Pipeline Parallelism¶
이번 세션에서는 파이프라인 병렬화에 대해 알아보겠습니다.
1. Inter-layer model parallelism¶
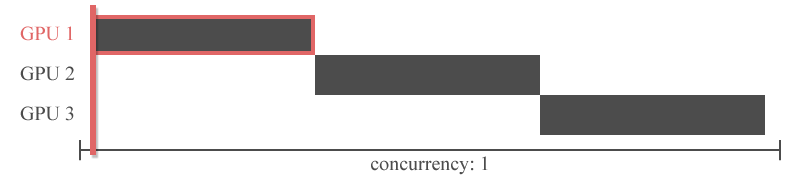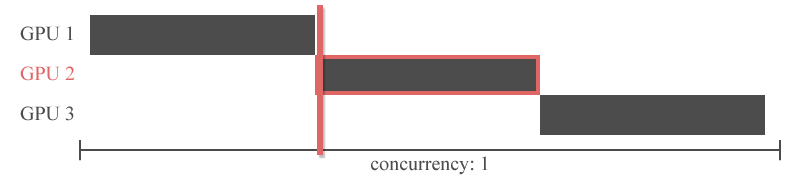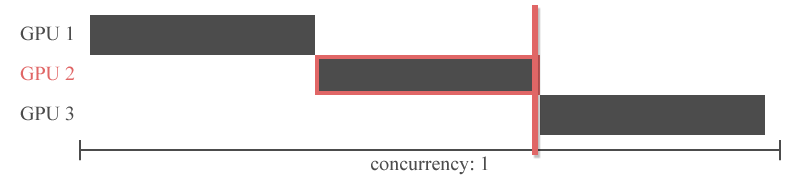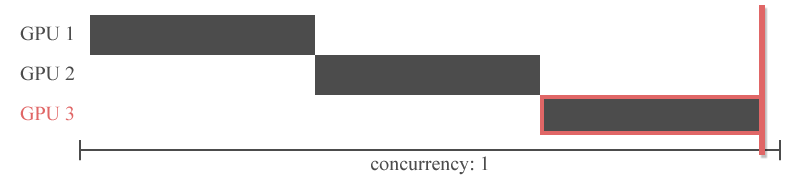
