Creating Text-Fabric dataset (from GBI trees XML nodes)¶
Version: 0.3 (June 15, 2023 - small updates; updated documentation, adding feature 'after')
Table of content
[Part 1: Read GBI XML data and store in pickle](#first-bullet)
[Part 1b: Sort the nodes](#second-bullet)
[Part 2: Nestle1904GBI production from pickle input](#third-bullet)
Introduction¶
The source data for the conversion are the XML node files representing the macula-greek version of Eberhard Nestle's 1904 Greek New Testament (British Foreign Bible Society, 1904). The starting dataset is formatted according to Syntax diagram markup by the Global Bible Initiative (GBI). The most recent source data can be found on github https://github.com/Clear-Bible/macula-greek/tree/main/Nestle1904/nodes. Attribution: "MACULA Greek Linguistic Datasets, available at https://github.com/Clear-Bible/macula-greek/".
The production of the Text-Fabric files consist of two major parts. The first part is the creation of pickle files. The second part is the actual Text-Fabric creation process. Both parts are independent, allowing to start from part 2 by using the pickle files created in part 1 as input.

Part 1: Read GBI XML data and store in pickle ¶
Back to TOC¶
This script extracts all information from the GBI tree XML data file, organizes it into a Pandas DataFrame, and saves the result per book in a pickle file. Please note that pickling in Python refers to the process of serializing an object into a disk file or buffer. See also the Python3 documentation.
Within the context of this script, the term 'Leaf' refers to nodes that contain the Greek word as data. These nodes are also referred to as 'terminal nodes' since they do not have any children, similar to leaves on a tree. Additionally, Parent1 represents the parent of the leaf, Parent2 represents the parent of Parent1, and so on. For a visual representation, please refer to the following diagram.
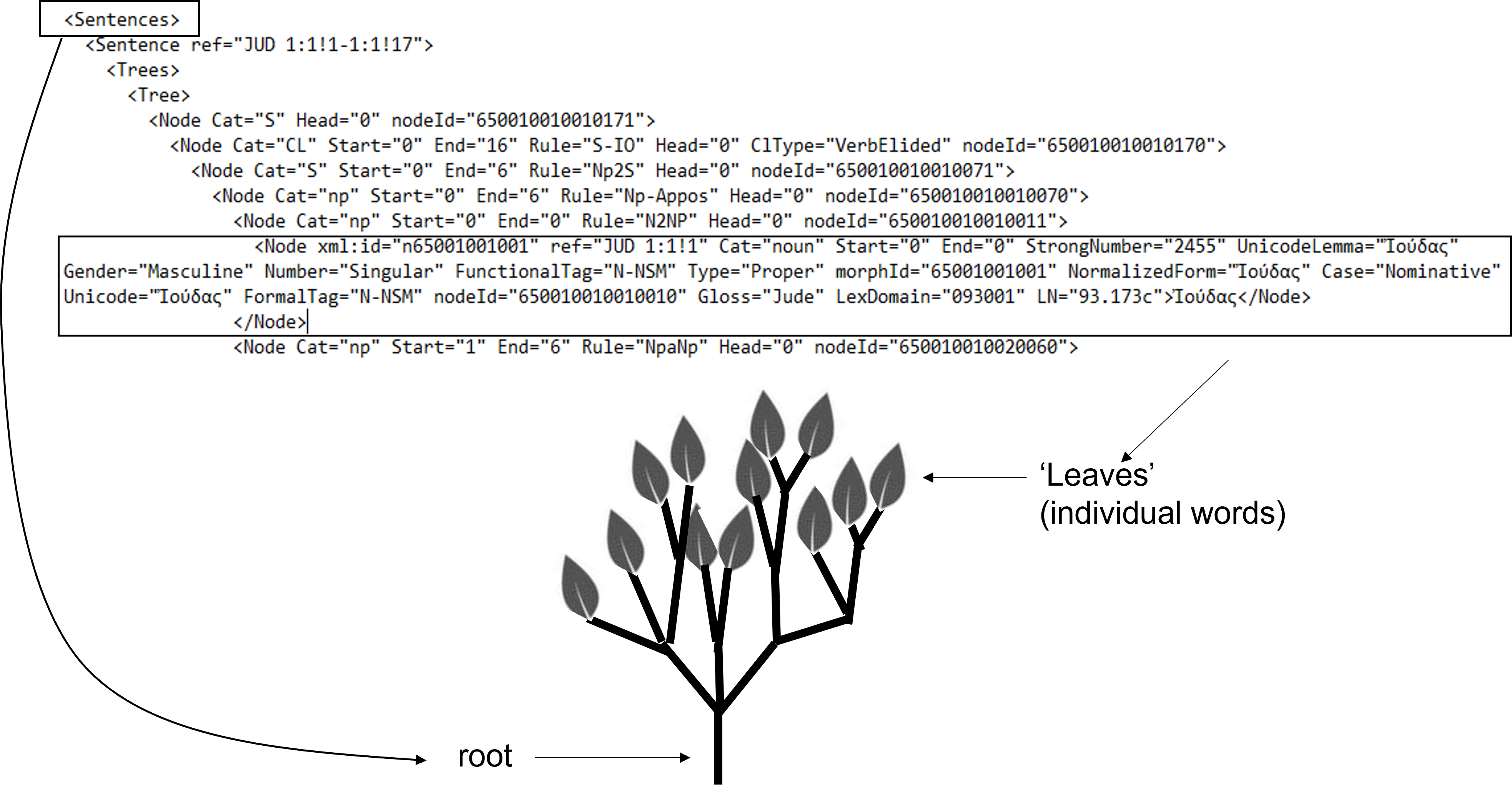
For a full description of the structure of the source data see document MACULA Greek Treebank for the Nestle 1904 Greek New Testament.pdf
Step 1: Import various libraries¶
import pandas as pd
import sys
import os
import time
import pickle
import re # used for regular expressions
from os import listdir
from os.path import isfile, join
import xml.etree.ElementTree as ET
Step 2: Initialize global data¶
IMPORTANT: To ensure proper creation of the Text-Fabric files on your system, it is crucial to adjust the values of BaseDir, InputDir, and OutputDir to match the location of the data and the operating system you are using. In this Jupyter Notebook, Windows is the operating system employed.
