Creating Text-Fabric dataset (from LowFat XML trees)¶
Code version: 0.7 (February 20, 2024)
Data version: February 10, 2024 (Readme)
Table of content ¶
1 - Introduction ¶
Back to TOC¶
The source data for the conversion are the LowFat XML trees files representing the macula-greek version of the Nestle 1904 Greek New Testment (British Foreign Bible Society, 1904). The starting dataset is formatted according to Syntax diagram markup by the Global Bible Initiative (GBI). The most recent source data can be found on github https://github.com/Clear-Bible/macula-greek/tree/main/Nestle1904/lowfat.
Attribution: "MACULA Greek Linguistic Datasets, available at https://github.com/Clear-Bible/macula-greek/".
The production of the Text-Fabric files consist of two phases. First one is the creation of piclke files (section 2). The second phase is the the actual Text-Fabric creation process (section 3). The process can be depicted as follows:

2 - Read LowFat XML data and store in pickle ¶
Back to TOC¶
This script harvests all information from the LowFat tree data (XML nodes), puts it into a Panda DataFrame and stores the result per book in a pickle file. Note: pickling (in Python) is serialising an object into a disk file (or buffer). See also the Python3 documentation.
Within the context of this script, the term 'Leaf' refers to nodes that contain the Greek word as data. These nodes are also referred to as 'terminal nodes' since they do not have any children, similar to leaves on a tree. Additionally, Parent1 represents the parent of the leaf, Parent2 represents the parent of Parent1, and so on. For a visual representation, please refer to the following diagram.
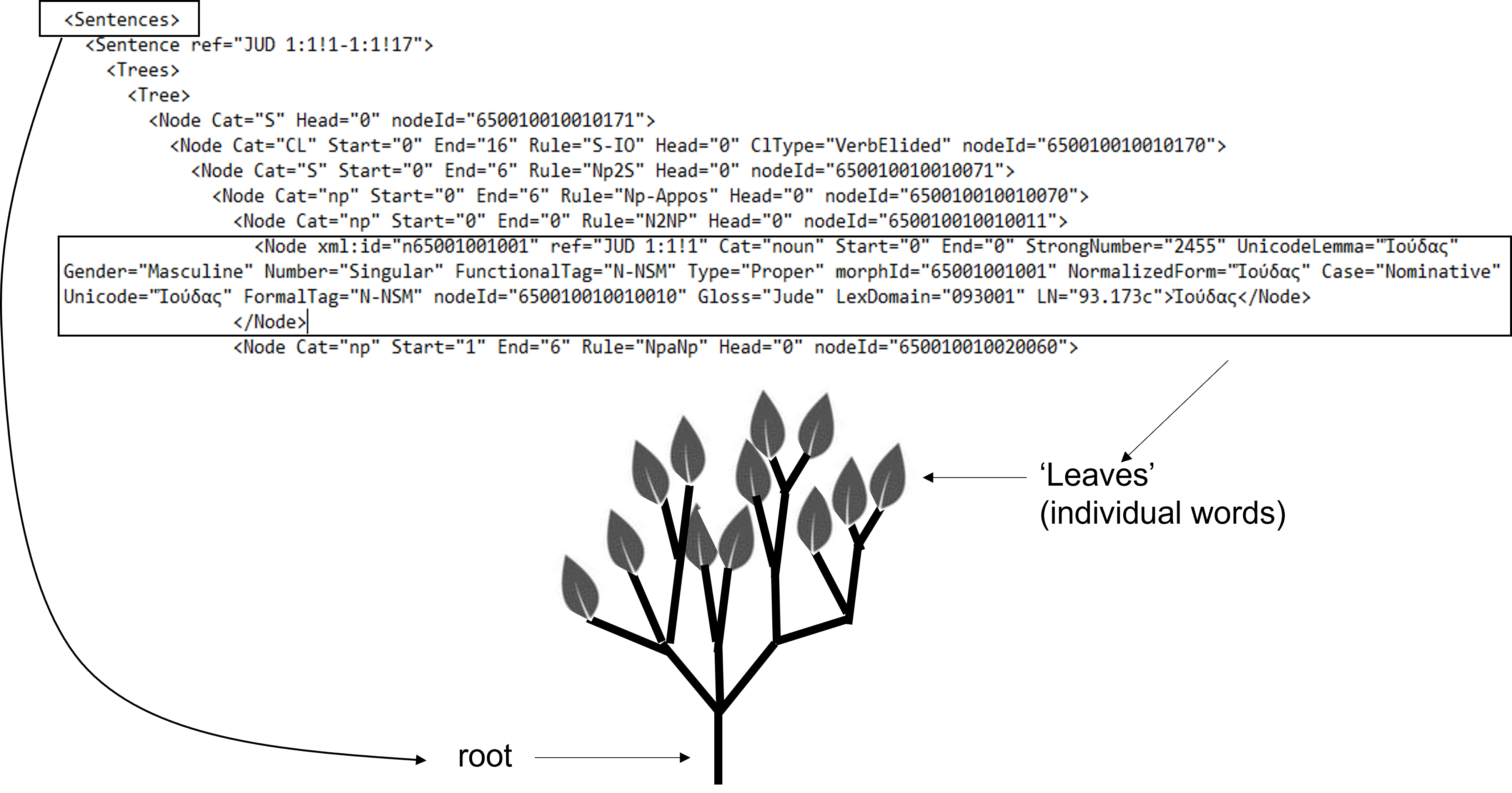
For a full description of the source data see document MACULA Greek Treebank for the Nestle 1904 Greek New Testament.pdf
2.1 Required libraries¶
Back to TOC¶
The scripts in this notebook require (beside text-fabric) a number of Python libraries to be installed in the environment (see following section).
You can install any missing library from within Jupyter Notebook using either pip or pip3. (eg.: !pip3 install pandas)
2.2 - Import various libraries¶
Back to TOC¶
The following cell reads all required libraries by the scripts in this notebook.
import pandas as pd
import sys # System
import os # Operating System
from os import listdir
from os.path import isfile, join
import time
import pickle
import re # Regular Expressions
from lxml import etree as ET
from tf.fabric import Fabric
from tf.convert.walker import CV
from tf.parameters import VERSION
from datetime import date
import pickle
import unicodedata
from unidecode import unidecode
import openpyxl
2.3 - Initialize global data¶
Back to TOC¶
The following cell initializes the global data used by the various scripts in this notebook. Many of these global variables are shared among the scripts as they relate to common entities.
IMPORTANT: To ensure proper creation of the Text-Fabric files on your system, it is crucial to adjust the values of BaseDir, XmlDir, etc. to match the location of the data and the operating system you are using. In this Jupyter Notebook, Windows is the operating system employed.
# set script version number
scriptVersion='0.7'
scriptDate='February 20, 2024'
# Define the source and destination locations
BaseDir = '..\\'
XmlDir = BaseDir+'xml\\20240210\\'
PklDir = BaseDir+'pickle\\20240210\\'
XlsxDir = BaseDir+'excel\\20240210\\'
CsvDir = BaseDir+'csv\\20240210\\'
# note: create output directory prior running the scripts!
# key: filename, [0]=bookLong, [1]=bookNum, [3]=bookShort
bo2book = {'01-matthew': ['Matthew', '1', 'Matt'],
'02-mark': ['Mark', '2', 'Mark'],
'03-luke': ['Luke', '3', 'Luke'],
'04-john': ['John', '4', 'John'],
'05-acts': ['Acts', '5', 'Acts'],
'06-romans': ['Romans', '6', 'Rom'],
'07-1corinthians': ['I_Corinthians', '7', '1Cor'],
'08-2corinthians': ['II_Corinthians', '8', '2Cor'],
'09-galatians': ['Galatians', '9', 'Gal'],
'10-ephesians': ['Ephesians', '10', 'Eph'],
'11-philippians': ['Philippians', '11', 'Phil'],
'12-colossians': ['Colossians', '12', 'Col'],
'13-1thessalonians':['I_Thessalonians', '13', '1Thess'],
'14-2thessalonians':['II_Thessalonians','14', '2Thess'],
'15-1timothy': ['I_Timothy', '15', '1Tim'],
'16-2timothy': ['II_Timothy', '16', '2Tim'],
'17-titus': ['Titus', '17', 'Titus'],
'18-philemon': ['Philemon', '18', 'Phlm'],
'19-hebrews': ['Hebrews', '19', 'Heb'],
'20-james': ['James', '20', 'Jas'],
'21-1peter': ['I_Peter', '21', '1Pet'],
'22-2peter': ['II_Peter', '22', '2Pet'],
'23-1john': ['I_John', '23', '1John'],
'24-2john': ['II_John', '24', '2John'],
'25-3john': ['III_John', '25', '3John'],
'26-jude': ['Jude', '26', 'Jude'],
'27-revelation': ['Revelation', '27', 'Rev']}
2.4 - Process the XML data and store dataframe in pickle¶
Back to TOC¶
This code processes all 27 books in the correct order. For each book, the following is done:
- create a parent-child map based upon the XML source (function buildParentMap).
