MoViNet Tutorial¶
This notebook provides basic example code to build, run, and fine-tune MoViNets (Mobile Video Networks).
Pretrained models are provided by TensorFlow Hub and the TensorFlow Model Garden, trained on Kinetics 600 for video action classification. All Models use TensorFlow 2 with Keras for inference and training.
The following steps will be performed:
- Running base model inference with TensorFlow Hub
- Running streaming model inference with TensorFlow Hub and plotting predictions
- Exporting a streaming model to TensorFlow Lite for mobile
- Fine-Tuning a base Model with the TensorFlow Model Garden
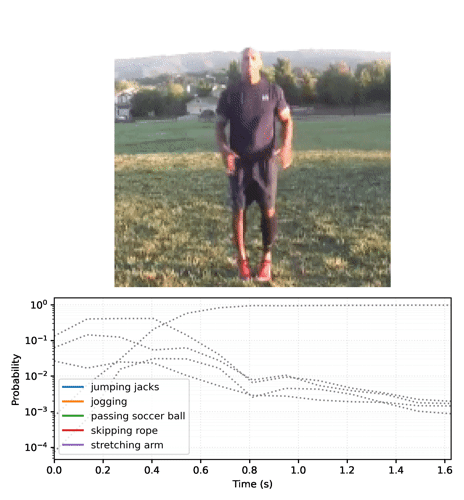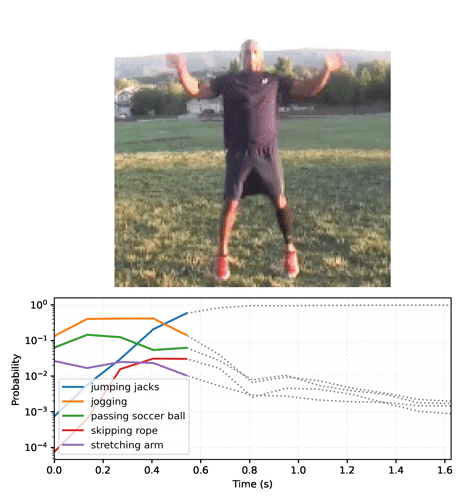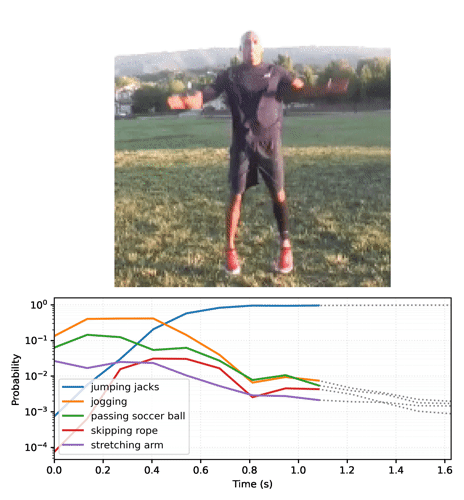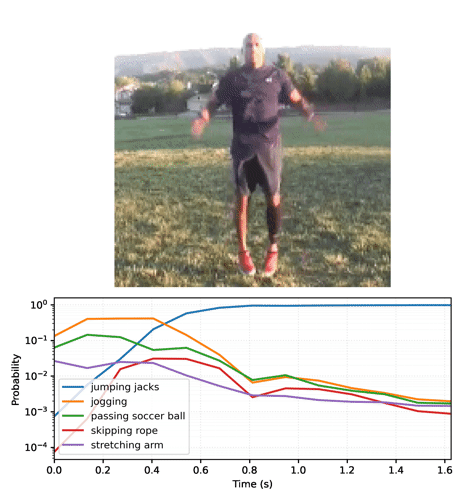
To generate video plots like the one above, see section 2.
Setup¶
For inference on smaller models (A0-A2), CPU is sufficient for this Colab. For fine-tuning, it is recommended to run the models using GPUs.
To select a GPU in Colab, select Runtime > Change runtime type > Hardware accelerator > GPU dropdown in the top menu.
# Install packages
# tf-models-official is the stable Model Garden package
# tf-models-nightly includes latest changes
!pip install -U -q "tf-models-official"
# Install the mediapy package for visualizing images/videos.
# See https://github.com/google/mediapy
!command -v ffmpeg >/dev/null || (apt update && apt install -y ffmpeg)
!pip install -q mediapy
# Run imports
import os
import matplotlib as mpl
import matplotlib.pyplot as plt
import mediapy as media
import numpy as np
import PIL
import pandas as pd
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
import tqdm
import absl.logging
tf.get_logger().setLevel('ERROR')
absl.logging.set_verbosity(absl.logging.ERROR)
mpl.rcParams.update({
'font.size': 10,
})
Run the cell below to define helper functions and create variables.
