The 'center' of the Torah (BHSA)¶
Table of content (ToC)¶
- 1 - Introduction
- 2 - Load Text-Fabric app and data
- 3 - Performing the queries
- 3.1 - Center book (Leviticus)
- 3.2 - Center chapter (Leviticus Chapter 4)
- 3.3 - Center verse (Lev 8:9)
- 3.4 - Center sentence (Ex 36:11)
- 3.5 - Center clause (Lev 4:35)
- 3.6 - Center phrase (Lev 4:32)
- 3.7 - Center word based upon word node (Lev 8:21)
- 3.8 - Center word based on spaces and maqaf (Lev 8:15)
- 3.9 - Center word based upon using feature 'wordboundary' (Lev 8:15)
- 3.10 - Center word based on spaces (Lev 8:22)
- 3.11 - Center word based on selected part of speech (Lev 8:21)
- 3.12 - Other opinion - Stone Tenach (Lev 10:16)
- 4 - Attribution and footnotes
- 5 - Required libraries
- 6 - Notebook details
1 - Introduction ¶
Back to ToC¶
It is a common belief that the center of a text segment, a book, or a specific set of books contains the central message. This notebook explores various methods to answer the question, 'What is the center of the Torah?' The main prerequisite for answering this is determining by what measure this center is to be established.
2 - Load Text-Fabric app and data ¶
Back to ToC¶
This NoteBook uses the ETCBC BHSA as dataset representing the Hebrew text of the TeNaCh.
%load_ext autoreload
%autoreload 2
# Loading the Text-Fabric code
# Note: it is assumed Text-Fabric is installed in your environment.
from tf.fabric import Fabric
from tf.app import use
# load the BHSL app and data
BHS = use ("etcbc/BHSA",hoist=globals())
Locating corpus resources ...
Data: etcbc - BHSA 2021, Character table, Feature docs
Node types
| Name | # of nodes | # slots / node | % coverage |
|---|---|---|---|
| book | 39 | 10938.21 | 100 |
| chapter | 929 | 459.19 | 100 |
| lex | 9230 | 46.22 | 100 |
| verse | 23213 | 18.38 | 100 |
| half_verse | 45179 | 9.44 | 100 |
| sentence | 63717 | 6.70 | 100 |
| sentence_atom | 64514 | 6.61 | 100 |
| clause | 88131 | 4.84 | 100 |
| clause_atom | 90704 | 4.70 | 100 |
| phrase | 253203 | 1.68 | 100 |
| phrase_atom | 267532 | 1.59 | 100 |
| subphrase | 113850 | 1.42 | 38 |
| word | 426590 | 1.00 | 100 |
Features:
Parallel Passages
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
Phonetic Transcriptions
specified
- apiVersion:
3 - appName:
etcbc/BHSA - appPath:
C:/Users/tonyj/text-fabric-data/github/etcbc/BHSA/app - commit:
gd905e3fb6e80d0fa537600337614adc2af157309 - css:
'' dataDisplay:
exampleSectionHtml:
<code>Genesis 1:1</code> (use <a href="https://github.com/{org}/{repo}/blob/master/tf/{version}/book%40en.tf" target="_blank">English book names</a>)excludedFeatures:
g_uvf_utf8g_vbskq_hybridlanguageISOg_nmelex0is_rootg_vbs_utf8g_uvfdistrootsuffix_persong_vbedist_unitsuffix_numberdistributional_parentkq_hybrid_utf8crossrefSETinstructiong_prslexeme_countrank_occg_pfm_utf8freq_occcrossrefLCSfunctional_parentg_pfmg_nme_utf8g_vbe_utf8kindg_prs_utf8suffix_gendermother_object_type
noneValues:
noneunknown- no value
NA
docs:
- docBase:
{docRoot}/{repo} - docExt:
'' - docPage:
'' - docRoot:
https://{org}.github.io - featurePage:
0_home
- docBase:
- interfaceDefaults:
{} - isCompatible:
True - local:
local - localDir:
C:/Users/tonyj/text-fabric-data/github/etcbc/BHSA/_temp provenanceSpec:
- corpus:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis - doi:
10.5281/zenodo.1007624 moduleSpecs:
:
- backend: no value
- corpus:
Phonetic Transcriptions docUrl:
https://nbviewer.jupyter.org/github/etcbc/phono/blob/master/programs/phono.ipynb- doi:
10.5281/zenodo.1007636 - org:
etcbc - relative:
/tf - repo:
phono
:
- backend: no value
- corpus:
Parallel Passages docUrl:
https://nbviewer.jupyter.org/github/etcbc/parallels/blob/master/programs/parallels.ipynb- doi:
10.5281/zenodo.1007642 - org:
etcbc - relative:
/tf - repo:
parallels
- org:
etcbc - relative:
/tf - repo:
BHSA - version:
2021 - webBase:
https://shebanq.ancient-data.org/hebrew - webHint:
Show this on SHEBANQ - webLang:
la - webLexId:
True webUrl:
{webBase}/text?book=<1>&chapter=<2>&verse=<3>&version={version}&mr=m&qw=q&tp=txt_p&tr=hb&wget=v&qget=v&nget=vt- webUrlLex:
{webBase}/word?version={version}&id=<lid>
- corpus:
- release:
v1.8 typeDisplay:
clause:
- label:
{typ} {rela} - style:
''
- label:
clause_atom:
- hidden:
True - label:
{code} - level:
1 - style:
''
- hidden:
half_verse:
- hidden:
True - label:
{label} - style:
'' - verselike:
True
- hidden:
lex:
- featuresBare:
gloss - label:
{voc_lex_utf8} - lexOcc:
word - style:
orig - template:
{voc_lex_utf8}
- featuresBare:
phrase:
- label:
{typ} {function} - style:
''
- label:
phrase_atom:
- hidden:
True - label:
{typ} {rela} - level:
1 - style:
''
- hidden:
sentence:
- label:
{number} - style:
''
- label:
sentence_atom:
- hidden:
True - label:
{number} - level:
1 - style:
''
- hidden:
subphrase:
- hidden:
True - label:
{number} - style:
''
- hidden:
word:
- features:
pdp vs vt - featuresBare:
lex:gloss
- features:
- writing:
hbo
Note: The Text-Fabric feature documentation can be found at ETCBC GitHub
# The following will push the Text-Fabric stylesheet to this notebook (to facilitate proper display with notebook viewer)
BHS.dh(BHS.getCss())
3 - Performing the queries ¶
Back to ToC¶
An important feature used in the queries will be 'number'. This starts with 1. The manner of numbering objects differs per object type. The following are of interest for this research:
| type | numbering |
|---|---|
| phrase_atom | within the book |
| clause_atom | within the book |
| sentence_atom | within the book |
| word | within the book |
Note: Full Text-Fabric feature documentation is found here
Important observation: The BHSA inserts nodes for implicit articles (which are only visable in the vocalisation). See example below:
3.1 - Center book¶
Back to TOC¶
Rather trivially, Leviticus constitutes the center of the five books of the Torah.
3.2 - Center chapter ¶
Back to TOC¶
The following method is based upon the center chapter.
# number of chapters in Torah
ChapterQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
chapter
'''
ChapterResults = BHS.search(ChapterQuery)
0.05s 187 results
F.otype.sInterval('chapter')
(426630, 427558)
# start + delta: 426630 + int(187/2) = 426630 + 93 = 426723
T.sectionFromNode(426723)
('Leviticus', 4)
3.3 - Center verse ¶
This method is based upon the middle verse in the Torah.
# number of verses in Torah
VerseQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
verse
'''
VerseResults = BHS.search(VerseQuery)
0.05s 5853 results
Determine boundaries of the verse node-numbers.