- loop trough the XML source to identify 'leaf' nodes and gather information regarding all its parents (function processElement) and store the results in a datalist.
- After processing all the nodes the datalist is converted to a datframe and exported as a pickle file specific to that book.
Once the XML data is converted to PKL files, there is no need to rerun (unless the source XML data is updated).
Since the size of the pickle files can be rather large, it is advised to add the .pkl extention to the ignore list of gitHub (.gitignore)
# Create the pickle files
# Set global variables for this script
WordOrder = 1
CollectedItems = 0
###############################################
# The helper functions #
###############################################
def buildParentMap(tree):
"""
Builds a mapping of child elements to their parent elements in an XML tree.
This function is useful for cases where you need to navigate from a child element
up to its parent element, as the ElementTree API does not provide this functionality directly.
Parameters:
tree (ElementTree): An XML ElementTree object.
Returns:
dict: A dictionary where keys are child elements and values are their respective parent elements.
Usage:
To build the map:
tree = ET.parse(InputFile)
parentMap = buildParentMap(tree)
Then, whenever you need a parent of an element:
parent = getParent(someElement, parentMap)
"""
return {c: p for p in tree.iter() for c in p}
def getParent(et, parentMap):
"""
Retrieves the parent element of a given element from the parent map.
Parameters:
et (Element): The XML element whose parent is to be found.
parentMap (dict): A dictionary mapping child elements to their parents.
Returns:
Element: The parent element of the given element. Returns None if the parent is not found.
"""
return parentMap.get(et)
def processElement(elem, bookInfo, WordOrder, parentMap):
"""
Processes an XML element to extract and augment its attributes with additional data.
This function adds new attributes to an element and modifies existing ones based on the provided
book information, word order, and parent map. It also collects hierarchical information
about the element's ancestors in the XML structure.
Parameters:
elem (Element): The XML element to be processed.
bookInfo (tuple): A tuple containing information about the book (long name, book number, short name).
WordOrder (int): The order of the word in the current processing context.
parentMap (dict): A dictionary mapping child elements to their parents.
Returns:
tuple: A tuple containing the updated attributes of the element and the next word order.
"""
global CollectedItems
LeafRef = re.sub(r'[!: ]', " ", elem.attrib.get('ref')).split()
elemAttrib = dict(elem.attrib) # Create a copy of the attributes using dict()
# Adding new or modifying existing attributes
elemAttrib.update({
'wordOrder': WordOrder,
'LeafName': elem.tag,
'word': elem.text,
'bookLong': bookInfo[0],
'bookNum': int(bookInfo[1]),
'bookShort': bookInfo[2],
'chapter': int(LeafRef[1]),
'verse': int(LeafRef[2]),
'parents': 0 # Initialize 'parents' attribute
})
parentnode = getParent(elem, parentMap)
index = 0
while parentnode is not None:
index += 1
parent_attribs = {
f'Parent{index}Name': parentnode.tag,
f'Parent{index}Type': parentnode.attrib.get('type'),
f'Parent{index}Appos': parentnode.attrib.get('appositioncontainer'),
f'Parent{index}Class': parentnode.attrib.get('class'),
f'Parent{index}Rule': parentnode.attrib.get('rule'),
f'Parent{index}Role': parentnode.attrib.get('role'),
f'Parent{index}Cltype': parentnode.attrib.get('cltype'),
f'Parent{index}Unit': parentnode.attrib.get('unit'),
f'Parent{index}Junction': parentnode.attrib.get('junction'),
f'Parent{index}SN': parentnode.attrib.get('SN'),
f'Parent{index}WGN': parentnode.attrib.get('WGN')
}
elemAttrib.update(parent_attribs)
parentnode = getParent(parentnode, parentMap)
elemAttrib['parents'] = index
CollectedItems += 1
return elemAttrib, WordOrder + 1
def fixAttributeId(tree):
"""
Renames attributes in an XML tree that match the pattern '{*}id' to 'id'.
Parameters:
tree (lxml.etree._ElementTree): The XML tree to be processed.
Returns:
None: The function modifies the tree in-place and does not return anything.
"""
# Regex pattern to match attributes like '{...}id'
pattern = re.compile(r'\{.*\}id')
for element in tree.iter():
attributes_to_rename = [attr for attr in element.attrib if pattern.match(attr)]
for attr in attributes_to_rename:
element.attrib['id'] = element.attrib.pop(attr)
###############################################
# The main routine #
###############################################
# Process books
print ('Extract data from XML files and store it in pickle files')
overalTime = time.time()
for bo, bookInfo in bo2book.items():
CollectedItems = 0
SentenceNumber = 0
WordGroupNumber = 0
dataList = [] # List to store data dictionaries
InputFile = os.path.join(XmlDir, f'{bo}.xml')
OutputFile = os.path.join(PklDir, f'{bo}.pkl')
print(f'\tProcessing {bookInfo[0]} at {InputFile} ', end='')
try:
tree = ET.parse(InputFile)
fixAttributeId(tree)
parentMap = buildParentMap(tree)
except Exception as e:
print(f"Error parsing XML file {InputFile}: {e}")
continue
start_time = time.time()
for elem in tree.iter():
if elem.tag == 'sentence':
SentenceNumber += 1
elem.set('SN', str(SentenceNumber))
elif elem.tag == 'error': # workaround for one <error> node found in the source XML, which is in fact a <wg> node failing analysis
elem.tag = 'wg'
if elem.tag == 'wg':
WordGroupNumber += 1
elem.set('WGN', str(WordGroupNumber))
if elem.tag == 'w':
elemAttrib, WordOrder = processElement(elem, bookInfo, WordOrder, parentMap)
dataList.append(elemAttrib)
fullDataFrame = pd.DataFrame(dataList) # Create DataFrame once after processing all elements
# Open the file using a context manager
with open(OutputFile, 'wb') as output:
pickle.dump(fullDataFrame, output)
print(f"Found {CollectedItems} items in {time.time() - start_time:.2f} seconds.")
print(f'Finished in {time.time() - overalTime:.2f} seconds.')
Extract data from XML files and store it in pickle files Processing Matthew at ..\xml\20240210\01-matthew.xml Found 18299 items in 1.42 seconds. Processing Mark at ..\xml\20240210\02-mark.xml Found 11277 items in 0.95 seconds. Processing Luke at ..\xml\20240210\03-luke.xml Found 19456 items in 4.10 seconds. Processing John at ..\xml\20240210\04-john.xml Found 15643 items in 1.24 seconds. Processing Acts at ..\xml\20240210\05-acts.xml Found 18393 items in 1.59 seconds. Processing Romans at ..\xml\20240210\06-romans.xml Found 7100 items in 0.66 seconds. Processing I_Corinthians at ..\xml\20240210\07-1corinthians.xml Found 6820 items in 0.58 seconds. Processing II_Corinthians at ..\xml\20240210\08-2corinthians.xml Found 4469 items in 0.43 seconds. Processing Galatians at ..\xml\20240210\09-galatians.xml Found 2228 items in 0.29 seconds. Processing Ephesians at ..\xml\20240210\10-ephesians.xml Found 2419 items in 0.30 seconds. Processing Philippians at ..\xml\20240210\11-philippians.xml Found 1630 items in 0.21 seconds. Processing Colossians at ..\xml\20240210\12-colossians.xml Found 1575 items in 0.23 seconds. Processing I_Thessalonians at ..\xml\20240210\13-1thessalonians.xml Found 1473 items in 0.14 seconds. Processing II_Thessalonians at ..\xml\20240210\14-2thessalonians.xml Found 822 items in 0.11 seconds. Processing I_Timothy at ..\xml\20240210\15-1timothy.xml Found 1588 items in 0.18 seconds. Processing II_Timothy at ..\xml\20240210\16-2timothy.xml Found 1237 items in 0.28 seconds. Processing Titus at ..\xml\20240210\17-titus.xml Found 658 items in 0.14 seconds. Processing Philemon at ..\xml\20240210\18-philemon.xml Found 335 items in 0.20 seconds. Processing Hebrews at ..\xml\20240210\19-hebrews.xml Found 4955 items in 0.42 seconds. Processing James at ..\xml\20240210\20-james.xml Found 1739 items in 0.35 seconds. Processing I_Peter at ..\xml\20240210\21-1peter.xml Found 1676 items in 0.38 seconds. Processing II_Peter at ..\xml\20240210\22-2peter.xml Found 1098 items in 0.21 seconds. Processing I_John at ..\xml\20240210\23-1john.xml Found 2136 items in 0.33 seconds. Processing II_John at ..\xml\20240210\24-2john.xml Found 245 items in 0.14 seconds. Processing III_John at ..\xml\20240210\25-3john.xml Found 219 items in 0.13 seconds. Processing Jude at ..\xml\20240210\26-jude.xml Found 457 items in 0.13 seconds. Processing Revelation at ..\xml\20240210\27-revelation.xml Found 9832 items in 0.87 seconds. Finished in 18.58 seconds.