#@title Run this cell to set up some helper code.
# Download Kinetics 600 label map
!wget https://raw.githubusercontent.com/tensorflow/models/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/kinetics_600_labels.txt -O labels.txt -q
with tf.io.gfile.GFile('labels.txt') as f:
lines = f.readlines()
KINETICS_600_LABELS_LIST = [line.strip() for line in lines]
KINETICS_600_LABELS = tf.constant(KINETICS_600_LABELS_LIST)
def get_top_k(probs, k=5, label_map=KINETICS_600_LABELS):
"""Outputs the top k model labels and probabilities on the given video."""
top_predictions = tf.argsort(probs, axis=-1, direction='DESCENDING')[:k]
top_labels = tf.gather(label_map, top_predictions, axis=-1)
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
top_probs = tf.gather(probs, top_predictions, axis=-1).numpy()
return tuple(zip(top_labels, top_probs))
def predict_top_k(model, video, k=5, label_map=KINETICS_600_LABELS):
"""Outputs the top k model labels and probabilities on the given video."""
outputs = model.predict(video[tf.newaxis])[0]
probs = tf.nn.softmax(outputs)
return get_top_k(probs, k=k, label_map=label_map)
def load_movinet_from_hub(model_id, model_mode, hub_version=3):
"""Loads a MoViNet model from TF Hub."""
hub_url = f'https://tfhub.dev/tensorflow/movinet/{model_id}/{model_mode}/kinetics-600/classification/{hub_version}'
encoder = hub.KerasLayer(hub_url, trainable=True)
inputs = tf.keras.layers.Input(
shape=[None, None, None, 3],
dtype=tf.float32)
if model_mode == 'base':
inputs = dict(image=inputs)
else:
# Define the state inputs, which is a dict that maps state names to tensors.
init_states_fn = encoder.resolved_object.signatures['init_states']
state_shapes = {
name: ([s if s > 0 else None for s in state.shape], state.dtype)
for name, state in init_states_fn(tf.constant([0, 0, 0, 0, 3])).items()
}
states_input = {
name: tf.keras.Input(shape[1:], dtype=dtype, name=name)
for name, (shape, dtype) in state_shapes.items()
}
# The inputs to the model are the states and the video
inputs = {**states_input, 'image': inputs}
# Output shape: [batch_size, 600]
outputs = encoder(inputs)
model = tf.keras.Model(inputs, outputs)
model.build([1, 1, 1, 1, 3])
return model
# Download example gif
!wget https://github.com/tensorflow/models/raw/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/jumpingjack.gif -O jumpingjack.gif -q
def load_gif(file_path, image_size=(224, 224)):
"""Loads a gif file into a TF tensor."""
with tf.io.gfile.GFile(file_path, 'rb') as f:
video = tf.io.decode_gif(f.read())
video = tf.image.resize(video, image_size)
video = tf.cast(video, tf.float32) / 255.
return video
def get_top_k_streaming_labels(probs, k=5, label_map=KINETICS_600_LABELS_LIST):
"""Returns the top-k labels over an entire video sequence.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
k: the number of top predictions to select.
label_map: a list of labels to map logit indices to label strings.
Returns:
a tuple of the top-k probabilities, labels, and logit indices
"""
top_categories_last = tf.argsort(probs, -1, 'DESCENDING')[-1, :1]
categories = tf.argsort(probs, -1, 'DESCENDING')[:, :k]
categories = tf.reshape(categories, [-1])
counts = sorted([
(i.numpy(), tf.reduce_sum(tf.cast(categories == i, tf.int32)).numpy())
for i in tf.unique(categories)[0]
], key=lambda x: x[1], reverse=True)
top_probs_idx = tf.constant([i for i, _ in counts[:k]])
top_probs_idx = tf.concat([top_categories_last, top_probs_idx], 0)
top_probs_idx = tf.unique(top_probs_idx)[0][:k+1]
top_probs = tf.gather(probs, top_probs_idx, axis=-1)
top_probs = tf.transpose(top_probs, perm=(1, 0))
top_labels = tf.gather(label_map, top_probs_idx, axis=0)
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
return top_probs, top_labels, top_probs_idx
def plot_streaming_top_preds_at_step(
top_probs,
top_labels,
step=None,
image=None,
legend_loc='lower left',
duration_seconds=10,
figure_height=500,
playhead_scale=0.8,
grid_alpha=0.3):
"""Generates a plot of the top video model predictions at a given time step.