BaseDir = 'C:\\Users\\tonyj\\my_new_Jupyter_folder\\test_of_xml_etree\\'
InputDir = BaseDir+'inputfiles\\'
OutputDir = BaseDir+'outputfiles\\'
# key: filename, [0]=book_long, [1]=book_num, [3]=book_short
bo2book = {'01-matthew': ['Matthew', '1', 'Matt'],
'02-mark': ['Mark', '2', 'Mark'],
'03-luke': ['Luke', '3', 'Luke'],
'04-john': ['John', '4', 'John'],
'05-acts': ['Acts', '5', 'Acts'],
'06-romans': ['Romans', '6', 'Rom'],
'07-1corinthians': ['I_Corinthians', '7', '1Cor'],
'08-2corinthians': ['II_Corinthians', '8', '2Cor'],
'09-galatians': ['Galatians', '9', 'Gal'],
'10-ephesians': ['Ephesians', '10', 'Eph'],
'11-philippians': ['Philippians', '11', 'Phil'],
'12-colossians': ['Colossians', '12', 'Col'],
'13-1thessalonians':['I_Thessalonians', '13', '1Thess'],
'14-2thessalonians':['II_Thessalonians','14', '2Thess'],
'15-1timothy': ['I_Timothy', '15', '1Tim'],
'16-2timothy': ['II_Timothy', '16', '2Tim'],
'17-titus': ['Titus', '17', 'Titus'],
'18-philemon': ['Philemon', '18', 'Phlm'],
'19-hebrews': ['Hebrews', '19', 'Heb'],
'20-james': ['James', '20', 'Jas'],
'21-1peter': ['I_Peter', '21', '1Pet'],
'22-2peter': ['II_Peter', '22', '2Pet'],
'23-1john': ['I_John', '23', '1John'],
'24-2john': ['II_John', '24', '2John'],
'25-3john': ['III_John', '25', '3John'],
'26-jude': ['Jude', '26', 'Jude'],
'27-revelation': ['Revelation', '27', 'Rev']}
Step 3: Define Function to add parent info to each node of the XML tree¶
To traverse from the 'leafs' (terminating nodes) up to the root of the tree, it is necessary to include information in each node that points to its parent.
(The concept is derived from https://stackoverflow.com/questions/2170610/access-elementtree-node-parent-node)
def addParentInfo(et):
for child in et:
child.attrib['parent'] = et
addParentInfo(child)
def getParent(et):
if 'parent' in et.attrib:
return et.attrib['parent']
else:
return None
Step 4: Read and process the XML data and store panda dataframe in pickle¶
This code processes books in the correct order. Firstly, it parses the XML and adds parent information to each node. Then, it loops through the nodes and checks if it is a 'leaf' node, meaning it contains only one word. If it is a 'leaf' node, the following steps are performed:
- Adds computed data to the 'leaf' nodes in memory.
- Traverses from the 'leaf' node up to the root and adds information from the parent, grandparent, and so on, to the 'leaf' node.
- Once it reaches the root, it stops and stores all the gathered information in a dataframe that will be added to the full_dataframe.
- After processing all the nodes for a specific book, the full_dataframe is exported to a pickle file specific to that book.
