader_eval)
전체 QA 파이프라인 평가하기¶
In [ ]:
# 리트리버 파이프라인을 초기화합니다
pipe = EvalRetrieverPipeline(es_retriever)
# 리더 관련 노드를 추가합니다
eval_reader = EvalAnswers()
pipe.pipeline.add_node(component=reader, name="QAReader",
inputs=["EvalRetriever"])
pipe.pipeline.add_node(component=eval_reader, name="EvalReader",
inputs=["QAReader"])
# 평가합니다!
run_pipeline(pipe)
# 리더에서 결과를 추출합니다
reader_eval["QA Pipeline (top-1)"] = {
k:v for k,v in eval_reader.__dict__.items()
if k in ["top_1_em", "top_1_f1"]}
In [ ]:
# 리더와 전체 QA 파이프라인의 EM과 F1-점수 비교
plot_reader_eval({"Reader": reader_eval["Fine-tune on SQuAD + SubjQA"],
"QA pipeline (top-1)": reader_eval["QA Pipeline (top-1)"]})
추출적 QA를 넘어서¶
In [ ]:
from haystack.generator.transformers import RAGenerator
generator = RAGenerator(model_name_or_path="facebook/rag-token-nq",
embed_title=False, num_beams=5)
Downloading: 0%| | 0.00/4.60k [00:00<?, ?B/s]
/usr/local/lib/python3.8/dist-packages/transformers/models/bart/configuration_bart.py:177: UserWarning: Please make sure the config includes `forced_bos_token_id=0` in future versions.The config can simply be saved and uploaded again to be fixed. warnings.warn(
Downloading: 0%| | 0.00/232k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/112 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/48.0 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/899k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/456k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/772 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/26.0 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/2.06G [00:00<?, ?B/s]
In [ ]:
from haystack.pipeline import GenerativeQAPipeline
pipe = GenerativeQAPipeline(generator=generator, retriever=dpr_retriever)
In [ ]:
def generate_answers(query, top_k_generator=3):
preds = pipe.run(query=query, top_k_generator=top_k_generator,
top_k_retriever=5, filters={"item_id":["B0074BW614"]})
print(f"질문: {preds['query']} \n")
for idx in range(top_k_generator):
print(f"답변 {idx+1}: {preds['answers'][idx]['answer']}")
In [ ]:
generate_answers(query)
/usr/local/lib/python3.8/dist-packages/transformers/models/rag/tokenization_rag.py:92: FutureWarning: `prepare_seq2seq_batch` is deprecated and will be removed in version 5 of 🤗 Transformers. Use the regular `__call__` method to prepare your inputs and the tokenizer under the `with_target_tokenizer` context manager to prepare your targets. See the documentation of your specific tokenizer for more details warnings.warn( /usr/local/lib/python3.8/dist-packages/transformers/generation_utils.py:1712: UserWarning: `max_length` is deprecated in this function, use `stopping_criteria=StoppingCriteriaList(MaxLengthCriteria(max_length=max_length))` instead. warnings.warn(
질문: Is it good for reading? 답변 1: the screen is absolutely beautiful 답변 2: the Screen is absolutely beautiful 답변 3: Kindle fire
In [ ]:
generate_answers("What is the main drawback?")
질문: What is the main drawback? 답변 1: the price 답변 2: no flash support 답변 3: the cost
결론¶