3 - Optionaly export to aid investigation¶
Back to TOC¶
This step is optional. It will allow for manual examining the input data to the Text-Fabric conversion script.
3.1 - Export to Excel format¶
Back to TOC¶
Warning: Exporting of pandas dataframes to Excel format is very slow.
# Pre-construct the base paths for input and output since they remain constant
baseInputPath = os.path.join(PklDir, '{}.pkl')
baseOutputPath = os.path.join(XlsxDir, '{}.xlsx')
print('Exporting Pickle files to Excel format. Please be patient. This export takes significant time')
overalTime = time.time()
errorCondition=False
for directory in (PklDir,XlsxDir):
if not os.path.exists(directory):
print(f"Script aborted. The directory '{directory}' does not exist.")
errorCondition=True
# Load books in order
if not errorCondition:
for bo in bo2book:
startTime = time.time()
# Use formatted strings for file names
inputFile = baseInputPath.format(bo)
outputFile = baseOutputPath.format(bo)
print(f'\tProcessing {inputFile} ...', end='')
# Use context manager for reading pickle file
with open(inputFile, 'rb') as pklFile:
df = pickle.load(pklFile)
# Export to Excel
df.to_excel(outputFile, index=False)
# Print the time taken for processing
print(f' done in {time.time() - startTime:.2f} seconds.')
print(f'Finished in {time.time() - overalTime:.2f} seconds.')
Please be patient. This export takes significant time loading ..\pickle\20240210\01-matthew.pkl... done in 44.67 seconds. loading ..\pickle\20240210\02-mark.pkl... done in 29.77 seconds. loading ..\pickle\20240210\03-luke.pkl... done in 397.39 seconds. loading ..\pickle\20240210\04-john.pkl... done in 36.17 seconds. loading ..\pickle\20240210\05-acts.pkl... done in 108.53 seconds. loading ..\pickle\20240210\06-romans.pkl... done in 23.14 seconds. loading ..\pickle\20240210\07-1corinthians.pkl... done in 18.10 seconds. loading ..\pickle\20240210\08-2corinthians.pkl... done in 11.85 seconds. loading ..\pickle\20240210\09-galatians.pkl... done in 5.26 seconds. loading ..\pickle\20240210\10-ephesians.pkl... done in 8.84 seconds. loading ..\pickle\20240210\11-philippians.pkl... done in 3.85 seconds. loading ..\pickle\20240210\12-colossians.pkl... done in 4.56 seconds. loading ..\pickle\20240210\13-1thessalonians.pkl... done in 5.08 seconds. loading ..\pickle\20240210\14-2thessalonians.pkl... done in 1.85 seconds. loading ..\pickle\20240210\15-1timothy.pkl... done in 4.43 seconds. loading ..\pickle\20240210\16-2timothy.pkl... done in 4.54 seconds. loading ..\pickle\20240210\17-titus.pkl... done in 3.28 seconds. loading ..\pickle\20240210\18-philemon.pkl... done in 0.70 seconds. loading ..\pickle\20240210\19-hebrews.pkl... done in 11.67 seconds. loading ..\pickle\20240210\20-james.pkl... done in 4.99 seconds. loading ..\pickle\20240210\21-1peter.pkl... done in 5.59 seconds. loading ..\pickle\20240210\22-2peter.pkl... done in 2.38 seconds. loading ..\pickle\20240210\23-1john.pkl... done in 4.89 seconds. loading ..\pickle\20240210\24-2john.pkl... done in 0.47 seconds. loading ..\pickle\20240210\25-3john.pkl... done in 0.34 seconds. loading ..\pickle\20240210\26-jude.pkl... done in 0.98 seconds. loading ..\pickle\20240210\27-revelation.pkl... done in 25.78 seconds. Finished in 769.16 seconds.
3.2 - Export to CSV format¶
Back to TOC¶
Exporting the pandas datframes to CSV format is fast. This file can easily be loaded into excel.
# Pre-construct the base paths for input and output since they remain constant
baseInputPath = os.path.join(PklDir, '{}.pkl')
baseOutputPath = os.path.join(CsvDir, '{}.csv')
print ('Exporting pickle files to CSV formated files')
overalTime = time.time()
errorCondition=False
for directory in (PklDir,CsvDir):
if not os.path.exists(directory):
print(f"Script aborted. The directory '{directory}' does not exist.")
errorCondition=True
# Load books in order
if not errorCondition:
for bo in bo2book:
start_time = time.time()
# Use formatted strings for file names
inputFile = baseInputPath.format(bo)
outputFile = baseOutputPath.format(bo)
print(f'\tProcessing {inputFile} ...', end='')
try:
with open(inputFile, 'rb') as pklFile:
df = pickle.load(pklFile)
df.to_csv(outputFile, index=False)
print(f' done in {time.time() - start_time:.2f} seconds.')
except pickle.UnpicklingError as e:
print(f"\n\tError while loading {inputFile}: {e}")
continue
print(f'\nFinished in {time.time() - overalTime:.2f} seconds.')
Exporting pickle files to CSV formated files Processing ..\pickle\20240210\01-matthew.pkl ... done in 0.68 seconds. Processing ..\pickle\20240210\02-mark.pkl ... done in 0.45 seconds. Processing ..\pickle\20240210\03-luke.pkl ... done in 5.76 seconds. Processing ..\pickle\20240210\04-john.pkl ... done in 0.82 seconds. Processing ..\pickle\20240210\05-acts.pkl ... done in 0.92 seconds. Processing ..\pickle\20240210\06-romans.pkl ... done in 0.87 seconds. Processing ..\pickle\20240210\07-1corinthians.pkl ... done in 0.79 seconds. Processing ..\pickle\20240210\08-2corinthians.pkl ... done in 0.45 seconds. Processing ..\pickle\20240210\09-galatians.pkl ... done in 0.22 seconds. Processing ..\pickle\20240210\10-ephesians.pkl ... done in 0.34 seconds. Processing ..\pickle\20240210\11-philippians.pkl ... done in 0.20 seconds. Processing ..\pickle\20240210\12-colossians.pkl ... done in 0.08 seconds. Processing ..\pickle\20240210\13-1thessalonians.pkl ... done in 0.06 seconds. Processing ..\pickle\20240210\14-2thessalonians.pkl ... done in 0.04 seconds. Processing ..\pickle\20240210\15-1timothy.pkl ... done in 0.08 seconds. Processing ..\pickle\20240210\16-2timothy.pkl ... done in 0.08 seconds. Processing ..\pickle\20240210\17-titus.pkl ... done in 0.03 seconds. Processing ..\pickle\20240210\18-philemon.pkl ... done in 0.01 seconds. Processing ..\pickle\20240210\19-hebrews.pkl ... done in 0.19 seconds. Processing ..\pickle\20240210\20-james.pkl ... done in 0.06 seconds. Processing ..\pickle\20240210\21-1peter.pkl ... done in 0.10 seconds. Processing ..\pickle\20240210\22-2peter.pkl ... done in 0.04 seconds. Processing ..\pickle\20240210\23-1john.pkl ... done in 0.06 seconds. Processing ..\pickle\20240210\24-2john.pkl ... done in 0.01 seconds. Processing ..\pickle\20240210\25-3john.pkl ... done in 0.01 seconds. Processing ..\pickle\20240210\26-jude.pkl ... done in 0.02 seconds. Processing ..\pickle\20240210\27-revelation.pkl ... done in 0.40 seconds. Finished in 12.77 seconds.
4 - Text-Fabric dataset production from pickle input¶
Back to TOC¶
4.1 - Explanation¶
Back to TOC¶
This script creates the Text-Fabric files by recursive calling the TF walker function. API info: https://annotation.github.io/text-fabric/tf/convert/walker.html
The pickle files created by the script in section 2.3 are stored on Github location /resources/pickle.
Explanatory notes about the data interpretation logic are incorporated within the Python code of the director function.
4.2 - Running the TF walker function¶
Back to TOC¶
# Load specific set of variables for the walker
from tf.fabric import Fabric
from tf.convert.walker import CV
# setting some TF specific variables
BASE = os.path.expanduser('~/github')
ORG = 'tonyjurg'
REPO = 'Nestle1904LFT'
RELATIVE = 'tf'
TF_DIR = os.path.expanduser(f'{BASE}//{ORG}//{REPO}//{RELATIVE}')
VERSION = f'{scriptVersion}'
TF_PATH = f'{TF_DIR}//{VERSION}'
TF = Fabric(locations=TF_PATH, silent=False)
cv = CV(TF)
This is Text-Fabric 12.2.2 58 features found and 0 ignored
###############################################
# Common helper functions #
###############################################
def sanitize(input):
"""
Sanitizes the input data to handle missing or undefined values.