# Set some globals
monad=1 # Smallest meaningful unit of text (in this corpus: a single word)
# Process all the books (files) in order
for bo, bookinfo in bo2book.items():
CollectedItems=0
full_df=pd.DataFrame({})
book_long=bookinfo[0]
booknum=bookinfo[1]
book_short=bookinfo[2]
InputFile = os.path.join(InputDir, f'{bo}.xml')
OutputFile = os.path.join(OutputDir, f'{bo}.pkl')
print(f'Processing {book_long} at {InputFile}')
# Send the loaded XML document to the parsing routine
tree = ET.parse(InputFile)
# Now add all the parent info to the nodes in the XML tree [this step is important!]
addParentInfo(tree.getroot())
start_time = time.time()
# Walk over all the leaves and harvest the data
for elem in tree.iter():
if not list(elem):
# If no child elements exist, this must be a leaf/terminal node
# Show progress on screen by printing a dot for each 100 words processed
CollectedItems+=1
if (CollectedItems%100==0): print (".",end='')
# Leafref will contain list with book, chapter verse and wordnumber
Leafref = re.sub(r'[!: ]'," ", elem.attrib.get('ref')).split()
# Push value for monad to element tree
elem.set('monad', monad)
monad+=1
# Add some important computed data to the leaf
elem.set('LeafName', elem.tag)
elem.set('word', elem.text)
elem.set('book_long', book_long)
elem.set('booknum', int(booknum))
elem.set('book_short', book_short)
elem.set('chapter', int(Leafref[1]))
elem.set('verse', int(Leafref[2]))
# The following code traces the parents up the tree and stores the discovered attributes.
parentnode=getParent(elem)
index=0
while (parentnode):
index+=1
elem.set('Parent{}Name'.format(index), parentnode.tag)
elem.set('Parent{}Type'.format(index), parentnode.attrib.get('Type'))
elem.set('Parent{}Cat'.format(index), parentnode.attrib.get('Cat'))
elem.set('Parent{}Start'.format(index), parentnode.attrib.get('Start'))
elem.set('Parent{}End'.format(index), parentnode.attrib.get('End'))
elem.set('Parent{}Rule'.format(index), parentnode.attrib.get('Rule'))
elem.set('Parent{}Head'.format(index), parentnode.attrib.get('Head'))
elem.set('Parent{}NodeId'.format(index),parentnode.attrib.get('nodeId'))
elem.set('Parent{}ClType'.format(index),parentnode.attrib.get('ClType'))
elem.set('Parent{}HasDet'.format(index),parentnode.attrib.get('HasDet'))
currentnode=parentnode
parentnode=getParent(currentnode)
elem.set('parents', int(index))
# This will push all elements found in the tree into a DataFrame
df=pd.DataFrame(elem.attrib, index={monad})
full_df=pd.concat([full_df,df])
# Store the resulting DataFrame per book into a pickle file for further processing
df = df.convert_dtypes(convert_string=True)
output = open(r"{}".format(OutputFile), 'wb')
pickle.dump(full_df, output)
output.close()
print("\nFound ",CollectedItems, " items in %s seconds\n" % (time.time() - start_time))
Part 1b: Sort the nodes ¶
Back to TOC¶
In the original node data, the word order is not the same as in the running text. This part is to sort the dataframes accordingly.
BaseDir = 'C:\\Users\\tonyj\\my_new_Jupyter_folder\\test_of_xml_etree\\'
source_dir = BaseDir+'outputfiles\\' #the input files (with 'wordjumps')
output_dir = BaseDir+'outputfiles_sorted\\' #the output files (words in order of running text)
# Process all the books (files) in order
for bo in bo2book:
'''
load all data into a dataframe
process books in order (bookinfo is a list!)
'''
InputFile = os.path.join(source_dir, f'{bo}.pkl')
OutputFile = os.path.join(output_dir, f'{bo}.pkl')
print(f'\tloading {InputFile}...')
pkl_file = open(InputFile, 'rb')
df = pickle.load(pkl_file)
pkl_file.close()
# Fill dictionary of column names for this book
IndexDict = {}
ItemsInRow=1
for itemname in df.columns.to_list():
IndexDict.update({'i_{}'.format(itemname): ItemsInRow})
ItemsInRow+=1
# Sort by id
df.sort_values(by=['nodeId'])
# Store the resulting DataFrame per book into a pickle file for further processing
output = open(r"{}".format(OutputFile), 'wb')
pickle.dump(df, output)
output.close()
Part 2: Nestle1904GBI Text-Fabric production from pickle input ¶
Back to TOC¶
This script creates the Text-Fabric files by recursive calling the TF walker function. API info: https://annotation.github.io/text-fabric/tf/convert/walker.html
The pickle files created by step 1 are stored on Github location https://github.com/tonyjurg/Nestle1904GBI/tree/main/resources/picklefiles
Step 1: Load libraries and initialize some data¶
Change BaseDir, InputDir and OutputDir to match location of the datalocation and the OS used.