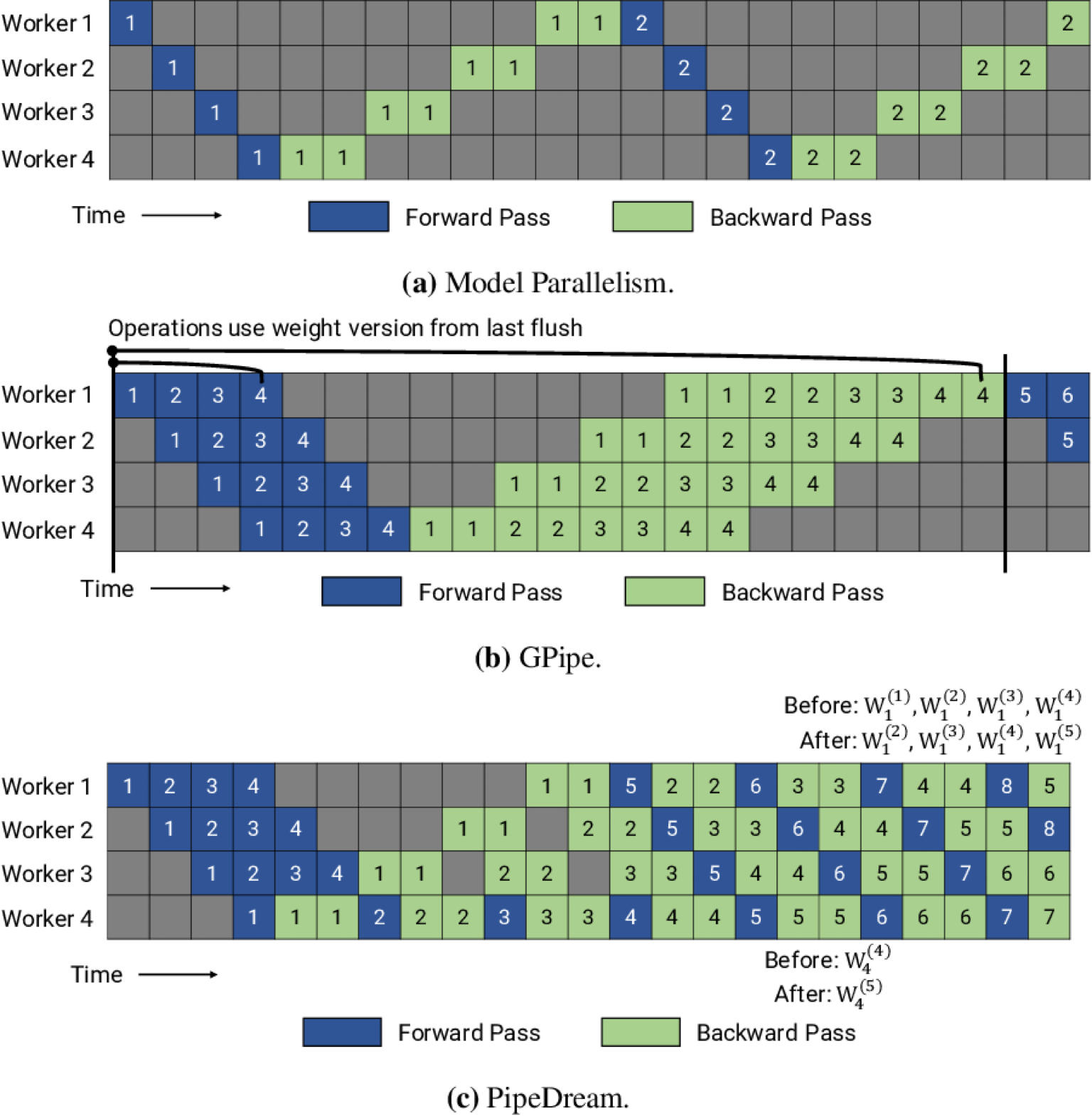
파이프라인 병렬화는 Inter-layer 모델 병렬화를 개선한 것입니다. Inter-layer 모델 병렬화는 아래와 같이 특정 GPU에 특정 레이어들을 할당하는 모델 병렬화 방법이였죠. 아래 그림에서는 GPU1번에 1,2,3번 레이어가 할당되었고, GPU2번에 4,5번 레이어가 할당 되었는데, 이 때 쪼개진 하나의 조각을 stage(스테이지)라고 합니다. 아래 예시의 경우 2개의 스테이지로 분할되었습니다.
