Project Report : Collaborative Filtering Based Book Recommendation Engine
Abstract
This capstone project is a part of the data science career track program at Springboard. The primary goal of this project is to develop a collaborative book recommendation model using goodreads dataset that can suggest readers what books to read next. EDA and interactive visualizations are also utlized to understand users reading preferences and factors that lead to a book's or author's success in the market.
Summary of Buisiness Insights
Understanding User Behavior
When the tag counts of different generalized tag_names were ranked, the top 10 tag name shows that users prefer to have separate shelves for books they marked as favorite, read in a particular year (e.g. read in 1990, Childhood Books), owned or borrowed from library, read in a different format (e.g. ebook\ audiobook). The other shelving preferance per the top 10 tag_names were different book categories such as 'Fiction', 'Young - Adult' etc.
The count plot of user provided ratings shows that users are more likely to rate a book 4 or higher. As the tag counts for books they mark as favorite is also higher (shown previosuly), it seems that users are more likely to rate and store a book when they like it.
Users use a wide variety of names even if they are tagging a book in the same category. For example, books relevant to Science Fiction and Fantasy was stored as dark-fantasy','epic-fantasy','fantasy-sci-fi','fantasy-science-fiction','sci-fi','sci-fi-and-fantasy','sf-fantasy' and many other similar alternatives.
Factors to Consider for a Book's Rating
EDA shows that the top 15 books per tag_count as reader's favorite is not same as the top 15 books ranked per ratings of the users. Also, while the average rating counts for the top 15 books marked as the reader's favorite is significantly higher (2191465) than the average ratings received by all books (23833), the avaerage rating counts (18198) for the top 15 books is below the average. Both favorite and top rated 15 books have higher average ratings (4.26 and 4.74 respectively compared to the average ratings of all books (4.01). These statistics suggest that only considering the average rating is not enough to rank books for recommendation. An an ideal metric should also consider how many times the book has been marked as favorite and the total number of ratings it received in addition to the average rating of the book.
9 of the top 15 favorite books are most frequently tagged in the Young - Adult Category.The other popular categories in the top 15 favorite books are science fiction and fantasy, romance, historical fiction or fiction in general. The harry potter books (ranked 2,3,4,6,7) have also been freqently tagged as children/childhood books. A quick look at the publication date of these books reveal that most of the books under Young Adult and Childhood categories were actually publsihed at least 10 years ago. Therefore, they were probably the favorite books of many adult readers when they were young. This highlights that the year of publication and dates of ratings can also impact a book's ranking and should be factored into the performance metric. To be able to determine if the books are equally liked by current generation of young readers, one can check if the average number of positive ratings recevied by a book per year has reduced or increased since its year of publication. As the datasets used in this project do not provide the dates when the books were rated, it was not possible to implement this scheme into the recommendation framework.
Book Categories
Based on the tag_counts of different book categories, it was found that 'Fiction' dominates as the popular category for users of all age groups (i.e. Adult and Young Adult readers). Beside fiction in general, tags related to 'Science Fiction and Fantasy' seems to be used more frequently than other categories in both adult and young adult section. Some other popular categories are Crime & Mysetery, Historical Fiction etc. Based on the findings, it seems that the demand for different kinds of fiction are higher than books based on actual events/facts (i.e. History or Science) in the market. The market seems to agree with these conclusions as about 43% of the books in the dataset are found to be Fiction, with Non - Fiction (20.5%), Young Adult (8.3%) and Science Fiction and Fantasy (5.73%) as other prevailing categories.
Does this finding indicate that a new Fiction has higher chances of getting a good rating than new history book? The answer is probably a 'No'. When average ratings of different book categories were compared, it was found that readers do not have a bias towards rating a particular category higher than the others. The average rating in every category is close to the average rating of all the books (4.01) and mostly range from 3.25 to 4.75. Higher variability exists in the ratings of categories that have more books in the market than other categories.
Authors in Demand
- JK Rowling seems to be everyone's most favorite author with 4 of her books in the the 15 Favorite books. However, when authors were ranked per the number of books they wrote and the average ratings their books received, JK Rowling did not make it to the top 10. Stephen King seems to be the most successful authors with 44 books in the market with an average rating of 3.9. Other succesful authors considering both ratings and number of books are Dean Koontz, John Grisham, Nora Roberts and Jodi Picoult. This suggests that an ideal metric to evaluate an author's demand in the market should include the number of books an author wrote, the ratings the books received, the number of books that has been marked as favorite, and the tag counts as favorite for each book.
Rating Counts per Book and Per User
All the users in the dataset have rated at least 19 books where the most active users rated 200 books. 80% of the users rated at least 100 books
All the books in the dataset received at least 8 ratings. When books were ramked by rating_counts, it seems that the top 10 books recived more than 10,000 ratings. CDF plot of the ratings per book showed that only ~20% of the book received more than 5000 ratings.
As the number of books in the dataset 10000 are less than the number of users (53,424), sparsity is less likely to be an issue for ML modeling with this dataset.