import pandas as pd
import os
import re
import gc
from tf.fabric import Fabric
from tf.convert.walker import CV
from tf.parameters import VERSION
from datetime import date
import pickle
BaseDir = 'C:\\Users\\tonyj\\my_new_Jupyter_folder\\test_of_xml_etree\\'
source_dir = BaseDir+'outputfiles_sorted\\' # the input for the walker is the output of the xml to excel
#output_dir = BaseDir+'outputfilesTF\\' #the TextFabric files
output_dir = 'C:\\text-fabric-data\\github\\tonyjurg\\Nestle1904GBI\\tf'
# key: filename, [0]=book_long, [1]=book_num, [3]=book_short
bo2book = {'01-matthew': ['Matthew', '1', 'Matt'],
'02-mark': ['Mark', '2', 'Mark'],
'03-luke': ['Luke', '3', 'Luke'],
'04-john': ['John', '4', 'John'],
'05-acts': ['Acts', '5', 'Acts'],
'06-romans': ['Romans', '6', 'Rom'],
'07-1corinthians': ['I_Corinthians', '7', '1Cor'],
'08-2corinthians': ['II_Corinthians', '8', '2Cor'],
'09-galatians': ['Galatians', '9', 'Gal'],
'10-ephesians': ['Ephesians', '10', 'Eph'],
'11-philippians': ['Philippians', '11', 'Phil'],
'12-colossians': ['Colossians', '12', 'Col'],
'13-1thessalonians':['I_Thessalonians', '13', '1Thess'],
'14-2thessalonians':['II_Thessalonians','14', '2Thess'],
'15-1timothy': ['I_Timothy', '15', '1Tim'],
'16-2timothy': ['II_Timothy', '16', '2Tim'],
'17-titus': ['Titus', '17', 'Titus'],
'18-philemon': ['Philemon', '18', 'Phlm'],
'19-hebrews': ['Hebrews', '19', 'Heb'],
'20-james': ['James', '20', 'Jas'],
'21-1peter': ['I_Peter', '21', '1Pet'],
'22-2peter': ['II_Peter', '22', '2Pet'],
'23-1john': ['I_John', '23', '1John'],
'24-2john': ['II_John', '24', '2John'],
'25-3john': ['III_John', '25', '3John'],
'26-jude': ['Jude', '26', 'Jude'],
'27-revelation': ['Revelation', '27', 'Rev']}
Step 2 Running the Text-Fabric walker function¶
Text-Fabric API info can be found at https://annotation.github.io/text-fabric/tf/convert/walker.html
Explanatory notes about the data interpretation logic are incorporated within the Python code of the director function.
TF = Fabric(locations=output_dir, silent=False)
cv = CV(TF)
version = "0.3"
###############################################
# Common helper functions #
###############################################
# The following sanitizer function is required to prevent passing float data to the walker function
def sanitize(input):
if isinstance(input, float): return ''
else: return (input)
###############################################
# The director routine #
###############################################
def director(cv):
###############################################
# Innitial setup of data etc. #
###############################################
NoneType = type(None) # needed as tool to validate certain data
IndexDict = {} # init an empty dictionary
for bo,bookinfo in bo2book.items():
###############################################
# start of section executed for each book #
###############################################
# load all data into a dataframe and process books in order (note that bookinfo is a list)
Book=bookinfo[0]
BookNum=int(bookinfo[1])
BookShort=bookinfo[2]
BookLoc = os.path.join(source_dir, f'{bo}.pkl')
# Read data from PKL file and report progress
print(f'\tloading {BookLoc}...')
PklFile = open(BookLoc, 'rb')
df_unsorted = pickle.load(PklFile)
PklFile.close()
# Fill dictionary of column names for this book
ItemsInRow=1
for itemname in df_unsorted.columns.to_list():
IndexDict.update({'i_{}'.format(itemname): ItemsInRow})
# This is to identify the collumn containing the key to sort upon
if itemname=="{http://www.w3.org/XML/1998/namespace}id": SortKey=ItemsInRow-1
ItemsInRow+=1
df=df_unsorted.sort_values(by=df_unsorted.columns[SortKey])
del df_unsorted
# Reset/load the following initial variables (we are at the start of a new book)
phrasefunction = prev_phrasefunction = phrasefunctionlong = prev_phrasefunctionlong='TBD'
this_clausetype = this_clauserule = phrasetype="unknown"
prev_chapter = prev_verse = prev_sentence = prev_clause = prev_phrase = int(1)
sentence_track = clause_track = phrase_track = 1
sentence_done = clause_done = phrase_done = verse_done = chapter_done = book_done = False
wrdnum = 0 # start at 0
# Create a set of nodes at the start a new book
ThisBookPointer = cv.node('book')
cv.feature(ThisBookPointer, book=Book, booknum=BookNum, bookshort=BookShort)
ThisChapterPointer = cv.node('chapter')
cv.feature(ThisChapterPointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=1)
ThisVersePointer = cv.node('verse')
cv.feature(ThisVersePointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=1, verse=1)
ThisSentencePointer = cv.node('sentence')
cv.feature(ThisSentencePointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=1, verse=1, sentence=1)
ThisClausePointer = cv.node('clause')
cv.feature(ThisClausePointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=1, verse=1, sentence=1, clause=1)
ThisPhrasePointer = cv.node('phrase')
cv.feature(ThisPhrasePointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=1, verse=1, sentence=1, clause=1, phrase=1)
###############################################
# Iterate through words and construct objects #
###############################################
for row in df.itertuples():
wrdnum += 1
# Get the number of parent nodes for this word
parents = row[IndexDict.get("i_parents")]
# Get chapter and verse for this word from the data
chapter = row[IndexDict.get("i_chapter")]