F.otype.sInterval('verse')
(1414389, 1437601)
# start + delta: 1414389 + int(5853/2) = 1414389 + 2926 = 1417315
T.sectionFromNode(1417315)
('Leviticus', 8, 9)
T.text(1417315)
'וַיָּ֥שֶׂם אֶת־הַמִּצְנֶ֖פֶת עַל־רֹאשֹׁ֑ו וַיָּ֨שֶׂם עַֽל־הַמִּצְנֶ֜פֶת אֶל־מ֣וּל פָּנָ֗יו אֵ֣ת צִ֤יץ הַזָּהָב֙ נֵ֣זֶר הַקֹּ֔דֶשׁ כַּאֲשֶׁ֛ר צִוָּ֥ה יְהוָ֖ה אֶת־מֹשֶֽׁה׃ '
BHS.show(VerseResults,start=2926,end=2926, multiFeatures=False)
result 2926
This verse in the King James Version:
And he put the mitre upon his head; also upon the mitre, even upon his forefront, did he put the golden plate, the holy crown; as the Lord commanded Moses.
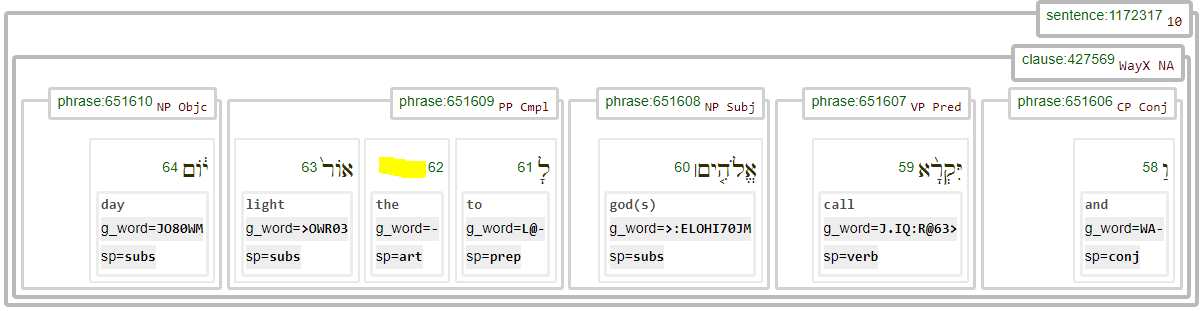
3.4 - Center sentence ¶
The following method is based upon the center sentence. In this method the sentence definition used is the one according to the ETCBC database, which at places differs from other databases.
# number of sentences in Torah
SentenceQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
sentence
'''
SentenceResults = BHS.search(SentenceQuery)
0.10s 15088 results
Determining the interval of sentence node-numbers.
F.otype.sInterval('sentence')
(1172308, 1236024)
# start + delta: 1172308 + int(15088/2) = 1172308 + 7544 = 1179852
T.sectionFromNode(1179852)
('Exodus', 36, 11)
T.text(1179852)
'וַיַּ֜עַשׂ לֻֽלְאֹ֣ת תְּכֵ֗לֶת עַ֣ל שְׂפַ֤ת הַיְרִיעָה֙ הָֽאֶחָ֔ת מִקָּצָ֖ה בַּמַּחְבָּ֑רֶת '
# 15088 results / 2 = 7544
BHS.show(SentenceResults,start=7544,end=7544,multiFeatures=False)
result 7544
This sentence in the King James Version:
and the other five curtains he coupled one unto another.
Note that in the KJV this is a subsentence.
3.5 - Center clause ¶
The following method is based upon the center clause. In this method the clause definition used is the one according to the ETCBC database, which may slightly differ in other implementations.
# number of clauses in Torah
ClauseQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
clause
'''
ClauseResults = BHS.search(ClauseQuery)
0.11s 21181 results
Determining the interval of clause node-numbers.
F.otype.sInterval('clause')
(427559, 515689)
# start + delta: 427559 + int(21181/2) = 427559 + 10590 = 438149
T.sectionFromNode(438149)
('Leviticus', 4, 35)
T.text(438149)
'וְאֶת־כָּל־חֶלְבָּ֣ה יָסִ֗יר '
# 21181 results / 2 = 10590,5 -> midpoint = 10590
BHS.show(ClauseResults,start=10590,end=10590, multiFeatures=False)
result 10590
In the King James Version:
and shall pour out all the blood thereof at the bottom of the altar
Note that while in the ETCBC BHSA sentences often contain multiple clauses, this clause constitutes a full sentence.