Table of Contents
Chapter 1 Introduction¶
1.1 Problem Statement
1.2 Key Development Goals
1.3 Solution Approach
Chapter 2 Data Wrangling : Highlights ¶
2.1 Raw Dataset
2.2 Data Inspection
2.3 Connection Between Dataframes
2.4 Data Cleaning: Steps
2.5 DataFrame for Keyword Search
Chapter 3 Exploratory Data Analysis (EDA) ¶
3.1 Goals of EDA
3.2 Understanding Users Tagging Preferences
3.3 Attributes of Books Tagged as Favorites
3.4 Understanding Book Ratings
3.5 User Rating Pattern
3.6 Books by Category
3.7 Authors in Demand
Chapter 4 Dataset Size Selection For Modeling (EDA) ¶
4.1 Filtering Inactive Users and Books with Low Rating Counts
4.2 Effect of Datasize on Modeling
Chapter 5 Machine Learning (ML) Modeling and Optimization ¶
Chapter 6 Implementation of the Recommendation System ¶
6.1 Non Personalized Search: Demonstration
6.2 Personalized Search: Demonstration
6.3 Smart Filtering and Tag Recommendation
Chapter 1 Introduction¶
1.1 Problem Statement¶
Recommendation engines have laid the foundation of every major tech company around us that provides retail, video-on-demand or music streaming service and thus redefined the way we shop, search for an old friend, find new music or places to go to. From finding the best product in the market to searching for an old friend online or listening to songs while driving, recommender systems are everywhere. A recommender system helps to filter vast amount of information from all users and item database to individual’s preference. For example, Amazon uses it to suggest products to customers, and Spotify uses it to decide which song to play next for a user.
Book reading apps like Goodreads has personally helped me to find books I couldn’t put away and thus getting back to the habit of reading regularly again. While a lot of datasets for movies (Netflix, Movielens) or songs have been explored previously to understand how recommendation engine works for those applications and what are the scopes of future improvement, book recommendation engines have been relatively less explored.
The primary goal of this project is to develop a collaborative book recommendation model using goodreads dataset that can suggest readers what books to read next. Additionally, data wrangling and exploratory data analysis will be utilized to draw insights about users reading preferences (e.g. how they like to tag, what ratings they usually provide etc.) and current trends in the book market (book categories that are in demand, successful authors in the market etc.).
1.2 Key Development Goals¶
The recommendation system should have the following capabilities
For new or anonymous users, the recommendation engine can make base-case recommendations based on the past ratings and/or other keywords.
With user ID as input and user’s search preferences, the collaborative filtering can make personalized recommendations to an active user based on his/her activity history and search preferences.
The search engine have smart filterning capabiliy and can provide built in tag-recommendations\suggestions to further refine the search
1.3 Solution Approach¶
The overall project is organized in the following framework. Please note that elaborate explanation of each step can be found in separate notebook corresponding to each step.
1. Data Wrangling: (Link to Notebook)
The first step in this process was to quickly inspect all the datasets, identify how they are connected to each other and then perform data wrangling (i.e. identify duplicates, missing values, non -english titles or tag_names, merge diferent datasets to extract meaningful information) so that we can have tidy datasets for exploratory data analysis and modeling. A key step in the data wrangling process was to explore the 34252 different tag_names user have used to tag the books they are interested in, and utlize it to group books into 348 generalized tag names by identifying common patterns in the user provided tag names. For example, Scinece Fiction and Fantasy were chosen as a generalized tag name for books tagged as 'dark-fantasy','epic-fantasy','fantasy-sci-fi','scifi','scifi-fantasy','sf-fantasy' and many other alternatives.
This step above also allowed to form a database of words or string patterns that the readers may use while searching for a new book. An additional performance metric to evaluate a book was also established by ranking the books based on their tag counts as the reader's favorite book. Once data wrangling is complete, the clean datasets were exported to apply EDA.
2. Exploratory Data Analysis: (Link to Notebook)
In the exploratory data analysis, the goal was to explore the clean datasets and try to understand how factors such as categories, author, year of publication etc. affect the rating of a book. It also helped to look at the other factors that can be considered as a performance metric for differnt books or authors ( e.g. how many reviews a book received, how many books an author published and how their ratings compare etc). The user's preferences in terms of tagging books and rate a book was also explored to better understand what built in features to offer in a book recommendation system (built - in tags) to improve the overall user experience.
3. Dataset Size Selection For Modeling: (Link to Notebook)
A qucik inspection of The ratings.csv dataset showed that the dataset has 6,000,000 observations. As modeling with such a large number of observation is computatinally challenging, it was important to identify active users (i.e. users who read and rate frequetntly) and books receiving siginficant reviews for modeling. This allowed to siginificantly reduce computational time and complexity required for modeling while retaining all the necessary information and patterns in the dataset. The cutoff points for users and books were identified by analyzing the CDF plots of number of review per user and number of reviews per book as the plots helped to identify where the information in the dataset and size of the dataset is balanced.
Next, modeling is performed on different subsets of the truncated dataset while increasing the size of the dataset in each step. The modeling accuracy (RMSE) is then calculated for each size to understand if there is a benifit of including more or less observations in terms of modeling accuracy. This step helps to identify the size of the final dataset that is to be used for modeling.
4. Machine Learning (ML) Modeling and Optimization: (Link to Notebook)
In this step, the user's rating history was divided into train and test dataset. The idea is to create a scenario where the train data respresents the book the users have read and rated, and the test data contains books that can be recommendeded to the user in the future.Different collaborative filtering based algorithms (i.e.KNN, SVD or Matrix Factorization) were then fit to the train dataset. To be able to evaluate how the model will perform on unseen data, RMSE score was calculated for each model by utilizing cross validation method. The performance was compared with a baseline ML model to estimate if ML modeling can improve the precition accuracy. A hyperparamter optimization was then performed for each model to further improve the efficiency of the model. The best performing model was then used on the test dataset to predict user's ratings for books in the test dataset.
5. Non Personalized and Personalized Recommendation System: (Link to Notebook)
Data Wrangling and EDA allowed to orgnaize the books under different popular categories based on their tag_counts and tag_names by different users. It also helped us to develop a database of .csv filesto aid keyword based search, recommend tags to refine search or shelve books as well as compute and combine all the relevant information about each book.