Args:
top_probs: a tensor of shape (k, num_frames) representing the top-k
probabilities over all frames.
top_labels: a list of length k that represents the top-k label strings.
step: the current time step in the range [0, num_frames].
image: the image frame to display at the current time step.
legend_loc: the placement location of the legend.
duration_seconds: the total duration of the video.
figure_height: the output figure height.
playhead_scale: scale value for the playhead.
grid_alpha: alpha value for the gridlines.
Returns:
A tuple of the output numpy image, figure, and axes.
"""
num_labels, num_frames = top_probs.shape
if step is None:
step = num_frames
fig = plt.figure(figsize=(6.5, 7), dpi=300)
gs = mpl.gridspec.GridSpec(8, 1)
ax2 = plt.subplot(gs[:-3, :])
ax = plt.subplot(gs[-3:, :])
if image is not None:
ax2.imshow(image, interpolation='nearest')
ax2.axis('off')
preview_line_x = tf.linspace(0., duration_seconds, num_frames)
preview_line_y = top_probs
line_x = preview_line_x[:step+1]
line_y = preview_line_y[:, :step+1]
for i in range(num_labels):
ax.plot(preview_line_x, preview_line_y[i], label=None, linewidth='1.5',
linestyle=':', color='gray')
ax.plot(line_x, line_y[i], label=top_labels[i], linewidth='2.0')
ax.grid(which='major', linestyle=':', linewidth='1.0', alpha=grid_alpha)
ax.grid(which='minor', linestyle=':', linewidth='0.5', alpha=grid_alpha)
min_height = tf.reduce_min(top_probs) * playhead_scale
max_height = tf.reduce_max(top_probs)
ax.vlines(preview_line_x[step], min_height, max_height, colors='red')
ax.scatter(preview_line_x[step], max_height, color='red')
ax.legend(loc=legend_loc)
plt.xlim(0, duration_seconds)
plt.ylabel('Probability')
plt.xlabel('Time (s)')
plt.yscale('log')
fig.tight_layout()
fig.canvas.draw()
data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
plt.close()
figure_width = int(figure_height * data.shape[1] / data.shape[0])
image = PIL.Image.fromarray(data).resize([figure_width, figure_height])
image = np.array(image)
return image, (fig, ax, ax2)
def plot_streaming_top_preds(
probs,
video,
top_k=5,
video_fps=25.,
figure_height=500,
use_progbar=True):
"""Generates a video plot of the top video model predictions.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
video: the video to display in the plot.
top_k: the number of top predictions to select.
video_fps: the input video fps.
figure_fps: the output video fps.
figure_height: the height of the output video.
use_progbar: display a progress bar.
Returns:
A numpy array representing the output video.
"""
video_fps = 8.
figure_height = 500
steps = video.shape[0]
duration = steps / video_fps
top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)
images = []
step_generator = tqdm.trange(steps) if use_progbar else range(steps)
for i in step_generator:
image, _ = plot_streaming_top_preds_at_step(
top_probs=top_probs,
top_labels=top_labels,
step=i,
image=video[i],
duration_seconds=duration,
figure_height=figure_height,
)
images.append(image)
return np.array(images)
Running Base Model Inference with TensorFlow Hub¶
We will load MoViNet-A2-Base from TensorFlow Hub as part of the MoViNet collection.
The following code will:
- Load a MoViNet KerasLayer from tfhub.dev.
- Wrap the layer in a Keras Model.
- Load an example gif as a video.
- Classify the video and print the top-5 predicted classes.
model = load_movinet_from_hub('a2', 'base', hub_version=3)
To provide a simple example video for classification, we can load a short gif of jumping jacks being performed.

Attribution: Footage shared by Coach Bobby Bluford on YouTube under the CC-BY license.
video = load_gif('jumpingjack.gif', image_size=(172, 172))
# Show video
print(video.shape)
media.show_video(video.numpy(), fps=5)
# Run the model on the video and output the top 5 predictions
outputs = predict_top_k(model, video)
for label, prob in outputs:
print(label, prob)
1/1 [==============================] - 18s 18s/step jumping jacks 0.9166436 zumba 0.016020758 doing aerobics 0.008053949 dancing charleston 0.006083598 lunge 0.0035062768
Run Streaming Model Inference with TensorFlow Hub and Plot Predictions¶
We will load MoViNet-A2-Stream from TensorFlow Hub as part of the MoViNet collection.