verse = row[IndexDict.get("i_verse")]
# Get clause rule and type info of parent clause
for i in range(1,parents-1):
item = IndexDict.get("i_Parent{}Cat".format(i))
if row[item]=="CL":
clauseparent=i
this_clauserule=row[IndexDict.get("i_Parent{}Rule".format(i))]
this_clausetype=row[IndexDict.get("i_Parent{}ClType".format(i))]
break
cv.feature(ThisClausePointer, clause=clause_track, clauserule=this_clauserule, clausetype=this_clausetype, book=Book, booknum=BookNum, bookshort=BookShort, chapter=chapter, verse=verse)
# Get phrase type info
prev_phrasetype=phrasetype
for i in range(1,parents-1):
item = IndexDict.get("i_Parent{}Cat".format(i))
if row[item]=="np":
_item ="i_Parent{}Rule".format(i)
phrasetype=row[IndexDict.get(_item)]
break
functionaltag=row[IndexDict.get('i_FunctionalTag')]
# Determine syntactic categories of clause parts. See also the description in
# "MACULA Greek Treebank for the Nestle 1904 Greek New Testament.pdf" page 5&6
# (section 2.4 Syntactic Categories at Clause Level)
prev_phrasefunction=phrasefunction
for i in range(1,clauseparent):
phrasefunction = row[IndexDict.get("i_Parent{}Cat".format(i))]
if phrasefunction=="ADV":
phrasefunctionlong='Adverbial function'
break
elif phrasefunction=="IO":
phrasefunctionlong='Indirect Object function'
break
elif phrasefunction=="O":
phrasefunctionlong='Object function'
break
elif phrasefunction=="O2":
phrasefunctionlong='Second Object function'
break
elif phrasefunction=="S":
phrasefunctionlong='Subject function'
break
elif phrasefunction=='P':
phrasefunctionlong='Predicate function'
break
elif phrasefunction=="V":
phrasefunctionlong='Verbal function'
break
elif phrasefunction=="VC":
phrasefunctionlong='Verbal Copula function'
if prev_phrasefunction!=phrasefunction and wrdnum!=1:
phrase_done = True
# Determine syntactic categories at word level. See also the description in
# "MACULA Greek Treebank for the Nestle 1904 Greek New Testament.pdf" page 6&7
# (2.2. Syntactic Categories at Word Level: Part of Speech Labels)
sp=sanitize(row[IndexDict.get("i_Cat")])
if sp=='adj': splong='adjective'
elif sp=='adj': splong='adjective'
elif sp=='conj': splong='conjunction'
elif sp=='det': splong='determiner'
elif sp=='intj': splong='interjection'
elif sp=='noun': splong='noun'
elif sp=='num': splong='numeral'
elif sp=='prep': splong='preposition'
elif sp=='ptcl': splong='particle'
elif sp=='pron': splong='pronoun'
elif sp=='verb': splong='verb'
'''
Determine if conditions are met to trigger some action
action will be executed after next word
'''
# Detect chapter boundary
if prev_chapter != chapter:
chapter_done = True
verse_done=True
sentence_done = True
clause_done = True
phrase_done = True
# Detect verse boundary
if prev_verse != verse:
verse_done=True
'''
Handle TF events and determine what actions need to be done if proper condition is met.
'''
# Act upon end of phrase (close)
if phrase_done or clause_done or sentence_done:
cv.feature(ThisPhrasePointer, phrase=phrase_track, phrasetype=prev_phrasetype, phrasefunction=prev_phrasefunction, phrasefunctionlong=prev_phrasefunctionlong)
cv.terminate(ThisPhrasePointer)
prev_phrasefunction=phrasefunction
prev_phrasefunctionlong=phrasefunctionlong
# act upon end of clause (close)
if clause_done:
cv.terminate(ThisClausePointer)
# act upon end of sentence (close)
if sentence_done:
cv.terminate(ThisSentencePointer)
# act upon end of verse (close)
if verse_done:
cv.terminate(ThisVersePointer)
prev_verse = verse
# act upon end of chapter (close)
if chapter_done:
cv.terminate(ThisChapterPointer)
prev_chapter = chapter
# Start of chapter (create new)
if chapter_done:
ThisChapterPointer = cv.node('chapter')
cv.feature(ThisChapterPointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=chapter)
chapter_done = False
# Start of verse (create new)
if verse_done:
ThisVersePointer = cv.node('verse')
cv.feature(ThisVersePointer, book=Book, booknum=BookNum, bookshort=BookShort, chapter=chapter, verse=verse)
verse_done = False
# Start of sentence (create new)
if sentence_done:
ThisSentencePointer= cv.node('sentence')
cv.feature(ThisSentencePointer, sentence=sentence_track)
sentence_track += 1
sentence_done = False
# Start of clause (create new)
if clause_done:
ThisClausePointer = cv.node('clause')
cv.feature(ThisClausePointer, clause=clause_track, clauserule=this_clauserule,clausetype=this_clausetype)
clause_track += 1
clause_done = False
phrase_done = True
# Start of phrase (create new)
if phrase_done:
ThisPhrasePointer = cv.node('phrase')
cv.feature(ThisPhrasePointer, phrase=phrase_track, phrasefunction=phrasefunction, phrasefunctionlong=phrasefunctionlong)
prev_phrase = phrase_track
prev_phrasefunction=phrasefunction
prev_phrasefunctionlong=phrasefunctionlong
phrase_track += 1
phrase_done = False
# Detect boundaries of sentences, clauses and phrases
text=row[IndexDict.get("i_Unicode")]
if text[-1:] == "." :
sentence_done = True
clause_done = True
phrase_done = True
if text[-1:] == ";" or text[-1:] == ",":
clause_done = True
phrase_done = True
'''
-- create word nodes --
'''
# Get the word details and detect presence of punctuations
word=row[IndexDict.get("i_Unicode")]
match = re.search(r"([\.·—,;])$", word)
if match:
# The group(0) method is used to retrieve the matched punctuation sign
after=match.group(0)+' '
# Remove the punctuation from the end of the word
word=word[:-1]
else:
after=' '