In this final step of the project, the non Personalized recommendation system is implemented by utlizing this book based database to recommend books to a new user once the user specifies any of his preferences (categories, authors, number of books to search etc.). The books in the search results is sorted by the average of ratings received in the past, and the top n results are shown. On the contrary, the personalized recommendation system shows customized search results for a particular user where the books are sorted by the ratings that the user is to give per prediction of the ML model.
Chapter 2 Data Wrangling : Highlights¶
2.1 Raw Dataset¶
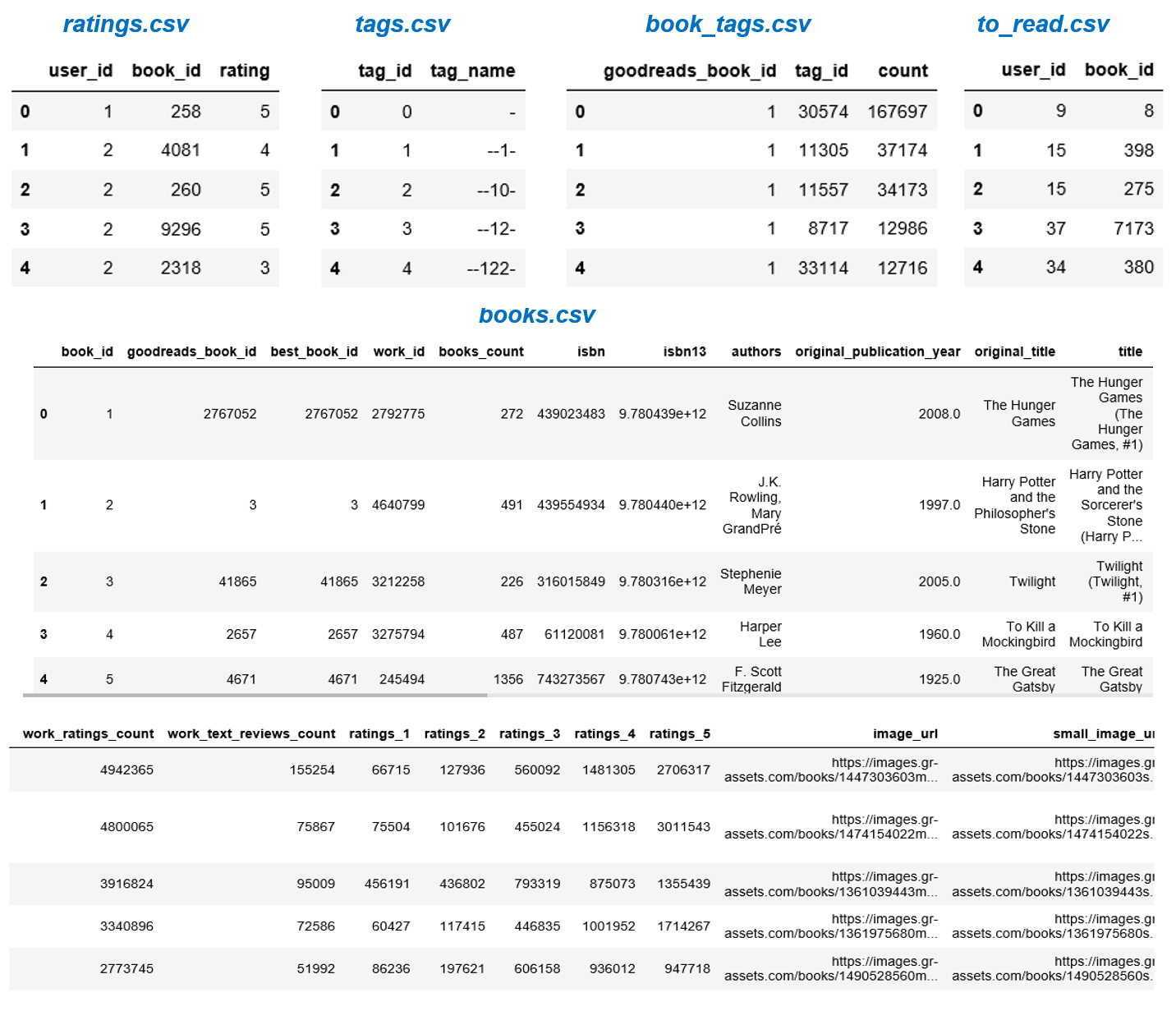
The goodreads dataset for this project is available on Kaggle. A link to the original dataset and a snapshot of all the csv files are given below this section.
*ratings.csv* contains user_ids, book_ids and ratings. It has 6,000,000 observations.
*books.csv* has metadata for each book (goodreads IDs, authors, title, average rating, etc.). The raw dataset has 23 columns and 10,000 entries.
*book_tags.csvcontains tags/shelves/genres assigned by users to books. Tags in this file are represented by their IDs. The file has 999912 observations.
tags.csv* translates tag IDs to names. The file contains 34252 observations.
*to_read.csv* provides IDs of the books marked "to read" by each user, as user_id,book_id pairs.
Link to the preliminary dataset:
https://github.com/zygmuntz/goodbooks-10k.
Below is a snapshot all the csv files in the dataset. All five csv files were imported as Pandas dataframes.
2.2 Data Inspection¶
*ratings.csv*
There are 53424 users rating 10000 books in 5 categories from 1-5. This suggests that each book received multiple ratings. The dataframe is clean, and it does not have any missing\null entries or duplicate rows.