The following code will:
- Load a MoViNet model from tfhub.dev.
- Classify an example video and plot the streaming predictions over time.
model = load_movinet_from_hub('a2', 'stream', hub_version=3)
# Create initial states for the stream model
init_states_fn = model.layers[-1].resolved_object.signatures['init_states']
init_states = init_states_fn(tf.shape(video[tf.newaxis]))
# Insert your video clip here
video = load_gif('jumpingjack.gif', image_size=(172, 172))
clips = tf.split(video[tf.newaxis], video.shape[0], axis=1)
all_logits = []
# To run on a video, pass in one frame at a time
states = init_states
for clip in tqdm.tqdm(clips):
# Input shape: [1, 1, 172, 172, 3]
logits, states = model.predict({**states, 'image': clip}, verbose=0)
all_logits.append(logits)
logits = tf.concat(all_logits, 0)
probs = tf.nn.softmax(logits)
final_probs = probs[-1]
top_k = get_top_k(final_probs)
print()
for label, prob in top_k:
print(label, prob)
100%|██████████| 13/13 [00:10<00:00, 1.23it/s]
jumping jacks 0.9998122 zumba 0.00011835461 doing aerobics 3.3375778e-05 dancing charleston 4.9820073e-06 finger snapping 3.867353e-06
# Generate a plot and output to a video tensor
plot_video = plot_streaming_top_preds(probs, video, video_fps=8.)
100%|██████████| 13/13 [00:06<00:00, 1.90it/s]
# For gif format, set codec='gif'
media.show_video(plot_video, fps=3)
Export a Streaming Model to TensorFlow Lite for Mobile¶
We will convert a MoViNet-A0-Stream model to TensorFlow Lite.
The following code will:
- Load a MoViNet-A0-Stream model.
- Convert the model to TF Lite.
- Run inference on an example video using the Python interpreter.
from official.projects.movinet.modeling import movinet
from official.projects.movinet.modeling import movinet_model
from official.projects.movinet.tools import export_saved_model
model_id = 'a0'
use_positional_encoding = model_id in {'a3', 'a4', 'a5'}
# Create backbone and model.
backbone = movinet.Movinet(
model_id=model_id,
causal=True,
conv_type='2plus1d',
se_type='2plus3d',
activation='hard_swish',
gating_activation='hard_sigmoid',
use_positional_encoding=use_positional_encoding,
use_external_states=True,
)
model = movinet_model.MovinetClassifier(
backbone,
num_classes=600,
output_states=True)
# Create your example input here.
# Refer to the paper for recommended input shapes.
inputs = tf.ones([1, 13, 172, 172, 3])
# [Optional] Build the model and load a pretrained checkpoint.
model.build(inputs.shape)
# Extract pretrained weights
!wget https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_stream.tar.gz -O movinet_a0_stream.tar.gz -q
!tar -xvf movinet_a0_stream.tar.gz
checkpoint_dir = 'movinet_a0_stream'
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
checkpoint = tf.train.Checkpoint(model=model)
status = checkpoint.restore(checkpoint_path)
status.assert_existing_objects_matched()
movinet_a0_stream/ movinet_a0_stream/ckpt-1.data-00000-of-00001 movinet_a0_stream/ckpt-1.index movinet_a0_stream/checkpoint
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f0b0dc436a0>
# Export to saved model
saved_model_dir = 'model'
tflite_filename = 'model.tflite'
input_shape = [1, 1, 172, 172, 3]
# Convert to saved model
export_saved_model.export_saved_model(
model=model,
input_shape=input_shape,
export_path=saved_model_dir,
causal=True,
bundle_input_init_states_fn=False)
# Convert to TF Lite
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
tflite_model = converter.convert()
with open(tflite_filename, 'wb') as f:
f.write(tflite_model)
# Create the interpreter and signature runner
interpreter = tf.lite.Interpreter(model_path=tflite_filename)
runner = interpreter.get_signature_runner()
init_states = {
name: tf.zeros(x['shape'], dtype=x['dtype'])
for name, x in runner.get_input_details().items()
}
del init_states['image']
# Insert your video clip here
video = load_gif('jumpingjack.gif', image_size=(172, 172))
clips = tf.split(video[tf.newaxis], video.shape[0], axis=1)
# To run on a video, pass in one frame at a time
states = init_states
for clip in clips:
# Input shape: [1, 1, 172, 172, 3]
outputs = runner(**states, image=clip)
logits = outputs.pop('logits')[0]
states = outputs
probs = tf.nn.softmax(logits)
top_k = get_top_k(probs)
print()
for label, prob in top_k:
print(label, prob)
jumping jacks 0.9733523 jogging 0.0032490466 stretching arm 0.002780116 riding unicycle 0.0019377996 passing soccer ball 0.0016310472
Fine-Tune a Base Model with the TensorFlow Model Garden¶
We will Fine-tune MoViNet-A0-Base on UCF-101.