# Some attributes are not present inside some (small) books. The following is to prevent exceptions.
degree=''
if 'i_Degree' in IndexDict:
degree=sanitize(row[IndexDict.get("i_Degree")])
subjref=''
if 'i_SubjRef' in IndexDict:
subjref=sanitize(row[IndexDict.get("i_SubjRef")])
# Create the word node
ThisWordPointer = cv.slot()
cv.feature(ThisWordPointer,
after=after,
word=word,
monad=row[IndexDict.get("i_monad")],
book=Book,
booknum=BookNum,
bookshort=BookShort,
chapter=chapter,
sp=sp,
splong=splong,
verse=verse,
sentence=sentence_track,
clause=clause_track,
phrase=phrase_track,
normalized=sanitize(row[IndexDict.get("i_NormalizedForm")]),
formaltag=sanitize(row[IndexDict.get("i_FormalTag")]),
functionaltag=functionaltag,
strongs=sanitize(row[IndexDict.get("i_StrongNumber")]),
lex_dom=sanitize(row[IndexDict.get("i_LexDomain")]),
ln=sanitize(row[IndexDict.get("i_LN")]),
gloss_EN=sanitize(row[IndexDict.get("i_Gloss")]),
gn=sanitize(row[IndexDict.get("i_Gender")]),
nu=sanitize(row[IndexDict.get("i_Number")]),
case=sanitize(row[IndexDict.get("i_Case")]),
lemma=sanitize(row[IndexDict.get("i_UnicodeLemma")]),
person=sanitize(row[IndexDict.get("i_Person")]),
mood=sanitize(row[IndexDict.get("i_Mood")]),
tense=sanitize(row[IndexDict.get("i_Tense")]),
number=sanitize(row[IndexDict.get("i_Number")]),
voice=sanitize(row[IndexDict.get("i_Voice")]),
degree=degree,
type=sanitize(row[IndexDict.get("i_Type")]),
reference=sanitize(row[IndexDict.get("i_Ref")]), # the capital R is critical here!
subj_ref=subjref,
nodeID=row[1] #this is a fixed position.
)
cv.terminate(ThisWordPointer)
'''
Wrap up the book. At the end of the book we need to close all nodes in proper order.