This function is used to ensure that float values and None types are converted to empty strings.
Other data types are returned as-is. This is particularly useful in data processing and conversion
tasks where missing data needs to be handled gracefully.
Parameters:
input: The data input which can be of any type.
Returns:
str: An empty string if the input is a float or None, otherwise returns the input as-is.
"""
if isinstance(input, float) or isinstance(input, type(None)):
return ''
else:
return input
def ExpandRole(input):
"""
Expands syntactic role abbreviations into their full descriptive names.
This function is particularly useful in parsing and interpreting syntactic structures, especially
in the context of language processing. The expansion is based on the syntactic categories at the clause
level as described in "MACULA Greek Treebank for the Nestle 1904 Greek New Testament" (page 5 & 6, section 2.4).
Parameters:
input (str): Abbreviated syntactic role label.
Returns:
str: The expanded, full descriptive name of the syntactic role. Returns an empty string for unrecognized inputs.
"""
roleExpansions = {
"adv": 'Adverbial',
"io": 'Indirect Object',
"o": 'Object',
"o2": 'Second Object',
"s": 'Subject',
"p": 'Predicate',
"v": 'Verbal',
"vc": 'Verbal Copula',
"aux": 'Auxiliar'
}
return roleExpansions.get(input, '')
def ExpandSP(input):
"""
Expands Part of Speech (POS) label abbreviations into their full descriptive names.
This function is utilized for enriching text data with clear, descriptive POS labels.
The expansions are based on the syntactic categories at the word level as described in
"MACULA Greek Treebank for the Nestle 1904 Greek New Testament" (page 6 & 7, section 2.2).
Parameters:
input (str): Abbreviated POS label.
Returns:
str: The expanded, full descriptive name of the POS label. Returns an empty string for unrecognized inputs.
"""
posExpansions = {
'adj': 'Adjective',
'conj': 'Conjunction',
'det': 'Determiner',
'intj': 'Interjection',
'noun': 'Noun',
'num': 'Numeral',
'prep': 'Preposition',
'ptcl': 'Particle',
'pron': 'Pronoun',
'verb': 'Verb'
}
return posExpansions.get(input, '')
def removeAccents(text):
"""
Removes diacritical marks (accents) from Greek words or any text.
This function is particularly useful in text processing where diacritical marks need to be
removed, such as in search functionality, normalization, or comparison of strings. It leverages
Unicode normalization to decompose characters into their base characters and diacritics, and then
filters out the diacritics.
Note: This function can be applied to any text where Unicode normalization is applicable.
Parameters:
text (str): The text from which accents/diacritical marks need to be removed.
Returns:
str: The input text with all diacritical marks removed.
"""
return ''.join(c for c in unicodedata.normalize('NFD', text) if unicodedata.category(c) != 'Mn')
###############################################
# The director routine #
###############################################
def director(cv):
###############################################
# Innitial setup of data etc. #
###############################################
NoneType = type(None) # needed as tool to validate certain data
IndexDict = {} # init an empty dictionary
WordGroupDict={} # init a dummy dictionary
PrevWordGroupSet = WordGroupSet = []
PrevWordGroupList = WordGroupList = []
RootWordGroup = 0
WordNumber=FoundWords=WordGroupTrack=0
# The following is required to recover succesfully from an abnormal condition
# in the LowFat tree data where a <wg> element is labeled as <error>
# this number is arbitrary but should be high enough not to clash with 'real' WG numbers
DummyWGN=200000 # first dummy WG number
# Following variables are used for textual critical data
criticalMarkCharacters = "[]()—"
punctuationCharacters = ",.;·"
translationTableMarkers = str.maketrans("", "", criticalMarkCharacters)
translationTablePunctuations = str.maketrans("", "", punctuationCharacters)
punctuations=('.',',',';','·')
for bo,bookinfo in bo2book.items():
###############################################
# start of section executed for each book #
###############################################
# note: bookinfo is a list! Split the data
Book = bookinfo[0]
BookNumber = int(bookinfo[1])
BookShort = bookinfo[2]
BookLoc = os.path.join(PklDir, f'{bo}.pkl')
# load data for this book into a dataframe.
# make sure wordorder is correct
print(f'\tWe are loading {BookLoc}...')
pkl_file = open(BookLoc, 'rb')
df_unsorted = pickle.load(pkl_file)
pkl_file.close()
'''
Fill dictionary of column names for this book
sort to ensure proper wordorder
'''
ItemsInRow=1
for itemName in df_unsorted.columns.to_list():
IndexDict.update({'i_{}'.format(itemName): ItemsInRow})
# This is to identify the collumn containing the key to sort upon
if itemName=="id": SortKey=ItemsInRow-1
ItemsInRow+=1
df=df_unsorted.sort_values(by=df_unsorted.columns[SortKey])
del df_unsorted
# Set up nodes for new book
ThisBookPointer = cv.node('book')
cv.feature(ThisBookPointer, book=Book, booknumber=BookNumber, bookshort=BookShort)
ThisChapterPointer = cv.node('chapter')
cv.feature(ThisChapterPointer, chapter=1, book=Book)
PreviousChapter=1
ThisVersePointer = cv.node('verse')
cv.feature(ThisVersePointer, verse=1, chapter=1, book=Book)
PreviousVerse=1
ThisSentencePointer = cv.node('sentence')
cv.feature(ThisSentencePointer, sentence=1, headverse=1, chapter=1, book=Book)
PreviousSentence=1
###############################################
# Iterate through words and construct objects #
###############################################
for row in df.itertuples():
WordNumber += 1
FoundWords +=1
# Detect and act upon changes in sentences, verse and chapter
# the order of terminating and creating the nodes is critical:
# close verse - close chapter - open chapter - open verse
NumberOfParents = sanitize(row[IndexDict.get("i_parents")])
ThisSentence=int(row[IndexDict.get("i_Parent{}SN".format(NumberOfParents-1))])
ThisVerse = sanitize(row[IndexDict.get("i_verse")])
ThisChapter = sanitize(row[IndexDict.get("i_chapter")])
if (ThisVerse!=PreviousVerse):
cv.terminate(ThisVersePointer)
if (ThisSentence!=PreviousSentence):
cv.terminate(ThisSentencePointer)
if (ThisChapter!=PreviousChapter):
cv.terminate(ThisChapterPointer)
PreviousChapter = ThisChapter
ThisChapterPointer = cv.node('chapter')
cv.feature(ThisChapterPointer, chapter=ThisChapter, book=Book)
if (ThisVerse!=PreviousVerse):
PreviousVerse = ThisVerse
ThisVersePointer = cv.node('verse')
cv.feature(ThisVersePointer, verse=ThisVerse, chapter=ThisChapter, book=Book)
if (ThisSentence!=PreviousSentence):
PreviousSentence=ThisSentence
ThisSentencePointer = cv.node('sentence')
cv.feature(ThisSentencePointer, sentence=ThisSentence, headverse=ThisVerse, chapter=ThisChapter, book=Book)
###############################################
# analyze and process <WG> tags #
###############################################
PrevWordGroupList=WordGroupList
WordGroupList=[] # stores current active WordGroup numbers
for i in range(NumberOfParents-2,0,-1): # important: reversed itteration!
_WGN=int(row[IndexDict.get("i_Parent{}WGN".format(i))])
if _WGN!='':
WGN=int(_WGN)
if WGN!='':
WGclass=sanitize(row[IndexDict.get("i_Parent{}Class".format(i))])
WGrule=sanitize(row[IndexDict.get("i_Parent{}Rule".format(i))])
WGtype=sanitize(row[IndexDict.get("i_Parent{}Type".format(i))])
if WGclass==WGrule==WGtype=='':
WGclass='empty'
else:
#print ('---',WordGroupList)
if WGN not in WordGroupList:
WordGroupList.append(WGN)
#print(f'append WGN={WGN}')
WordGroupDict[(WGN,0)]=WGN
if WGrule[-2:]=='CL' and WGclass=='':
WGclass='cl*' # to simulate the way Logos presents this condition
WordGroupDict[(WGN,6)]=WGclass
WordGroupDict[(WGN,1)]=WGrule
WordGroupDict[(WGN,8)]=WGtype
WordGroupDict[(WGN,3)]=sanitize(row[IndexDict.get("i_Parent{}Junction".format(i))])
WordGroupDict[(WGN,2)]=sanitize(row[IndexDict.get("i_Parent{}Cltype".format(i))])
WordGroupDict[(WGN,7)]=sanitize(row[IndexDict.get("i_Parent{}Role".format(i))])
WordGroupDict[(WGN,9)]=sanitize(row[IndexDict.get("i_Parent{}Appos".format(i))]) # appos is not pressent any more in the newer dataset. kept here for the time being...