*books.csv* has some entires missing for some of the columns (i.e. isbn,isbn13, original_publication_year, original_title,language_code)
*tags.csv* will require further investigation as the tag_names are not clear from the initial inspection. However, The dataset does not have any duplicate\missing entries
*book_tags.csv* has duplicate rows, but no null entries.
*to_read.csv* looks clean. it does not have any missing\null entries or duplicate rows.
2.3 Connection between Different DataFrames¶
*'ratings.csv' & 'books.csv':*
Both dataframes have a common column 'book_id'. By taking set() function of the 'book_id' columns in both the dataframes, it was found that the 'book_id'column in 'ratings.csv'contains the same unique elements/ book_ids as the'book_id' column in books.csv dataframe. This suggest the column an be used to connect the two dataframes.
*'tags.csv','book_tags.csv' & 'books.csv':*
From the observation of these three dataframes, it seems the column 'tag_id' is common between dataframes for tags.csv and book_tags.csv. Also, the column, goodreads_book_id is common for dataframes between book_tags.csv and books.csv
2.4 Data Cleaning: Steps¶
2.4.1 Handling Missing Entries¶
Only *books.csv* has some entires missing for some of the columns (i.e. isbn,isbn13, original_publication_year, original_title,language_code). Among these columns, original_title and original_publication_year seemed significant to draw some insights using EDA. However, the dataframe also has a 'title' column with no null entries. This column seems to provide similar but a bit more information about each book compared to the 'original_title' column (e.g. book with the title 'The Hunger Games (The Hunger Games #1)' has the orignial_title 'The Hunger Games'). As a result, the 'title' column was used for further data processing. The 'original_publication_year' was also kept as it is since it is unlikely to be used for modeling and only 21 of the 10000 (i.e. less than 1%) observations were missing.
2.4.2 Dropping Duplicates¶
*book_tags.csv* had some duplicates. Dropping the duplicates reduced the the number of observations from 999912 to 999906
2.4.3 Merging DataFrames (tags.csv, book_tags.csv & books.csv)¶
Since tag_id was a common column between 'book_tags.csv' datsaset and 'tags.csv', the two dataframes were merged based on the tag_ids. The 'title' column of the books.csv dataframe was then added to this combined dataframe by merging the column based on 'goodreads_book_id'. The resulting dataframe contains all the tag_names that have been used by different users to catgorize the books, the title of the books and corresponding ids in goodreads.

The next few steps of the data wrangling were geared towards identifying the most frequently occuring tag_names using this combined dataset (lets call it - 'tag_table'). The goal was to understand how users prefer to shelve the books and then use such the insights to categorize the books. Since there are 34512 tag_names in the dataframe, it was necessary to check if there are tag_names that are not meaningful or rarely preferred by users. The other important thing to explore is if the user_provided tag_names are somehow related to each other. If yes, then they can be grouped under new tag_names to simplify the data.
2.4.4 Remove Non - English Tag Names¶
Inspection of the tags.csv and books.csv showed that some of the tag_names and book titles are non-english. As the non-English titles or tag_names are not useful to derive any meaningful info from the dataset, the observations were filtered out from the combined dataframe by doing a search for tag_names and book_titles that have non-ascii characters.
This step helped to reduce the total number of tag names from 34252 to 32963 and the number of books from 10000 to 9814 dataframe
2.4.5 Remove Barely Used Tag Names¶
By taking a summary statistics (i.e. describe() function) of the value_count of tag_names, it was found that there are now 32963 tag_names to categorize a total of 10000 books, but 75% of the tag_names have been used only 5 times by the all the 53424 users. These tag_names probably represent customized categories made by the user and will not be useful to cluster the books by popular categories.
To identify tags that are widely used to shelf the books, the dataframe was grouped ('tag_table') by tag_ids and the number of books that each tag_id covered was counted. Then, the tag_ids that represneted only 300 books (i.e. only 3% of the 10000 books in collection) were filtered out from the dataframe.
Below is a snapshot of some of the non-english tag_names in the dataframe and a summary statistics of the tag_names

2.4.6 Define Generalized Categories by Grouping User Provided Tag_Names¶
In this step, by utlizing the package for RegEx module in python, the similarity of different tag_names were identified. Then they were grouped into common categories.
For exmaple, readers used tag_names such as 'my-favorites','faves','favorite-series', 'shelfari-favorites', 'favourite', 'childhood-favorites','favourite-books','favs' etc. to shelve their favorite books. A fuction was defined to find user_provided tag_names that follow similar pattern (e.g. (strings containing the word 'fav') in this case). Next, these tag_names were replaced with a common category [e.g. Favorites] in the 'tag_name' column. While grouping these user_provided tag_names as'Favorite', the tag counts of the custom tag_names were summed up to determine how many times a particular book has actually been tagged as a 'Favorite'
The approach mentioned above were repeated to explore similarity in the tagging preferences of different users and define other general categories. Example of some other generalized categories are:
- tag_names such as 'kids', 'kids-books', 'kid-lit', 'kid-books', 'childrens', 'children', 'children-s', 'children-s-books', 'childrens-books' etc. were grouped into Children Books
- tag_names such as 'books-i-own','owned','owned-books','i-own','own-it','own-to-read' etc. were grouped into Owned Books
- tag_names such as 'juvenile','juvenile-fiction','teen','teen-fiction','ya','young-adult' etc. were grouped into Young-Adult
- tag_names such as 'dark-fantasy','epic-fantasy','fantasy-sci-fi',scf,'fantasy-science-fiction',fantasy','paranormal-fantasy','sci-fi','sci-fi-and-fantasy','sci-fi-fantasy' etc. were grouped into Science Fiction & Fantasy
- Some other newly defined tag_names are 'Historical Fiction', 'Science', 'Crime & Mystery', 'Women Book List', Audio Books & 'Ebooks' etc.