3.6 - Center phrase ¶
The following method is based upon the center phrase. In this method the clause definition used is the one according to the ETCBC database, following a more-or-less general understanding of what does constitute a phrase.
# number of phrases in Torah
PhraseQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
phrase
'''
PhraseResults = BHS.search(PhraseQuery)
0.30s 64195 results
Determining the interval of phrase node-numbers.
F.otype.sInterval('phrase')
(651573, 904775)
# start + delta: 651573 + int(64195/2) = 651573 + 32097 = 683670
T.sectionFromNode(683670)
('Leviticus', 4, 32)
T.text(683670)
'נְקֵבָ֥ה תְמִימָ֖ה '
# 64195 results /2 = 32097,5 -> midpoint = 32098
BHS.show(PhraseResults,start=32098,end=32098,multiFeatures=False)
result 32098
In the King James Version:
a female without blemish
3.7 - Center word - based upon center word node¶
This method assumes the mathematical center of the list of word nodes provides us the center of the Torah.
# number of words in Torah (WARNING: as per ETCBC definition!)
WordQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
word
'''
WordResults = BHS.search(WordQuery)
0.48s 112927 results
The following code validates that the word nodes are numbered starting from '1'.
F.otype.sInterval('word')
(1, 426590)
Find the midle word node
# start + delta: 1 + int(112927/2) = 1 + 56463 = 56464
T.sectionFromNode(56464)
('Leviticus', 8, 21)
T.text(56464)
'בַּ'
# 112927 results /2 = 56463,5 -> midpoint = 56464
BHS.show(WordResults,start=56464,end=56464,multiFeatures=False)
result 56464
If this would be 'translated' into a meaningfull 'center' clause, it could be:
'wash in the water'.
3.8 - Center word based on spaces and maqaf¶
Here the number of words in the Torah is determined by items separeted by spaces OR maqaf (diacritical mark indicating a strong connection between words).
First check what can be placed after an individual word
# note: this is for the full TeNaCH!
F.trailer.freqList()
((' ', 236930),
('', 121801),
('&', 42275),
('00 ', 20146),
('05 ', 2266),
('00_S ', 1892),
('00_P ', 1165),
('_S ', 76),
(' 05 ', 17),
('_P ', 13),
('00_N ', 7),
('00_N_P ', 1),
('00_N_S ', 1))
In this list, the ' ' value (i.e. a space) is used when the word is joined to the next word, while '&' indicates a maqqef (־), a diacritical mark indicating a strong connection between words. We consider both as word separators. Examining the frequency list above there are two methods to determine the word boundaries. The first is utilizing the fact that all feature values indicating a wordboundary are of lenght 1 or higher, allowing the string (.+) to exclude all cases where the lenght is less than 1 character. The other option is to explicitly look for spaces and maqqefs, by using [\s&] as regex expression. As expected, both product the same outcome. The following query determines the number of words in the torah based on this methond of counting.
# define query template
# The preceding 'r' before the template allows for a raw strings, preventing Python from altering the regex.
WordQuery2 = r'''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
word trailer~[\s&]
'''
WordResults2 = BHS.search(WordQuery2)
0.68s 79886 results
Find the midpoint: 79886/2 = 39948
T.text(39949)
'תַעֲשׂ֖וּן '
BHS.show(WordResults2,start=39948,end=39948,multiFeatures=False)
result 39948
Following this method, the center would be:
and be holy
3.9 - Center word based upon using feature 'wordboundary'¶
In this section we will use some of the additonal features made available by the BHSaddons dataset.