WordGroupDict[(WGN,10)]=NumberOfParents-1-i # = number of parent wordgroups
if not PrevWordGroupList==WordGroupList:
#print ('##',PrevWordGroupList,WordGroupList,NumberOfParents)
if RootWordGroup != WordGroupList[0]:
RootWordGroup = WordGroupList[0]
SuspendableWordGoupList = []
# we have a new sentence. rebuild suspendable wordgroup list
# some cleaning of data may be added here to save on memmory...
#for k in range(6): del WordGroupDict[item,k]
for item in reversed(PrevWordGroupList):
if (item not in WordGroupList):
# CLOSE/SUSPEND CASE
SuspendableWordGoupList.append(item)
#print ('\n close: '+str(WordGroupDict[(item,0)])+' '+ WordGroupDict[(item,6)]+' '+ WordGroupDict[(item,1)]+' '+WordGroupDict[(item,8)],end=' ')
cv.terminate(WordGroupDict[(item,4)])
for item in WordGroupList:
if (item not in PrevWordGroupList):
if (item in SuspendableWordGoupList):
# RESUME CASE
#print ('\n resume: '+str(WordGroupDict[(item,0)])+' '+ WordGroupDict[(item,6)]+' '+WordGroupDict[(item,1)]+' '+WordGroupDict[(item,8)],end=' ')
cv.resume(WordGroupDict[(item,4)])
else:
# CREATE CASE
#print ('\n create: '+str(WordGroupDict[(item,0)])+' '+ WordGroupDict[(item,6)]+' '+ WordGroupDict[(item,1)]+' '+WordGroupDict[(item,8)],end=' ')
WordGroupDict[(item,4)]=cv.node('wg')
WordGroupDict[(item,5)]=WordGroupTrack
WordGroupTrack += 1
cv.feature(WordGroupDict[(item,4)], wgnum=WordGroupDict[(item,0)], junction=WordGroupDict[(item,3)],
clausetype=WordGroupDict[(item,2)], wgrule=WordGroupDict[(item,1)], wgclass=WordGroupDict[(item,6)],
wgrole=WordGroupDict[(item,7)],wgrolelong=ExpandRole(WordGroupDict[(item,7)]),
wgtype=WordGroupDict[(item,8)],wglevel=WordGroupDict[(item,10)])
# These roles are performed either by a WG or just a single word.
Role=row[IndexDict.get("i_role")]
ValidRoles=["adv","io","o","o2","s","p","v","vc","aux"]
DistanceToRoleClause=0
if isinstance (Role,str) and Role in ValidRoles:
# Role is assign to this word (uniqely)
WordRole=Role
WordRoleLong=ExpandRole(WordRole)
else:
# Role details needs to be taken from some uptree wordgroup
WordRole=WordRoleLong=''
for item in range(1,NumberOfParents-1):
Role = sanitize(row[IndexDict.get("i_Parent{}Role".format(item))])
if isinstance (Role,str) and Role in ValidRoles:
WordRole=Role
WordRoleLong=ExpandRole(WordRole)
DistanceToRoleClause=item
break
# Find the number of the WG containing the clause definition
for item in range(1,NumberOfParents-1):
WGrule = sanitize(row[IndexDict.get("i_Parent{}Rule".format(item))])
if row[IndexDict.get("i_Parent{}Class".format(item))]=='cl' or WGrule[-2:]=='CL':
ContainedClause=sanitize(row[IndexDict.get("i_Parent{}WGN".format(item))])
break
###############################################
# analyze and process <W> tags #
###############################################
# Determine syntactic categories at word level.
PartOfSpeech=sanitize(row[IndexDict.get("i_class")])
PartOfSpeechFull=ExpandSP(PartOfSpeech)
# The folling part of code reproduces feature 'word' and 'after' that are
# currently containing incorrect data in a few specific cases.
# See https://github.com/tonyjurg/Nestle1904LFT/blob/main/resources/identifying_odd_afters.ipynb
# Get the word details and detect presence of punctuations
# it also creates the textual critical features
rawWord=sanitize(row[IndexDict.get("i_unicode")])
cleanWord= rawWord.translate(translationTableMarkers)
rawWithoutPunctuations=rawWord.translate(translationTablePunctuations)
markBefore=markAfter=PunctuationMarkOrder=''
if cleanWord[-1] in punctuations:
punctuation=cleanWord[-1]
after=punctuation+' '
word=cleanWord[:-1]
else:
after=' '
word=cleanWord
punctuation=''
if rawWithoutPunctuations!=word:
markAfter=markBefore=''
if rawWord.find(word)==0:
markAfter=rawWithoutPunctuations.replace(word,"")
if punctuation!='':
if rawWord.find(markAfter)-rawWord.find(punctuation)>0:
PunctuationMarkOrder="3" # punct. before mark
else:
PunctuationMarkOrder="2" # punct. after mark.
else:
PunctuationMarkOrder="1" #no punctuation, mark after word
else:
markBefore=rawWithoutPunctuations.replace(word,"")
PunctuationMarkOrder="0" #mark is before word
# Some attributes are not present inside some (small) books. The following is to prevent exceptions.
degree=''
if 'i_degree' in IndexDict:
degree=sanitize(row[IndexDict.get("i_degree")])
subjref=''
if 'i_subjref' in IndexDict:
subjref=sanitize(row[IndexDict.get("i_subjref")])
# Create the word slots
this_word = cv.slot()
cv.feature(this_word,
after= after,
unicode= rawWord,
word= word,
wordtranslit= unidecode(word),
wordunacc= removeAccents(word),
punctuation= punctuation,
markafter= markAfter,
markbefore= markBefore,
markorder= PunctuationMarkOrder,
monad= FoundWords,
orig_order= sanitize(row[IndexDict.get("i_wordOrder")]),
book= Book,
booknumber= BookNumber,
bookshort= BookShort,
chapter= ThisChapter,
ref= sanitize(row[IndexDict.get("i_ref")]),
sp= PartOfSpeech,
sp_full= PartOfSpeechFull,
verse= ThisVerse,
sentence= ThisSentence,
normalized= sanitize(row[IndexDict.get("i_normalized")]),
morph= sanitize(row[IndexDict.get("i_morph")]),
strongs= sanitize(row[IndexDict.get("i_strong")]),
lex_dom= sanitize(row[IndexDict.get("i_domain")]),
ln= sanitize(row[IndexDict.get("i_ln")]),
gloss= sanitize(row[IndexDict.get("i_gloss")]),
gn= sanitize(row[IndexDict.get("i_gender")]),
nu= sanitize(row[IndexDict.get("i_number")]),
case= sanitize(row[IndexDict.get("i_case")]),
lemma= sanitize(row[IndexDict.get("i_lemma")]),
person= sanitize(row[IndexDict.get("i_person")]),
mood= sanitize(row[IndexDict.get("i_mood")]),
tense= sanitize(row[IndexDict.get("i_tense")]),
number= sanitize(row[IndexDict.get("i_number")]),
voice= sanitize(row[IndexDict.get("i_voice")]),
degree= degree,
type= sanitize(row[IndexDict.get("i_type")]),
reference= sanitize(row[IndexDict.get("i_ref")]),
subj_ref= subjref,
nodeID= sanitize(row[IndexDict.get("i_id")]),
wordrole= WordRole,
wordrolelong= WordRoleLong,
wordlevel= NumberOfParents-1,
roleclausedistance = DistanceToRoleClause,
containedclause = ContainedClause
)
cv.terminate(this_word)
'''
wrap up the book. At the end of the book we need to close all nodes in proper order.