- At the end of the data wrangling step, the total tag_names in the dataframe were reduced to 348 from an initial total of 34252. All the processed dataframes (cleaned, merged or observations redefined) were then exported as .csv files for exploratory data anlysis and ML modeling.
2.5 DataFrame for Keyword Search¶
- The user provided tag_names also provided an idea of the different kind of names readers like to associate with books or categories. Since the readers may use the same strings or words when looking for a new book, the names were stored in a dataframe to faciliate development of a keyword based book search [discussed later in this report]. Below is snapshot of the dataframe:

Chapter 3 Exploratory Data Analysis (EDA)¶
3.1 Goal of Exploratory Data Analysis¶
In the Exploratory Data Analysis, the datasets cleaned by data wrangling will be explored to get insights about reader's behavioral pattern, reading preferences and factors affecting a book's rating or an author's success.
Some of the questions we will try to answer are as follows
- What books users have shelved more frequently?
- Are their particular authors/ genres/books from a particular era that they really like?
- What are their most favorite books?
- Does the reading preference vary depending on their age group
- Should we only look for high ratings when we consider a book, or there are more factors to consider
- What rating users like to provide in general, does it indicate that they only like to rate when they like a book.
- Based on the average user rating, what should we consider to be a really good book to reocmmend.
- How are different authors performing, what is contributing their success
- Does the readers have a general bias towards certain categories (Are there categories that rate significantly high > compared to other categories?
3.2 Understanding Users Tagging Preferences¶
How Users Like to Tag Their Books ?¶

- Users in general likes to keep a track of book they already read, currently reading and plaaning to read. They have a preference to shelf the books they read in a given duration.
- Readers like to shelve Ebooks, Audiobooks are separately from paperbacks
- Fiction seems to be the most popular category over other book categories
- The top 15 tag_names contains 50% of the total tags made by the users
How Does Tag Preferences Vary for Different Age - Groups?¶

- Most of the tag_names are for books in adult age groups than for books in other age groups. For example, children/ childhood books has no sub-categories, and yound adult book has few subcategories compared to adult books.
- Fiction dominates as the popular category for all users.
- Beside fiction in general, tags related to Science Fiction and Fantasy seems to be used more frequently used than other categories in adult and young adult section.
- Some other popular categories are Crime & Mysetery, Historical Fiction etc. Therefore, it can be concluded that majority of the readers like different kinds of fiction over books based on actual events/facts (i.e. History or Science)
3.3 Attributes of Books Tagged as Favorites¶
Are their particular authors/ genres/books from a particular era that readers really like?¶
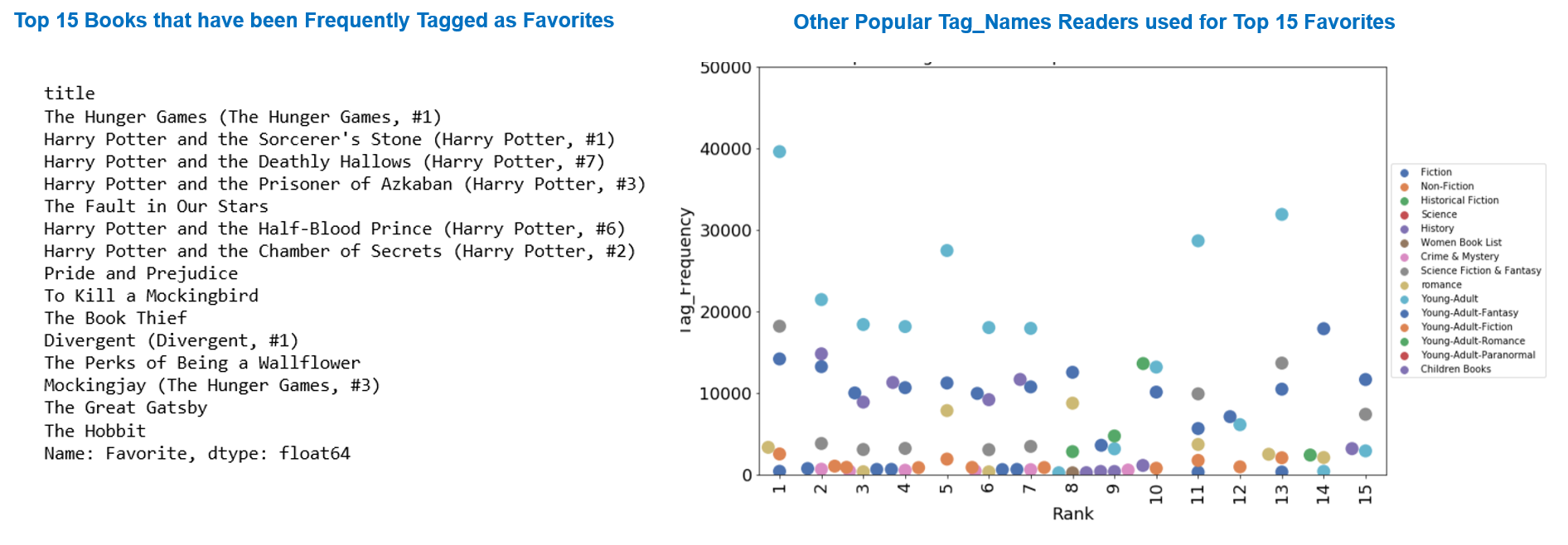
9 of the top 15 favorite books are most frequently tagged in the Young - Adult Category.The popular categories in the top 15 books are science fiction and fantasy, romance, historical fiction or fiction in general. The harry potter books (2,3,4,6,7) have also been freqently tagged as children/childhood books.