The following code will:
- Load the UCF-101 dataset with TensorFlow Datasets.
- Create a simple
tf.data.Datasetpipeline for training and evaluation. - Display some example videos from the dataset.
- Build a MoViNet model and load pretrained weights.
- Fine-tune the final classifier layers on UCF-101 and evaluate accuracy on the validation set.
Load the UCF-101 Dataset with TensorFlow Datasets¶
Calling download_and_prepare() will automatically download the dataset. This step may take up to 1 hour depending on the download and extraction speed. After downloading, the next cell will output information about the dataset.
# Run imports
import tensorflow_datasets as tfds
from official.vision.configs import video_classification
from official.projects.movinet.configs import movinet as movinet_configs
from official.projects.movinet.modeling import movinet
from official.projects.movinet.modeling import movinet_layers
from official.projects.movinet.modeling import movinet_model
dataset_name = 'ucf101'
builder = tfds.builder(dataset_name)
config = tfds.download.DownloadConfig(verify_ssl=False)
builder.download_and_prepare(download_config=config)
num_classes = builder.info.features['label'].num_classes
num_examples = {
name: split.num_examples
for name, split in builder.info.splits.items()
}
print('Number of classes:', num_classes)
print('Number of examples for train:', num_examples['train'])
print('Number of examples for test:', num_examples['test'])
print()
builder.info
Number of classes: 101 Number of examples for train: 9537 Number of examples for test: 3783
tfds.core.DatasetInfo(
name='ucf101',
full_name='ucf101/ucf101_1_256/2.0.0',
description="""
A 101-label video classification dataset.
""",
config_description="""
256x256 UCF with the first action recognition split.
""",
homepage='https://www.crcv.ucf.edu/data-sets/ucf101/',
data_path='~/tensorflow_datasets/ucf101/ucf101_1_256/2.0.0',
file_format=tfrecord,
download_size=6.48 GiB,
dataset_size=7.41 GiB,
features=FeaturesDict({
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=101),
'video': Video(Image(shape=(256, 256, 3), dtype=tf.uint8)),
}),
supervised_keys=None,
disable_shuffling=False,
splits={
'test': <SplitInfo num_examples=3783, num_shards=32>,
'train': <SplitInfo num_examples=9537, num_shards=64>,
},
citation="""@article{DBLP:journals/corr/abs-1212-0402,
author = {Khurram Soomro and
Amir Roshan Zamir and
Mubarak Shah},
title = {{UCF101:} {A} Dataset of 101 Human Actions Classes From Videos in
The Wild},
journal = {CoRR},
volume = {abs/1212.0402},
year = {2012},
url = {http://arxiv.org/abs/1212.0402},
archivePrefix = {arXiv},
eprint = {1212.0402},
timestamp = {Mon, 13 Aug 2018 16:47:45 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1212-0402},
bibsource = {dblp computer science bibliography, https://dblp.org}
}""",
)
# Build the training and evaluation datasets.
batch_size = 8
num_frames = 8
frame_stride = 10
resolution = 172
def format_features(features):
video = features['video']
video = video[:, ::frame_stride]
video = video[:, :num_frames]
video = tf.reshape(video, [-1, video.shape[2], video.shape[3], 3])
video = tf.image.resize(video, (resolution, resolution))
video = tf.reshape(video, [-1, num_frames, resolution, resolution, 3])
video = tf.cast(video, tf.float32) / 255.
label = tf.one_hot(features['label'], num_classes)
return (video, label)
train_dataset = builder.as_dataset(
split='train',
batch_size=batch_size,
shuffle_files=True)
train_dataset = train_dataset.map(
format_features,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.repeat()
train_dataset = train_dataset.prefetch(2)
test_dataset = builder.as_dataset(
split='test',
batch_size=batch_size)
test_dataset = test_dataset.map(
format_features,
num_parallel_calls=tf.data.AUTOTUNE,
deterministic=True)
test_dataset = test_dataset.prefetch(2)
Display some example videos from the dataset.