'''
# close all open WordGroup nodes
for item in WordGroupList:
#cv.feature(WordGroupDict[(item,4)], add some stats?)
cv.terminate(WordGroupDict[item,4])
cv.terminate(ThisSentencePointer)
cv.terminate(ThisVersePointer)
cv.terminate(ThisChapterPointer)
cv.terminate(ThisBookPointer)
# clear dataframe for this book, clear the index dictionary
del df
IndexDict.clear()
#gc.collect()
###############################################
# end of section executed for each book #
###############################################
###############################################
# end of director function #
###############################################
###############################################
# Output definitions #
###############################################
# define TF dataset granularity
slotType = 'word'
# dictionary of config data for sections and text formats
otext = {
'fmt:text-orig-full': '{word}{after}',
'fmt:text-normalized': '{normalized}{after}',
'fmt:text-unaccented': '{wordunacc}{after}',
'fmt:text-transliterated':'{wordtranslit}{after}',
'fmt:text-critical': '{unicode} ',
'sectionTypes':'book,chapter,verse',
'sectionFeatures':'book,chapter,verse',
'structureFeatures': 'book,chapter,verse',
'structureTypes': 'book,chapter,verse',
}
# configure provenance metadata
generic = { # dictionary of metadata meant for all features
'textFabricVersion': '{}'.format(VERSION), #imported from tf.parameter
'xmlSourceLocation': 'https://github.com/tonyjurg/Nestle1904LFT/tree/main/resources/xml/20240210',
'xmlSourceDate': 'February 10, 2024',
'author': 'Evangelists and apostles',
'availability': 'Creative Commons Attribution 4.0 International (CC BY 4.0)',
'converters': 'Tony Jurg',
'converterSource': 'https://github.com/tonyjurg/Nestle1904LFT/tree/main/resources/converter',
'converterVersion': '{} ({})'.format(scriptVersion,scriptDate),
'dataSource': 'MACULA Greek Linguistic Datasets, available at https://github.com/Clear-Bible/macula-greek/tree/main/Nestle1904/nodes',
'editors': 'Eberhart Nestle (1904)',
'sourceDescription': 'Greek New Testment (British Foreign Bible Society, 1904)',
'sourceFormat': 'XML (Low Fat tree XML data)',
'title': 'Greek New Testament (Nestle1904LFT)'
}
# set datatype of feature (if not listed here, they are ususaly strings)
intFeatures = {
'booknumber',
'chapter',
'verse',
'sentence',
'wgnum',
'orig_order',
'monad',
'wglevel'
}
# per feature dicts with metadata
# icon provides guidance on feature maturity (✅ = trustworthy, 🆗 = usable, ⚠️ = be carefull when using)
featureMeta = {
'after': {'description': '✅ Characters (eg. punctuations) following the word'},
'book': {'description': '✅ Book name (in English language)'},
'booknumber': {'description': '✅ NT book number (Matthew=1, Mark=2, ..., Revelation=27)'},
'bookshort': {'description': '✅ Book name (abbreviated)'},
'chapter': {'description': '✅ Chapter number inside book'},
'verse': {'description': '✅ Verse number inside chapter'},
'headverse': {'description': '✅ Start verse number of a sentence'},
'sentence': {'description': '✅ Sentence number (counted per chapter)'},
'type': {'description': '✅ Wordgroup type information (e.g.verb, verbless, elided, minor)'},
'wgrule': {'description': '✅ Wordgroup rule information (e.g. Np-Appos, ClCl2, PrepNp)'},
'orig_order': {'description': '✅ Word order (in source XML file)'},
'monad': {'description': '✅ Monad (smallest token matching word order in the corpus)'},
'word': {'description': '✅ Word as it appears in the text (excl. punctuations)'},
'wordtranslit':{'description': '🆗 Transliteration of the text (in latin letters, excl. punctuations)'},
'wordunacc': {'description': '✅ Word without accents (excl. punctuations)'},
'unicode': {'description': '✅ Word as it apears in the text in Unicode (incl. punctuations)'},
'punctuation': {'description': '✅ Punctuation after word'},
'markafter': {'description': '🆗 Text critical marker after word'},
'markbefore': {'description': '🆗 Text critical marker before word'},
'markorder': {'description': ' Order of punctuation and text critical marker'},
'ref': {'description': '✅ Value of the ref ID (taken from XML sourcedata)'},
'sp': {'description': '✅ Part of Speech (abbreviated)'},
'sp_full': {'description': '✅ Part of Speech (long description)'},
'normalized': {'description': '✅ Surface word with accents normalized and trailing punctuations removed'},
'lemma': {'description': '✅ Lexeme (lemma)'},
'morph': {'description': '✅ Morphological tag (Sandborg-Petersen morphology)'},
# see also discussion on relation between lex_dom and ln
# @ https://github.com/Clear-Bible/macula-greek/issues/29
'lex_dom': {'description': '✅ Lexical domain according to Semantic Dictionary of Biblical Greek, SDBG (not present everywhere?)'},
'ln': {'description': '✅ Lauw-Nida lexical classification (not present everywhere?)'},
'strongs': {'description': '✅ Strongs number'},
'gloss': {'description': '✅ English gloss'},
'gn': {'description': '✅ Gramatical gender (Masculine, Feminine, Neuter)'},
'nu': {'description': '✅ Gramatical number (Singular, Plural)'},
'case': {'description': '✅ Gramatical case (Nominative, Genitive, Dative, Accusative, Vocative)'},
'person': {'description': '✅ Gramatical person of the verb (first, second, third)'},
'mood': {'description': '✅ Gramatical mood of the verb (passive, etc)'},
'tense': {'description': '✅ Gramatical tense of the verb (e.g. Present, Aorist)'},
'number': {'description': '✅ Gramatical number of the verb (e.g. singular, plural)'},
'voice': {'description': '✅ Gramatical voice of the verb (e.g. active,passive)'},
'degree': {'description': '✅ Degree (e.g. Comparitative, Superlative)'},
'type': {'description': '✅ Gramatical type of noun or pronoun (e.g. Common, Personal)'},
'reference': {'description': '✅ Reference (to nodeID in XML source data, not yet post-processes)'},
'subj_ref': {'description': '🆗 Subject reference (to nodeID in XML source data, not yet post-processes)'},
'nodeID': {'description': '✅ Node ID (as in the XML source data)'},
'junction': {'description': '✅ Junction data related to a wordgroup'},
'wgnum': {'description': '✅ Wordgroup number (counted per book)'},
'wgclass': {'description': '✅ Class of the wordgroup (e.g. cl, np, vp)'},
'wgrole': {'description': '✅ Syntactical role of the wordgroup (abbreviated)'},
'wgrolelong': {'description': '✅ Syntactical role of the wordgroup (full)'},
'wordrole': {'description': '✅ Syntactical role of the word (abbreviated)'},
'wordrolelong':{'description': '✅ Syntactical role of the word (full)'},
'wgtype': {'description': '✅ Wordgroup type details (e.g. group, apposition)'},
'clausetype': {'description': '✅ Clause type details (e.g. Verbless, Minor)'},
'wglevel': {'description': '🆗 Number of the parent wordgroups for a wordgroup'},
'wordlevel': {'description': '🆗 Number of the parent wordgroups for a word'},
'roleclausedistance': {'description': '⚠️ Distance to the wordgroup defining the syntactical role of this word'},
'containedclause': {'description': '🆗 Contained clause (WG number)'}
}
###############################################
# the main function #
###############################################
good = cv.walk(
director,
slotType,
otext=otext,
generic=generic,
intFeatures=intFeatures,
featureMeta=featureMeta,
warn=True,
force=True
)
if good:
print ("done")
0.00s Importing data from walking through the source ...
| 0.00s Preparing metadata...
| SECTION TYPES: book, chapter, verse
| SECTION FEATURES: book, chapter, verse
| STRUCTURE TYPES: book, chapter, verse
| STRUCTURE FEATURES: book, chapter, verse
| TEXT FEATURES:
| | text-critical unicode
| | text-normalized after, normalized
| | text-orig-full after, word
| | text-transliterated after, wordtranslit
| | text-unaccented after, wordunacc
| 0.01s OK
| 0.00s Following director...
We are loading ..\pickle\20240210\01-matthew.pkl...
We are loading ..\pickle\20240210\02-mark.pkl...
We are loading ..\pickle\20240210\03-luke.pkl...
We are loading ..\pickle\20240210\04-john.pkl...
We are loading ..\pickle\20240210\05-acts.pkl...
We are loading ..\pickle\20240210\06-romans.pkl...
We are loading ..\pickle\20240210\07-1corinthians.pkl...
We are loading ..\pickle\20240210\08-2corinthians.pkl...
We are loading ..\pickle\20240210\09-galatians.pkl...
We are loading ..\pickle\20240210\10-ephesians.pkl...
We are loading ..\pickle\20240210\11-philippians.pkl...
We are loading ..\pickle\20240210\12-colossians.pkl...
We are loading ..\pickle\20240210\13-1thessalonians.pkl...
We are loading ..\pickle\20240210\14-2thessalonians.pkl...
We are loading ..\pickle\20240210\15-1timothy.pkl...
We are loading ..\pickle\20240210\16-2timothy.pkl...
We are loading ..\pickle\20240210\17-titus.pkl...
We are loading ..\pickle\20240210\18-philemon.pkl...
We are loading ..\pickle\20240210\19-hebrews.pkl...
We are loading ..\pickle\20240210\20-james.pkl...
We are loading ..\pickle\20240210\21-1peter.pkl...
We are loading ..\pickle\20240210\22-2peter.pkl...
We are loading ..\pickle\20240210\23-1john.pkl...
We are loading ..\pickle\20240210\24-2john.pkl...
We are loading ..\pickle\20240210\25-3john.pkl...
We are loading ..\pickle\20240210\26-jude.pkl...