The fact that most of the books have been tagged as Young Adult and Childhood books indicate that these books may have been published a while ago and were the favorite books of many of the adult readers when they were young.

- None of the top 15 favorite books are from recent times. This indicate that the readership has grown over the years leading to higher number of tag frequencies. Some of the books were published at least a decade ago, and the oldest (Pride and Prejudice) date backs to 1813.
- JK Rowling is everyone's favorite author
3.4 Understanding Book Ratings¶
Favorite Books vs Top Rated Books¶

- Except for Harry potter, none of the books in the Top 15 favorites are in the top rated list. However, as discussed later in the report, the # of reviews for these books are fairly low compared to the average reviews ( 2437524) received by books listed as favorites.
What Factors Should Be Considered to Rank Books for Recommendation?¶
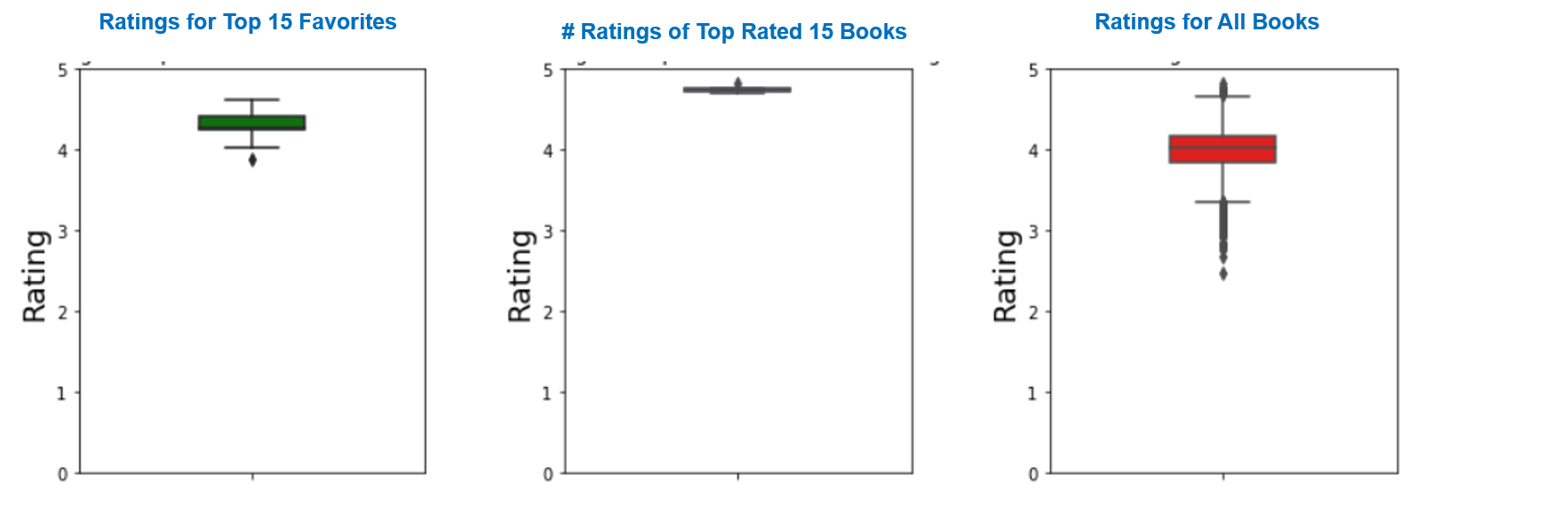
Based on the high average ratings of the books, it seems that readers in general likes to rate the books failry high.
Median of the ratings for the books rated as favorite: 4.264217954505934
Median of the ratings for the books with high ratings: 4.740448254745867
Median of the ratings for all the the books: 4.018821797349181
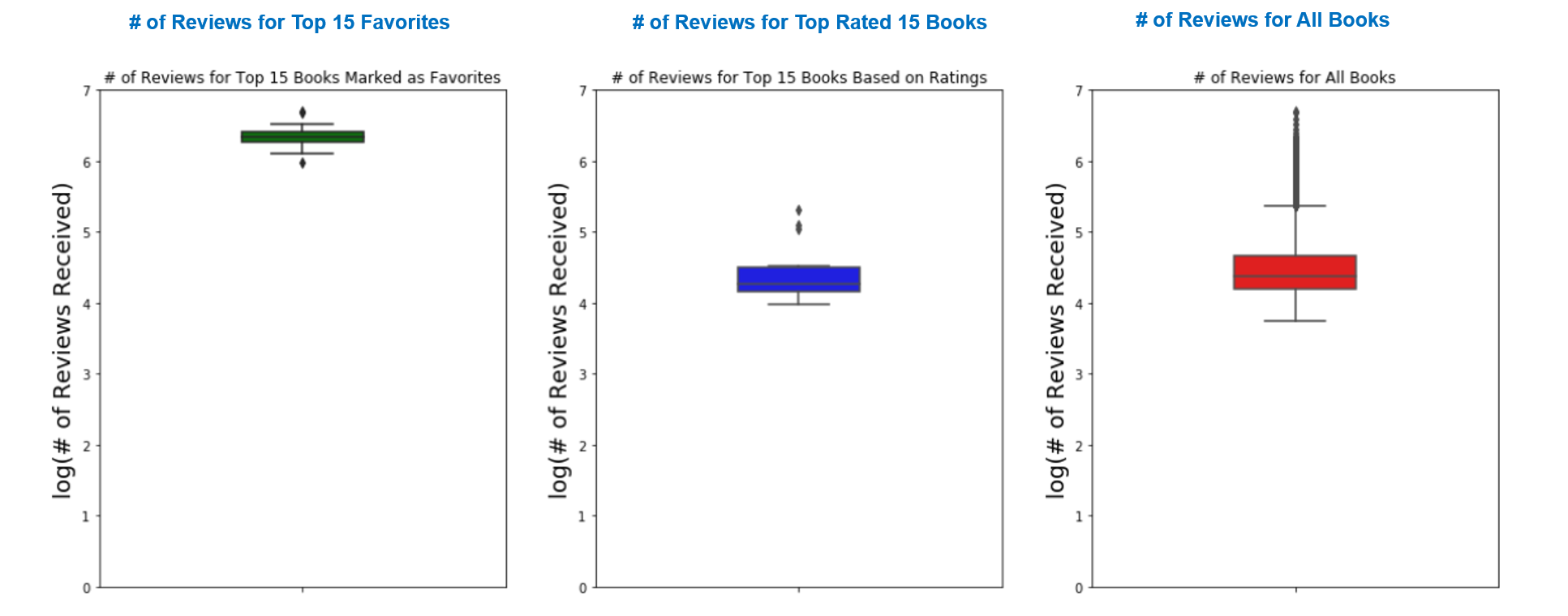
Median # of reviews for the books rated as favorite: 2191465.0
Median # of reviews for the top rated 15 books: 18198.0
Median # of reviews for all the the books: 23832.5
- As can be seen from the box plots above, books shelved a favorites have recieved a significantly higher number of reviews compared to other books. The y scale in the box plot are in log scale. So when it comes to recommending a user a new book to read, ideally the reader's most favorites and number of reviews should be taken into consideration in addition to book ratings.
- The significantly high number of reviews of Favorite books also suggests that users like to write a review for books they mark as favorites
3.5 User Rating Pattern¶
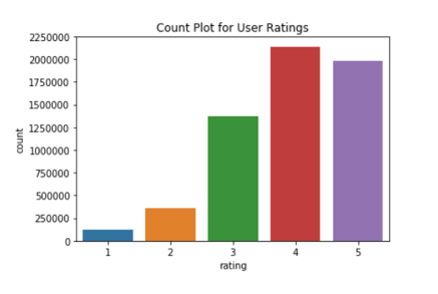
- The count plot shows that users are more likely to rate a book 4 or higher.
3.6 Books by Category¶
- As every book received multiple categories by readers, to be able to associate a main category with the each book, the top 5 categories per tag_count was determined for each book.