# load the app and data with additial features (removed the hoist here)
BHSAadd = use ("etcbc/BHSA", mod="tonyjurg/BHSaddons/tf/:hot")
Locating corpus resources ...
rate limit is 5000 requests per hour, with 4943 left for this hour connecting to online GitHub repo tonyjurg/BHSaddons ... connected
The requested data is not available offline ~/text-fabric-data/github/etcbc/parallels/tf/2021 not found
File is not a zip file could not save corpus data to ~/text-fabric-data/github
rate limit is 5000 requests per hour, with 4940 left for this hour connecting to online GitHub repo etcbc/parallels ... connected downloading from https:/github.com/ETCBC/parallels/releases/download/v2.1/tf-2021.zip ... saving data
| 0.11s T crossref from ~/text-fabric-data/github/etcbc/parallels/tf/2021
Data: etcbc - BHSA 2021, Character table, Feature docs
Node types
| Name | # of nodes | # slots / node | % coverage |
|---|---|---|---|
| book | 39 | 10938.21 | 100 |
| chapter | 929 | 459.19 | 100 |
| lex | 9230 | 46.22 | 100 |
| verse | 23213 | 18.38 | 100 |
| half_verse | 45179 | 9.44 | 100 |
| sentence | 63717 | 6.70 | 100 |
| sentence_atom | 64514 | 6.61 | 100 |
| clause | 88131 | 4.84 | 100 |
| clause_atom | 90704 | 4.70 | 100 |
| phrase | 253203 | 1.68 | 100 |
| phrase_atom | 267532 | 1.59 | 100 |
| subphrase | 113850 | 1.42 | 38 |
| word | 426590 | 1.00 | 100 |
Features:
Parallel Passages
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
Phonetic Transcriptions
tonyjurg/BHSaddons/tf
specified
- apiVersion:
3 - appName:
etcbc/BHSA - appPath:
C:/Users/tonyj/text-fabric-data/github/etcbc/BHSA/app - commit:
gd905e3fb6e80d0fa537600337614adc2af157309 - css:
'' dataDisplay:
exampleSectionHtml:
<code>Genesis 1:1</code> (use <a href="https://github.com/{org}/{repo}/blob/master/tf/{version}/book%40en.tf" target="_blank">English book names</a>)excludedFeatures:
g_uvf_utf8g_vbskq_hybridlanguageISOg_nmelex0is_rootg_vbs_utf8g_uvfdistrootsuffix_persong_vbedist_unitsuffix_numberdistributional_parentkq_hybrid_utf8crossrefSETinstructiong_prslexeme_countrank_occg_pfm_utf8freq_occcrossrefLCSfunctional_parentg_pfmg_nme_utf8g_vbe_utf8kindg_prs_utf8suffix_gendermother_object_type
noneValues:
noneunknown- no value
NA
docs:
- docBase:
{docRoot}/{repo} - docExt:
'' - docPage:
'' - docRoot:
https://{org}.github.io - featurePage:
0_home
- docBase:
- interfaceDefaults:
{} - isCompatible:
True - local:
local - localDir:
C:/Users/tonyj/text-fabric-data/github/etcbc/BHSA/_temp provenanceSpec:
- corpus:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis - doi:
10.5281/zenodo.1007624 moduleSpecs:
:
- backend: no value
- corpus:
Phonetic Transcriptions docUrl:
https://nbviewer.jupyter.org/github/etcbc/phono/blob/master/programs/phono.ipynb- doi:
10.5281/zenodo.1007636 - org:
etcbc - relative:
/tf - repo:
phono
:
- backend: no value
- corpus:
Parallel Passages docUrl:
https://nbviewer.jupyter.org/github/etcbc/parallels/blob/master/programs/parallels.ipynb- doi:
10.5281/zenodo.1007642 - org:
etcbc - relative:
/tf - repo:
parallels
- org:
etcbc - relative:
/tf - repo:
BHSA - version:
2021 - webBase:
https://shebanq.ancient-data.org/hebrew - webHint:
Show this on SHEBANQ - webLang:
la - webLexId:
True webUrl:
{webBase}/text?book=<1>&chapter=<2>&verse=<3>&version={version}&mr=m&qw=q&tp=txt_p&tr=hb&wget=v&qget=v&nget=vt- webUrlLex:
{webBase}/word?version={version}&id=<lid>
- corpus:
- release:
v1.8 typeDisplay:
clause:
- label:
{typ} {rela} - style:
''
- label:
clause_atom:
- hidden:
True - label:
{code} - level:
1 - style:
''
- hidden:
half_verse:
- hidden:
True - label:
{label} - style:
'' - verselike:
True
- hidden:
lex:
- featuresBare:
gloss - label:
{voc_lex_utf8} - lexOcc:
word - style:
orig - template:
{voc_lex_utf8}
- featuresBare:
phrase:
- label:
{typ} {function} - style:
''
- label:
phrase_atom:
- hidden:
True - label:
{typ} {rela} - level:
1 - style:
''
- hidden:
sentence:
- label:
{number} - style:
''
- label:
sentence_atom:
- hidden:
True - label:
{number} - level:
1 - style:
''
- hidden:
subphrase:
- hidden:
True - label:
{number} - style:
''
- hidden:
word:
- features:
pdp vs vt - featuresBare:
lex:gloss
- features:
- writing:
hbo
# find all 'end-of-word' word nodes within any parasha
wordboundaryQuery = '''
verse parashanum
word wordboundary=1
'''
wordboundaryResult = BHSAadd.search(wordboundaryQuery)
0.41s 79886 results
# find all word nodes within any parasha
wordboundaryQuery = '''
verse parashanum
word
'''
wordboundaryResult = BHSAadd.search(wordboundaryQuery)
0.44s 112927 results
As can be seen from these queries, the result is (as expected) the same as for the previous section (3.8).
3.10 - Center word based upon spaces¶
In the following method words are defined as items separeted by spaces.
# following regexp selects for values of feature trailer that are 1 or more characters in length {alternative regex: (.+) }
wordQuery3 = r'''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
word trailer~\ $
'''
wordResults3 = BHS.search(wordQuery3)
0.60s 68434 results
# Just to check: query for maqafs
maqafQuery = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
word trailer=&
'''
maqafResults = BHS.search(maqafQuery)
0.34s 11452 results
Check if the numbers do add up: 68434 (spaces) + 11452 (maqafs) =? 79886 (total) YES!
Find the midpoint in wordResults3: 68434/2 = 34217 and print its tuple:
wordResults3[34216]
(426593, 56509)
Print associated text (we need second element in tuple):
T.text(wordResults3[34216][1])
'רֹ֥אשׁ '
Displaying the syntax tree of the relevant verse:
BHS.show(wordResults3,start=34217,end=34217,multiFeatures=False)
result 34217
Following this method, the center would be:
(on the) head of the ram
3.11 - Center word based upon selected part of speech¶
The following method is intended to exclude items like the Nota Accusativus / object marker (את) where they have a purely gramatical function only.
wordQuery4 = '''
book book=Genesis|Exodus|Leviticus|Numeri|Deuteronomium
word sp=adjv|advb|art|conj|intj|inrg|nega|nmpr|prep|prde|prin|prps|subs|verb
'''
wordResults4 = BHS.search(wordQuery4)
midpoint: int(112927/2)=56463
BHS.show(wordResults4,start=56463,end=56463,multiFeatures=False)
Following this method, the center would be:
he washed in the water
3.12 - Other opinion - Stone Tenach¶
According to the 'Stone Tanach':1
[Lev] 10:16 דָּרֹ֥שׁ דָּרַ֛שׁ - inquired insistently [lit. inquire he inquired]. This is the exact halfway mark of the word of the Torah. This teaches us that one must always inquire; one must never stop seeking an ever deeper and broader understanding of the Torah (Degel Machaneh Ephraim).
4 - Attribution and footnotes¶
Back to ToC¶
Footnotes:¶
1Rabbi Nosson Scherman (ed), The Stone Edition Tanach, Hebrew and English Edition (Brooklyn NY: Mesorah Publications Ltd, 1996), 266.
5 - Required libraries¶
Back to ToC¶
The scripts in this notebook require (beside text-fabric) the following Python libraries to be installed in the environment:
{none}
You can install any missing library from within Jupyter Notebook using eitherpip or pip3.