We are loading ..\pickle\20240210\27-revelation.pkl...
| 21s "delete" actions: 0
| 21s "edge" actions: 0
| 21s "feature" actions: 259450
| 21s "node" actions: 121671
| 21s "resume" actions: 9626
| 21s "slot" actions: 137779
| 21s "terminate" actions: 269177
| 27 x "book" node
| 260 x "chapter" node
| 8011 x "sentence" node
| 7943 x "verse" node
| 105430 x "wg" node
| 137779 x "word" node = slot type
| 259450 nodes of all types
| 21s OK
| 0.00s checking for nodes and edges ...
| 0.00s OK
| 0.00s checking (section) features ...
| 0.18s OK
| 0.00s reordering nodes ...
| 0.00s No slot sorting needed
| 0.03s Sorting 27 nodes of type "book"
| 0.04s Sorting 260 nodes of type "chapter"
| 0.05s Sorting 8011 nodes of type "sentence"
| 0.08s Sorting 7943 nodes of type "verse"
| 0.11s Sorting 105430 nodes of type "wg"
| 0.65s Max node = 259450
| 0.65s OK
| 0.00s reassigning feature values ...
| | node feature "after" with 137779 nodes
| | node feature "book" with 154020 nodes
| | node feature "booknumber" with 137806 nodes
| | node feature "bookshort" with 137806 nodes
| | node feature "case" with 137779 nodes
| | node feature "chapter" with 153993 nodes
| | node feature "clausetype" with 105430 nodes
| | node feature "containedclause" with 137779 nodes
| | node feature "degree" with 137779 nodes
| | node feature "gloss" with 137779 nodes
| | node feature "gn" with 137779 nodes
| | node feature "headverse" with 8011 nodes
| | node feature "junction" with 105430 nodes
| | node feature "lemma" with 137779 nodes
| | node feature "lex_dom" with 137779 nodes
| | node feature "ln" with 137779 nodes
| | node feature "markafter" with 137779 nodes
| | node feature "markbefore" with 137779 nodes
| | node feature "markorder" with 137779 nodes
| | node feature "monad" with 137779 nodes
| | node feature "mood" with 137779 nodes
| | node feature "morph" with 137779 nodes
| | node feature "nodeID" with 137779 nodes
| | node feature "normalized" with 137779 nodes
| | node feature "nu" with 137779 nodes
| | node feature "number" with 137779 nodes
| | node feature "orig_order" with 137779 nodes
| | node feature "person" with 137779 nodes
| | node feature "punctuation" with 137779 nodes
| | node feature "ref" with 137779 nodes
| | node feature "reference" with 137779 nodes
| | node feature "roleclausedistance" with 137779 nodes
| | node feature "sentence" with 145790 nodes
| | node feature "sp" with 137779 nodes
| | node feature "sp_full" with 137779 nodes
| | node feature "strongs" with 137779 nodes
| | node feature "subj_ref" with 137779 nodes
| | node feature "tense" with 137779 nodes
| | node feature "type" with 137779 nodes
| | node feature "unicode" with 137779 nodes
| | node feature "verse" with 145722 nodes
| | node feature "voice" with 137779 nodes
| | node feature "wgclass" with 105430 nodes
| | node feature "wglevel" with 105430 nodes
| | node feature "wgnum" with 105430 nodes
| | node feature "wgrole" with 105430 nodes
| | node feature "wgrolelong" with 105430 nodes
| | node feature "wgrule" with 105430 nodes
| | node feature "wgtype" with 105430 nodes
| | node feature "word" with 137779 nodes
| | node feature "wordlevel" with 137779 nodes
| | node feature "wordrole" with 137779 nodes
| | node feature "wordrolelong" with 137779 nodes
| | node feature "wordtranslit" with 137779 nodes
| | node feature "wordunacc" with 137779 nodes
| 1.76s OK
23s Features ready to write
0.00s Exporting 56 node and 1 edge and 1 configuration features to ~/github/tonyjurg/Nestle1904LFT/tf/0.7:
0.00s VALIDATING oslots feature
0.02s VALIDATING oslots feature
0.02s maxSlot= 137779
0.02s maxNode= 259450
0.03s OK: oslots is valid
| 0.12s T after to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.13s T book to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T booknumber to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T bookshort to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.14s T case to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.13s T chapter to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.08s T clausetype to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T containedclause to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T degree to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T gloss to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T gn to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.01s T headverse to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T junction to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.15s T lemma to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T lex_dom to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.14s T ln to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T markafter to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T markbefore to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T markorder to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T monad to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T mood to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T morph to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T nodeID to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.14s T normalized to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T nu to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T number to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T orig_order to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.04s T otype to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T person to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T punctuation to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T ref to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T reference to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T roleclausedistance to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.13s T sentence to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T sp to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T sp_full to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T strongs to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T subj_ref to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T tense to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T type to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.14s T unicode to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T verse to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T voice to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T wgclass to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.08s T wglevel to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T wgnum to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T wgrole to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T wgrolelong to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T wgrule to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.09s T wgtype to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.14s T word to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.10s T wordlevel to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.11s T wordrole to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T wordrolelong to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.12s T wordtranslit to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.14s T wordunacc to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.37s T oslots to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
| 0.00s M otext to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
6.66s Exported 56 node features and 1 edge features and 1 config features to ~/github/tonyjurg/Nestle1904LFT/tf/0.7
done
5 - Housekeeping¶
Back to TOC¶
5.1 - Optionaly zip-up the pickle files¶
Back to TOC¶
In order to save filespace, the pickle files can be zipped. The following will zip the pickle files and remove the original file. The removal of pickle files is important if their size is too large (i.e., more than 100Mb in size), leading to issues when uploaded to gitHub. Hence it is adviced to include the .pkl extention in the ignore list (.gitignore).
# set variable if original pickle file needs to be removed or not
removeOriginal=False
import zipfile
import os
def zipTheFile(sourceFile, destinationFile, removeOriginal):
"""
Create a zip file from the specified source file and optionally remove the source file.
Parameters:
sourceFile (str) : The file path of the source file to be zipped.
destinationFile (str) : The file path for the resulting zip file.
removeOriginal (bool): If True, the source file will be deleted after zipping.
"""
# check for existance of the file to zip
if not os.path.exists(sourceFile):
print(f"\tSource file does not exist: {sourceFile}")
return False
# Get only the file name, not the full path
fileNameOnly = os.path.basename(sourceFile)
# Creating a zip file from the source file
with zipfile.ZipFile(destinationFile, 'w', zipfile.ZIP_DEFLATED) as zipArchive:
zipArchive.write(sourceFile,arcname=fileNameOnly)
# Removing the source file if required
if removeOriginal:
os.remove(sourceFile)
return True
# Pre-construct the base paths for input and output since they remain constant
baseInputPath = os.path.join(PklDir, '{}.pkl')
baseOutputPath = os.path.join(PklDir, '{}.zip')
print('Zipping up all pickle files' + (' and removing them afterwards.' if removeOriginal else '.'))
overallTime = time.time()
errorOccurred = False
# Load books in order
for bo in bo2book:
startTime = time.time()
# Use formatted strings for file names
inputFile = baseInputPath.format(bo)
outputFile = baseOutputPath.format(bo)
if not zipTheFile(inputFile, outputFile, removeOriginal):
errorOccurred = True
break
else:
print(f'\tloading {inputFile}...', end='')
print(f' Zipping done in {time.time() - startTime:.2f} seconds.')
if errorOccurred:
print("Operation aborted due to an error (are all pickle files already zipped?).")
else:
print(f'\nFinished in {time.time() - overallTime:.2f} seconds.')
Zipping up all pickle files. loading ..\pickle\20240210\01-matthew.pkl... Zipping done in 0.43 seconds. loading ..\pickle\20240210\02-mark.pkl... Zipping done in 0.26 seconds. loading ..\pickle\20240210\03-luke.pkl... Zipping done in 3.46 seconds. loading ..\pickle\20240210\04-john.pkl... Zipping done in 0.34 seconds. loading ..\pickle\20240210\05-acts.pkl... Zipping done in 0.48 seconds. loading ..\pickle\20240210\06-romans.pkl... Zipping done in 0.18 seconds. loading ..\pickle\20240210\07-1corinthians.pkl... Zipping done in 0.16 seconds. loading ..\pickle\20240210\08-2corinthians.pkl... Zipping done in 0.10 seconds. loading ..\pickle\20240210\09-galatians.pkl... Zipping done in 0.05 seconds. loading ..\pickle\20240210\10-ephesians.pkl... Zipping done in 0.07 seconds. loading ..\pickle\20240210\11-philippians.pkl... Zipping done in 0.04 seconds. loading ..\pickle\20240210\12-colossians.pkl... Zipping done in 0.04 seconds. loading ..\pickle\20240210\13-1thessalonians.pkl... Zipping done in 0.03 seconds. loading ..\pickle\20240210\14-2thessalonians.pkl... Zipping done in 0.02 seconds. loading ..\pickle\20240210\15-1timothy.pkl... Zipping done in 0.04 seconds. loading ..\pickle\20240210\16-2timothy.pkl... Zipping done in 0.04 seconds. loading ..\pickle\20240210\17-titus.pkl... Zipping done in 0.02 seconds. loading ..\pickle\20240210\18-philemon.pkl... Zipping done in 0.01 seconds. loading ..\pickle\20240210\19-hebrews.pkl... Zipping done in 0.12 seconds. loading ..\pickle\20240210\20-james.pkl... Zipping done in 0.04 seconds. loading ..\pickle\20240210\21-1peter.pkl... Zipping done in 0.05 seconds. loading ..\pickle\20240210\22-2peter.pkl... Zipping done in 0.03 seconds. loading ..\pickle\20240210\23-1john.pkl... Zipping done in 0.04 seconds. loading ..\pickle\20240210\24-2john.pkl... Zipping done in 0.01 seconds. loading ..\pickle\20240210\25-3john.pkl... Zipping done in 0.01 seconds. loading ..\pickle\20240210\26-jude.pkl... Zipping done in 0.01 seconds. loading ..\pickle\20240210\27-revelation.pkl... Zipping done in 0.24 seconds. Finished in 6.32 seconds.