- Next, the category with the most tag_count for a book was considered to be the main category of the book for EDA. The name of the top five categories were also stored in a dataframe to aid keyword search by category and tag recommendations for book.

When average ratings of different book categories were compared, it was found that readers do not have a bias towards rating a particular category higher than the others. The average rating in every category is close to the average rating of all the books (4.01) and mostly range from 3.25 to 4.75. Higher variability exists in the ratings of categories that have more books in the market than other categories. About 43% of the books in the dataset are Fiction, with Non - Fiction (20.5%), Young Adult (8.3%) and Science Fiction and Fantasy (5.73%) as other prevailing categories.
3.7 Authors in Demand¶
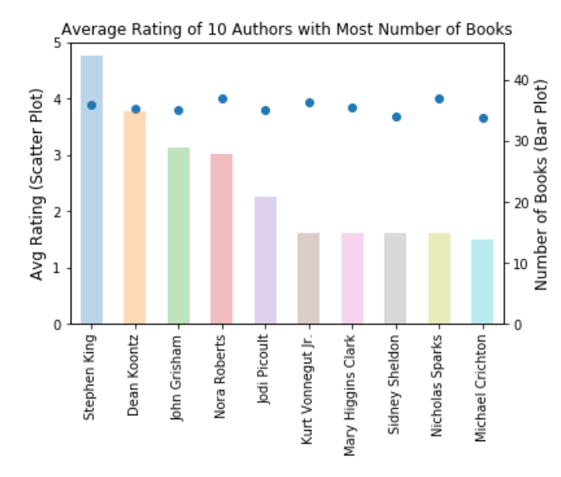
- In section 3.2, it was found that JK Rowling is the most favorite author with 4 of her books in the the 15 Favorite books. However, when authors were ranked per the number of books they wrote and the average ratings their books received, JK Rowling did not make it to the top 10.
- Stephen King seems to be the most successful authors with 44 books in the market with an average rating of 3.9. Other succesful authors considering both ratings and number of books are Dean Koontz, John Grisham, Nora Roberts and Jodi Picoult.
- This suggests that an ideal metric to evaluate an author's demand in the market should include the number of books an author wrote, the ratings the books received, the number of books that has been marked as favorite, and the tag counts as favorite for each book.
4. Dataset Size Selection For Modeling¶
4.1 Filtering Inactive Users and Books with Low Rating Counts¶
The ratings.csv dataset showed that the dataset has 6,000,000 observations. As modeling with such a large number of observation is computatinally challenging, it was important to identify active users (i.e. users who read and rate frequetntly) and books receiving siginficant ratings for modeling. The cutoff points for users and books can be identified by analyzing the CDF plots of number of review per user and number of ratings per book as the plots helped to determine where the amount of useful information in the dataset and size of the dataset is balanced.

All the users have rated at least 19 books.
All the books have recieved ratings. Minimum number of ratings recieved by a book is 8.