'''
# Close all nodes (phrase, clause, sentence, verse, chapter and book)
cv.feature(ThisPhrasePointer, phrase=phrase_track, phrasetype=prev_phrasetype,phrasefunction=prev_phrasefunction,phrasefunctionlong=prev_phrasefunctionlong)
cv.terminate(ThisPhrasePointer)
cv.feature(ThisClausePointer, clause=clause_track, clauserule=this_clauserule, clausetype=this_clausetype)
cv.terminate(ThisClausePointer)
cv.terminate(ThisSentencePointer)
cv.terminate(ThisVersePointer)
cv.terminate(ThisChapterPointer)
cv.terminate(ThisBookPointer)
# Clear dataframe for this book
del df
# Clear the index dictionary
IndexDict.clear()
gc.collect()
###############################################
# End of section executed for each book #
###############################################
###############################################
# End of director function #
###############################################
###############################################
# Output definitions #
###############################################
slotType = 'word' # or whatever you choose
otext = { # dictionary of config data for sections and text formats
'fmt:text-orig-full':'{word}{after}',
'sectionTypes':'book,chapter,verse',
'sectionFeatures':'book,chapter,verse',
'structureFeatures': 'book,chapter,verse',
'structureTypes': 'book,chapter,verse',
}
# Configure metadata
generic = { # dictionary of metadata which will be included in all feature files
'TextFabric version': '{}'.format(VERSION), #imported from tf.parameter
'XMLsourcelocation': 'https://github.com/tonyjurg/Nestle1904GBI/tree/main/resources/sourcedata',
'XMLversion': 'Oct 27, 2022',
'author': 'Evangelists and apostles',
'availability': 'Creative Commons Attribution 4.0 International (CC BY 4.0)',
'converter_author': 'Tony Jurg',
'converter_execution': 'Tony Jurg',
'convertor_source': 'https://github.com/tonyjurg/Nestle1904GBI/tree/main/resources/converter',
'converterversion': '{}'.format(version),
'data source': 'MACULA Greek Linguistic Datasets, available at https://github.com/Clear-Bible/macula-greek/tree/main/Nestle1904/nodes',
'editors': 'Eberhart Nestle (1904)',
'sourcedescription': 'Greek New Testment (British Foreign Bible Society, 1904)',
'sourceformat': 'XML (GBI tree node data)',
'title': 'Greek New Testament'
}
intFeatures = { # set of integer valued feature names
'booknum',
'chapter',
'verse',
'sentence',
'clause',
'phrase',
'monad'
}
featureMeta = { # per feature dicts with metadata
'after': {'description': 'Chararcter after the word (space or punctuation)'},
'book': {'description': 'Book name (fully spelled out)'},
'booknum': {'description': 'NT book number (Matthew=1, Mark=2, ..., Revelation=27)'},
'bookshort': {'description': 'Book name (abbreviated)'},
'chapter': {'description': 'Chapter number inside book'},
'verse': {'description': 'Verse number inside chapter'},
'sentence': {'description': 'Sentence number (counted per chapter)'},
'clause': {'description': 'Clause number (counted per chapter)'},
'clauserule': {'description': 'Clause rule'},
'clausetype': {'description': 'Clause type'},
'phrase' : {'description': 'Phrase number (counted per chapter)'},
'phrasetype' : {'description': 'Phrase type information'},
'phrasefunction' : {'description': 'Phrase function (abbreviated)'},
'phrasefunctionlong' : {'description': 'Phrase function (long description)'},
'monad': {'description': 'Sequence number of the smallest meaningful unit of text (single word)'},
'word': {'description': 'Word as it appears in the text'},
'sp': {'description': 'Speech Part (abbreviated)'},
'splong': {'description': 'Speech Part (long description)'},
'normalized': {'description': 'Surface word stripped of punctations'},
'lemma': {'description': 'Lexeme (lemma)'},
'formaltag': {'description': 'Formal tag (Sandborg-Petersen morphology)'},
'functionaltag': {'description': 'Functional tag (Sandborg-Petersen morphology)'},
# see also discussion on relation between lex_dom and ln @ https://github.com/Clear-Bible/macula-greek/issues/29
'lex_dom': {'description': 'Lexical domain according to Semantic Dictionary of Biblical Greek, SDBG (not present everywhere?)'},
'ln': {'description': 'Lauw-Nida lexical classification (not present everywhere)'},
'strongs': {'description': 'Strongs number'},
'gloss_EN': {'description': 'English gloss'},
'gn': {'description': 'Gramatical gender (Masculine, Feminine, Neuter)'},
'nu': {'description': 'Gramatical number (Singular, Plural)'},
'case': {'description': 'Gramatical case (Nominative, Genitive, Dative, Accusative, Vocative)'},
'person': {'description': 'Gramatical person of the verb (first, second, third)'},
'mood': {'description': 'Gramatical mood of the verb (passive, etc)'},
'tense': {'description': 'Gramatical tense of the verb (e.g. Present, Aorist)'},
'number': {'description': 'Gramatical number of the verb'},
'voice': {'description': 'Gramatical voice of the verb'},
'degree': {'description': 'Degree (e.g. Comparitative, Superlative)'},
'type': {'description': 'Gramatical type of noun or pronoun (e.g. Common, Personal)'},
'reference': {'description': 'Reference (to nodeID in XML source data, not yet post-processes)'},
'subj_ref': {'description': 'Subject reference (to nodeID in XML source data)'},
'nodeID': {'description': 'Node ID (as in the XML source data)'}
}
'''
-- The main function --
'''
good = cv.walk(
director,
slotType,
otext=otext,
generic=generic,
intFeatures=intFeatures,
featureMeta=featureMeta,
warn=True,
force=True
)
if good:
print ("done")
This is Text-Fabric 11.4.10 42 features found and 0 ignored 0.00s Importing data from walking through the source ... | 0.00s Preparing metadata... | SECTION TYPES: book, chapter, verse | SECTION FEATURES: book, chapter, verse | STRUCTURE TYPES: book, chapter, verse | STRUCTURE FEATURES: book, chapter, verse | TEXT FEATURES: | | text-orig-full after, word | 0.00s OK | 0.00s Following director... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\01-matthew.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\02-mark.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\03-luke.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\04-john.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\05-acts.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\06-romans.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\07-1corinthians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\08-2corinthians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\09-galatians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\10-ephesians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\11-philippians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\12-colossians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\13-1thessalonians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\14-2thessalonians.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\15-1timothy.