# Load TF code
from tf.fabric import Fabric
from tf.app import use
# load the app and data
N1904 = use ("tonyjurg/Nestle1904LFT", version=scriptVersion, checkout="clone", hoist=globals())
Locating corpus resources ...
Data: tonyjurg - Nestle1904LFT 0.7, Character table, Feature docs
Node types
| Name | # of nodes | # slots / node | % coverage |
|---|---|---|---|
| book | 27 | 5102.93 | 100 |
| chapter | 260 | 529.92 | 100 |
| verse | 7943 | 17.35 | 100 |
| sentence | 8011 | 17.20 | 100 |
| wg | 105430 | 6.85 | 524 |
| word | 137779 | 1.00 | 100 |
Features:
Nestle 1904 (Low Fat Tree)
specified
- apiVersion:
3 - appName:
tonyjurg/Nestle1904LFT appPath:
C:/Users/tonyj/text-fabric-data/github/tonyjurg/Nestle1904LFT/app- commit:
g28423636826427b12ab3a8d2a3f19d1281f102d2 - css:
'' dataDisplay:
excludedFeatures:
orig_orderversebookchapter
noneValues:
noneunknown- no value
NA''
- showVerseInTuple:
0 - textFormat:
text-orig-full
docs:
- docBase:
https://github.com/tonyjurg/Nestle1904LFT/blob/main/docs/ - docPage:
about - docRoot:
https://github.com/tonyjurg/Nestle1904LFT featureBase:
https://github.com/tonyjurg/Nestle1904LFT/blob/main/docs/features/<feature>.md
- docBase:
- interfaceDefaults: {fmt:
layout-orig-full} - isCompatible:
True - local:
local localDir:
C:/Users/tonyj/text-fabric-data/github/tonyjurg/Nestle1904LFT/_tempprovenanceSpec:
- corpus:
Nestle 1904 (Low Fat Tree) - doi:
10.5281/zenodo.10182594 - org:
tonyjurg - relative:
/tf - repo:
Nestle1904LFT - repro:
Nestle1904LFT - version:
0.7 - webBase:
https://learner.bible/text/show_text/nestle1904/ - webHint:
Show this on the Bible Online Learner website - webLang:
en webUrl:
https://learner.bible/text/show_text/nestle1904/<1>/<2>/<3>- webUrlLex:
{webBase}/word?version={version}&id=<lid>
- corpus:
- release:
v0.6.3 typeDisplay:
book:
- condense:
True - hidden:
True - label:
{book} - style:
''
- condense:
chapter:
- condense:
True - hidden:
True - label:
{chapter} - style:
''
- condense:
sentence:
- hidden:
0 - label:
#{sentence} (start: {book} {chapter}:{headverse}) - style:
''
- hidden:
verse:
- condense:
True - excludedFeatures:
chapter verse - label:
{book} {chapter}:{verse} - style:
''
- condense:
wg:
- hidden:
0 label:
#{wgnum}: {wgtype} {wgclass} {clausetype} {wgrole} {wgrule} {junction}- style:
''
- hidden:
word:
- base:
True - features:
lemma - featuresBare:
gloss - surpress:
chapter verse
- base:
- writing:
grc
5.2.1 - Dump otype¶
Back to TOC¶
with open(f'{TF_PATH}/otype.tf') as fh:
print(fh.read())
@node @author=Evangelists and apostles @availability=Creative Commons Attribution 4.0 International (CC BY 4.0) @converterSource=https://github.com/tonyjurg/Nestle1904LFT/tree/main/resources/converter @converterVersion=0.7 (February 20, 2024) @converters=Tony Jurg @dataSource=MACULA Greek Linguistic Datasets, available at https://github.com/Clear-Bible/macula-greek/tree/main/Nestle1904/nodes @editors=Eberhart Nestle (1904) @sourceDescription=Greek New Testment (British Foreign Bible Society, 1904) @sourceFormat=XML (Low Fat tree XML data) @textFabricVersion=0.7 @title=Greek New Testament (Nestle1904LFT) @valueType=str @xmlSourceDate=February 10, 2024 @xmlSourceLocation=https://github.com/tonyjurg/Nestle1904LFT/tree/main/resources/xml/20240210 @writtenBy=Text-Fabric @dateWritten=2024-02-20T13:52:34Z 1-137779 word 137780-137806 book 137807-138066 chapter 138067-146077 sentence 146078-154020 verse 154021-259450 wg
5.2.2 - Dump otext¶
Back to TOC¶
with open(f'{TF_PATH}/otext.tf') as fh:
print(fh.read())
@config
@author=Evangelists and apostles
@availability=Creative Commons Attribution 4.0 International (CC BY 4.0)
@converterSource=https://github.com/tonyjurg/Nestle1904LFT/tree/main/resources/converter
@converterVersion=0.7 (February 20, 2024)
@converters=Tony Jurg
@dataSource=MACULA Greek Linguistic Datasets, available at https://github.com/Clear-Bible/macula-greek/tree/main/Nestle1904/nodes
@editors=Eberhart Nestle (1904)
@fmt:text-critical={unicode}
@fmt:text-normalized={normalized}{after}
@fmt:text-orig-full={word}{after}
@fmt:text-transliterated={wordtranslit}{after}
@fmt:text-unaccented={wordunacc}{after}
@sectionFeatures=book,chapter,verse
@sectionTypes=book,chapter,verse
@sourceDescription=Greek New Testment (British Foreign Bible Society, 1904)
@sourceFormat=XML (Low Fat tree XML data)
@structureFeatures=book,chapter,verse
@structureTypes=book,chapter,verse
@textFabricVersion=0.7
@title=Greek New Testament (Nestle1904LFT)
@xmlSourceDate=February 10, 2024
@xmlSourceLocation=https://github.com/tonyjurg/Nestle1904LFT/tree/main/resources/xml/20240210
@writtenBy=Text-Fabric
@dateWritten=2024-02-20T13:52:38Z
5.3 - Publish it on GitHub¶
Back to TOC¶
The following section will first load the created Text-Fabric dataset. Then it will publish it on gitHub.
# Define the repository
ORG = "tonyjurg"
REPO = "Nestle1904LFT"
# Added details for the release
MESSAGE = "New release"
DESCRIPTION = """
This release uses a new dataset.
The main difference is in feature Strongs:
* Some errors were corrected
* composite words are now with two or more Strong values
This release has been published with the command `A.publish()`, a function in Text-Fabric.
"""
N1904.publishRelease(3, message=MESSAGE, description=DESCRIPTION)
Working in repo ~/github/tonyjurg/Nestle1904LFT Make a new commit ... Compute a new tag ... Latest release = v0.6.3 New release = v0.6.4 Push the repo to GitHub, including tag v0.6.4 Turn the tag into a release on GitHub with additional data responce: <Response [422]> url: https://api.github.com/repos/tonyjurg/Nestle1904LFT/releases Create the zip file with the complete data Data to be zipped: OK app (v0.6.4 993dbe) : ~/github/tonyjurg/Nestle1904LFT/app OK main data (v0.6.4 993dbe) : ~/github/tonyjurg/Nestle1904LFT/tf/0.7 Writing zip file ... Upload the zip file and attach it to the release on GitHub
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Cell In[6], line 1 ----> 1 N1904.publishRelease(3, message=MESSAGE, description=DESCRIPTION) File ~\anaconda3\envs\Text-Fabric\Lib\site-packages\tf\advanced\repo.py:954, in publishRelease(app, increase, message, description) 950 binFile = baseNm(binPath) 952 console("Upload the zip file and attach it to the release on GitHub") --> 954 releaseId = response.json()["id"] 955 headers["Content-Type"] = "application/zip" 956 uploadUrl = ( 957 f"{bUrlUpload}/repos/{org}/{repo}/releases/{releaseId}/assets?name={binFile}" 958 ) KeyError: 'id'