When we rank books by rating_counts, it seems that the top 10 books recived more than 10000 ratings. Therefore we chose to only consider books that received siginificant number of ratings (at least 5000 ratings). CDF shows that this will allow us to 80% of all the book as only ~20% of the book received more than 5000 ratings
4.2 Effect of Datasize on Modeling¶
To determine if considering a smaller subset of the available rating data can lead to useful prediction by ML models, a simple KNN based ML algorithm ((available as KNNWithMeans with the sklearn SURPRISE pakacage) was applied on several subsets of the dataset. At each attempt, the number of observations considered in the subset was increased at small increments, and prediction efficieny of the model was estimated for the increasing size of the dataset.

Since there is no siginificant imporvement of the RMSE with the increase in datasize for modeling, it can be extrapolated that model performance will be similar for predicting large amount of data. As the RMSE score seems pretty stable >40,000 observations, a dataset with 100,000 observation was considered for ML modeling.
5 Machine Learning (ML) Modeling and Optimization¶
5.1 Methodology¶
The overall modeling step can be outlined as below:
- The user's rating history was divided into train and test dataset. The idea is to create a scenario where the train data respresents the book the users have read and rated, and the test data contains books that can be recommendeded to the user in the future.
- Different collaborative filtering based algorithms (i.e.KNN, SVD or Matrix Factorization) were then fit to the train dataset. To be able to evaluate how the model will perform on unseen data, RMSE score was calculated for each model by utilizing cross validation method.
- The performance was compared with a baseline ML model (NormalPredict fro Surpirse) to estimate if ML modeling can improve the precition accuracy.
- A hyperparamter optimization was then performed for each model to further improve the efficiency of the model.
- The best performing model was then used on an unseen dataset to predict user's ratings for books in the dataset.
5.2 Results¶

- SVD was found to be the best performing model after grid search and was used to predict user's rating for personalized recommendation. .
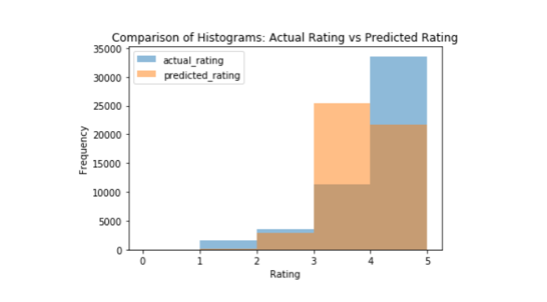
- Comparison of the histogram of actual ratings and the ratings predicted by SVD shows that the model caputures the distribution of the ratings fairly well. Both distribution shows that users tend to rate books mostly 4 or higher, and then mean of the ratings in the test dataset lies between 4 and 5.
Chapter 6 Implementation of the Recommendation System¶
This step implements the book recommendation engine based on the cleaned datasets and ML modeling results. The non - personalized database explores the book related datasets and recommend books to a new user when they provide their reading preferences. The personalized recommendation system ranks books based on the rating predicted by ML model for a user and provide recommendation to him/her based on their search preferences.
Data Wrangling step gave us an idea of how users like to tag\shelf their books and the information was used to group books into different dominant categories based on the user provided tag names. The tag names used by different users can also be used as a repository for KW search. For example, it was found that users often used words like ya, YA, juvenile or teen to tag young - adult books \children books. The recommendation system is designed to keep a collection of such frequently used words by exploring records of tag names, so that when users use those words in the search engine, it can be used to find books in the relevant categories.
The search results can also provide some built in suggestions to tag the books or further refine the search
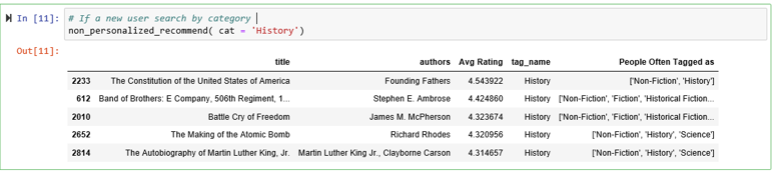
6.1 Non Personalized Search: Demonstration¶
The non-personalized keyword-search recommender module can help new user to find next books to read by using a combination of filtering options (category, author or # of books to show). It ranks the filtered catalog based on average ratings of the book.
6.2 Personalized Search: Demonstration¶
A personalized collaborative recommender module supports personalized book recommendation given the unique user_id. The personalization is computed based on the user's and all other users' rating history of all books via an optimized matrix factorization model (SVD) .Books that are unrated by the user are then filtered from the catalog based on his/her search inputs. The search results are also ranked by ratings that the user is likely to give per model predictions and finally returned as personalized recommendations.

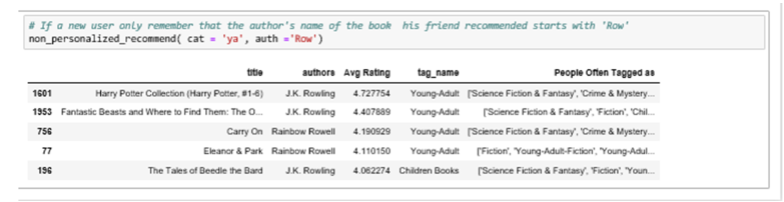
6.3 Smart Filtering and Tag Recommendation¶
Both non-personalized and personalized recommendation have smart filtering capability and can provide tag recommendations. For example, if a user does not remember an author's full name but remember parts of it, he/she can still use it to search books by the author. The recommender module will filter out top - ranked books from all the authors whose names match the input pattern. Additionally, it will also suggest the frequent tag names people have used to shelve these books.