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\16-2timothy.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\17-titus.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\18-philemon.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\19-hebrews.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\20-james.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\21-1peter.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\22-2peter.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\23-1john.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\24-2john.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\25-3john.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\26-jude.pkl... loading C:\Users\tonyj\my_new_Jupyter_folder\test_of_xml_etree\outputfiles_sorted\27-revelation.pkl... | 43s "edge" actions: 0 | 43s "feature" actions: 451007 | 43s "node" actions: 102748 | 43s "resume" actions: 0 | 43s "slot" actions: 137779 | 43s "terminate" actions: 240527 | 27 x "book" node | 260 x "chapter" node | 16124 x "clause" node | 72674 x "phrase" node | 5720 x "sentence" node | 7943 x "verse" node | 137779 x "word" node = slot type | 240527 nodes of all types | 44s OK | 0.00s checking for nodes and edges ... | 0.00s OK | 0.00s checking (section) features ... | 0.21s OK | 0.00s reordering nodes ... | 0.03s Sorting 27 nodes of type "book" | 0.04s Sorting 260 nodes of type "chapter" | 0.05s Sorting 16124 nodes of type "clause" | 0.09s Sorting 72674 nodes of type "phrase" | 0.18s Sorting 5720 nodes of type "sentence" | 0.20s Sorting 7943 nodes of type "verse" | 0.22s Max node = 240527 | 0.22s OK | 0.00s reassigning feature values ... | | 0.00s node feature "after" with 137779 nodes | | 0.04s node feature "book" with 162187 nodes | | 0.09s node feature "booknum" with 162187 nodes | | 0.14s node feature "bookshort" with 162187 nodes | | 0.19s node feature "case" with 137779 nodes | | 0.24s node feature "chapter" with 162160 nodes | | 0.28s node feature "clause" with 153930 nodes | | 0.34s node feature "clauserule" with 16124 nodes | | 0.34s node feature "clausetype" with 3846 nodes | | 0.35s node feature "degree" with 137779 nodes | | 0.39s node feature "formaltag" with 137779 nodes | | 0.43s node feature "functionaltag" with 137779 nodes | | 0.47s node feature "gloss_EN" with 137779 nodes | | 0.52s node feature "gn" with 137779 nodes | | 0.56s node feature "lemma" with 137779 nodes | | 0.61s node feature "lex_dom" with 137779 nodes | | 0.65s node feature "ln" with 137779 nodes | | 0.69s node feature "monad" with 137779 nodes | | 0.74s node feature "mood" with 137779 nodes | | 0.78s node feature "nodeID" with 137779 nodes | | 0.82s node feature "normalized" with 137779 nodes | | 0.87s node feature "nu" with 137779 nodes | | 0.91s node feature "number" with 137779 nodes | | 0.96s node feature "person" with 137779 nodes | | 1.00s node feature "phrase" with 210453 nodes | | 1.07s node feature "phrasefunction" with 72674 nodes | | 1.11s node feature "phrasefunctionlong" with 72674 nodes | | 1.14s node feature "phrasetype" with 72674 nodes | | 1.17s node feature "reference" with 137779 nodes | | 1.21s node feature "sentence" with 143553 nodes | | 1.26s node feature "sp" with 137779 nodes | | 1.30s node feature "splong" with 137779 nodes | | 1.34s node feature "strongs" with 137779 nodes | | 1.38s node feature "subj_ref" with 137779 nodes | | 1.43s node feature "tense" with 137779 nodes | | 1.47s node feature "type" with 137779 nodes | | 1.51s node feature "verse" with 161900 nodes | | 1.56s node feature "voice" with 137779 nodes | | 1.60s node feature "word" with 137779 nodes | 1.72s OK 0.00s Exporting 40 node and 1 edge and 1 config features to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf: 0.00s VALIDATING oslots feature 0.02s VALIDATING oslots feature 0.02s maxSlot= 137779 0.02s maxNode= 240527 0.03s OK: oslots is valid | 0.14s T after to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.16s T book to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.16s T booknum to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.16s T bookshort to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T case to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T chapter to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T clause to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.02s T clauserule to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.01s T clausetype to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T degree to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T formaltag to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T functionaltag to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T gloss_EN to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T gn to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.17s T lemma to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T lex_dom to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T ln to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.13s T monad to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T mood to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T nodeID to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.17s T normalized to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T nu to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T number to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.05s T otype to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T person to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.20s T phrase to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.08s T phrasefunction to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.08s T phrasefunctionlong to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.08s T phrasetype to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.13s T reference to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.13s T sentence to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T sp to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T splong to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T strongs to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T subj_ref to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T tense to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T type to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.15s T verse to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.14s T voice to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.16s T word to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.32s T oslots to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf | 0.00s M otext to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf 5.69s Exported 40 node features and 1 edge features and 1 config features to C:/text-fabric-data/github/tonyjurg/Nestle1904GBI/tf done