videos, labels = next(iter(train_dataset))
media.show_videos(videos.numpy(), codec='gif', fps=5)
Build MoViNet-A0-Base and Load Pretrained Weights¶
Here we create a MoViNet model using the open source code provided in official/projects/movinet and load the pretrained weights. Here we freeze the all layers except the final classifier head to speed up fine-tuning.
model_id = 'a0'
tf.keras.backend.clear_session()
backbone = movinet.Movinet(model_id=model_id)
model = movinet_model.MovinetClassifier(backbone=backbone, num_classes=600)
model.build([1, 1, 1, 1, 3])
# Load pretrained weights
!wget https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz -O movinet_a0_base.tar.gz -q
!tar -xvf movinet_a0_base.tar.gz
checkpoint_dir = 'movinet_a0_base'
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
checkpoint = tf.train.Checkpoint(model=model)
status = checkpoint.restore(checkpoint_path)
status.assert_existing_objects_matched()
def build_classifier(backbone, num_classes, freeze_backbone=False):
"""Builds a classifier on top of a backbone model."""
model = movinet_model.MovinetClassifier(
backbone=backbone,
num_classes=num_classes)
model.build([batch_size, num_frames, resolution, resolution, 3])
if freeze_backbone:
for layer in model.layers[:-1]:
layer.trainable = False
model.layers[-1].trainable = True
return model
# Wrap the backbone with a new classifier to create a new classifier head
# with num_classes outputs (101 classes for UCF101).
# Freeze all layers except for the final classifier head.
model = build_classifier(backbone, num_classes, freeze_backbone=True)
movinet_a0_base/ movinet_a0_base/checkpoint movinet_a0_base/ckpt-1.data-00000-of-00001 movinet_a0_base/ckpt-1.index
Configure fine-tuning with training/evaluation steps, loss object, metrics, learning rate, optimizer, and callbacks.
Here we use 3 epochs. Training for more epochs should improve accuracy.
num_epochs = 3
train_steps = num_examples['train'] // batch_size
total_train_steps = train_steps * num_epochs
test_steps = num_examples['test'] // batch_size
loss_obj = tf.keras.losses.CategoricalCrossentropy(
from_logits=True,
label_smoothing=0.1)
metrics = [
tf.keras.metrics.TopKCategoricalAccuracy(
k=1, name='top_1', dtype=tf.float32),
tf.keras.metrics.TopKCategoricalAccuracy(
k=5, name='top_5', dtype=tf.float32),
]
initial_learning_rate = 0.01
learning_rate = tf.keras.optimizers.schedules.CosineDecay(
initial_learning_rate, decay_steps=total_train_steps,
)
optimizer = tf.keras.optimizers.RMSprop(
learning_rate, rho=0.9, momentum=0.9, epsilon=1.0, clipnorm=1.0)
model.compile(loss=loss_obj, optimizer=optimizer, metrics=metrics)
callbacks = [
tf.keras.callbacks.TensorBoard(),
]
Run the fine-tuning with Keras compile/fit. After fine-tuning the model, we should be able to achieve >85% accuracy on the test set.
results = model.fit(
train_dataset,
validation_data=test_dataset,
epochs=num_epochs,
steps_per_epoch=train_steps,
validation_steps=test_steps,
callbacks=callbacks,
validation_freq=1,
verbose=1)
Epoch 1/3 1192/1192 [==============================] - 1151s 949ms/step - loss: 2.5097 - top_1: 0.6726 - top_5: 0.8745 - val_loss: 1.6358 - val_top_1: 0.8125 - val_top_5: 0.9666 Epoch 2/3 1192/1192 [==============================] - 1138s 951ms/step - loss: 1.3347 - top_1: 0.9062 - top_5: 0.9894 - val_loss: 1.4627 - val_top_1: 0.8400 - val_top_5: 0.9709 Epoch 3/3 1192/1192 [==============================] - 1138s 955ms/step - loss: 1.2301 - top_1: 0.9340 - top_5: 0.9943 - val_loss: 1.4386 - val_top_1: 0.8438 - val_top_5: 0.9751
We can also view the training and evaluation progress in TensorBoard.
%reload_ext tensorboard
%tensorboard --logdir logs --port 0
Reusing TensorBoard on port 43479 (pid 278134), started 19:51:44 ago. (Use '!kill 278134' to kill it.)