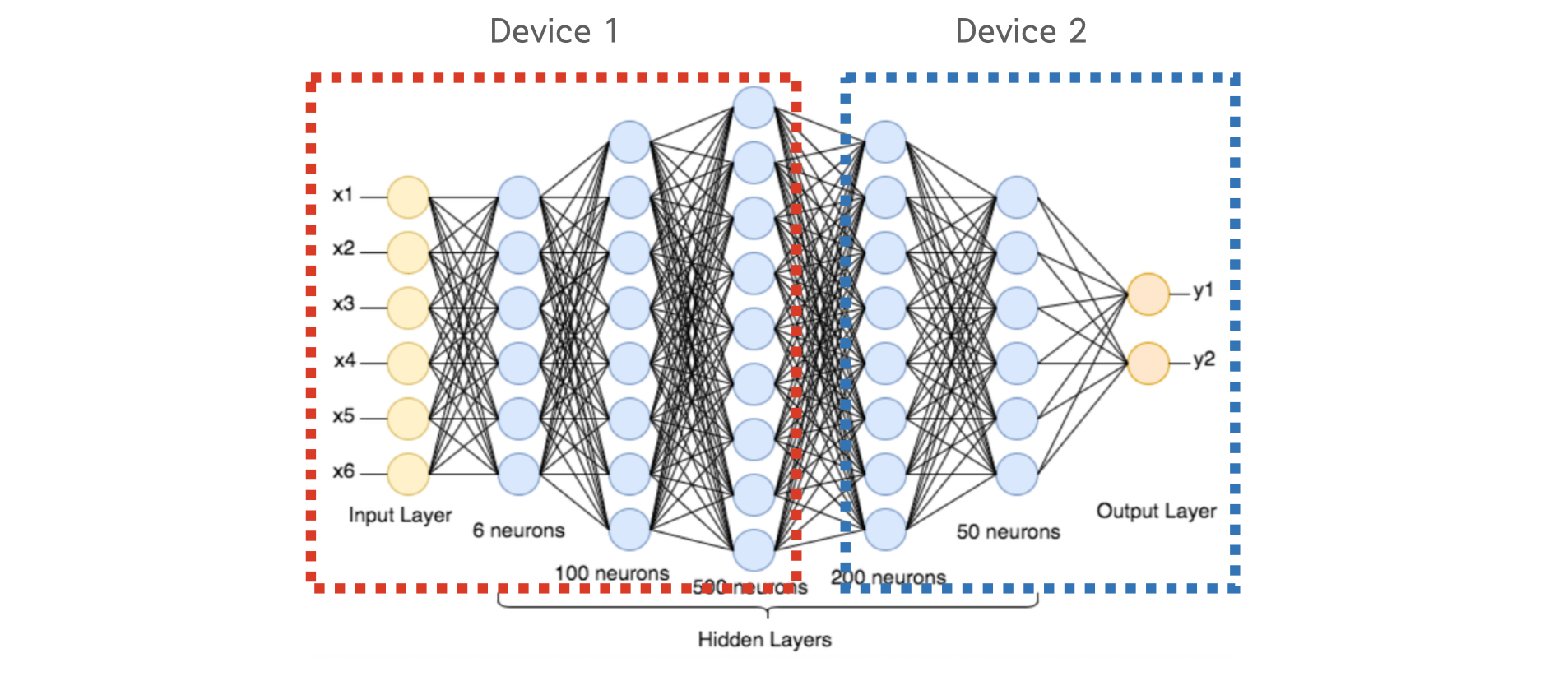
그러나 이전 레이어의 출력을 다음 레이어의 입력으로 하는 신경망의 특성상 특정 GPU의 연산이 끝나야 다른 GPU가 연산을 시작할 수 있습니다. 즉, 아래의 그림처럼 Inter-layer 모델 병렬화는 동시에 하나의 GPU만 사용할 수 있다는 치명적인 한계를 가지고 있습니다.
2. GPipe¶
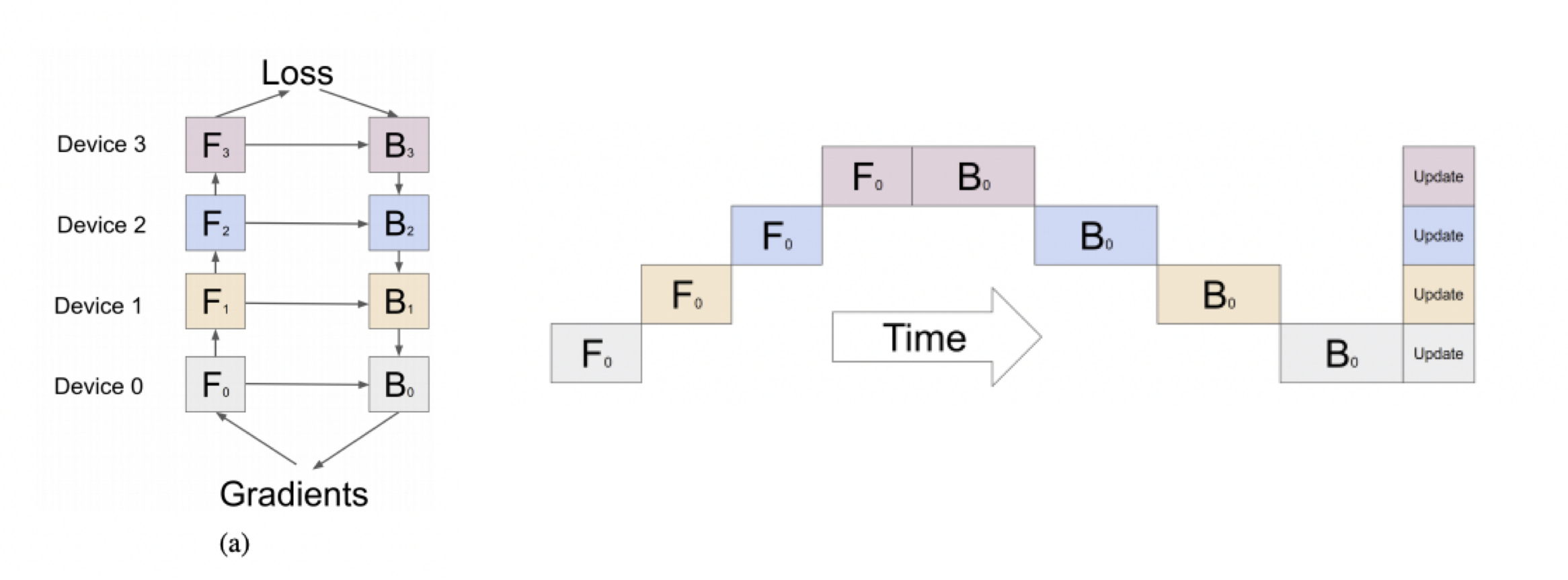
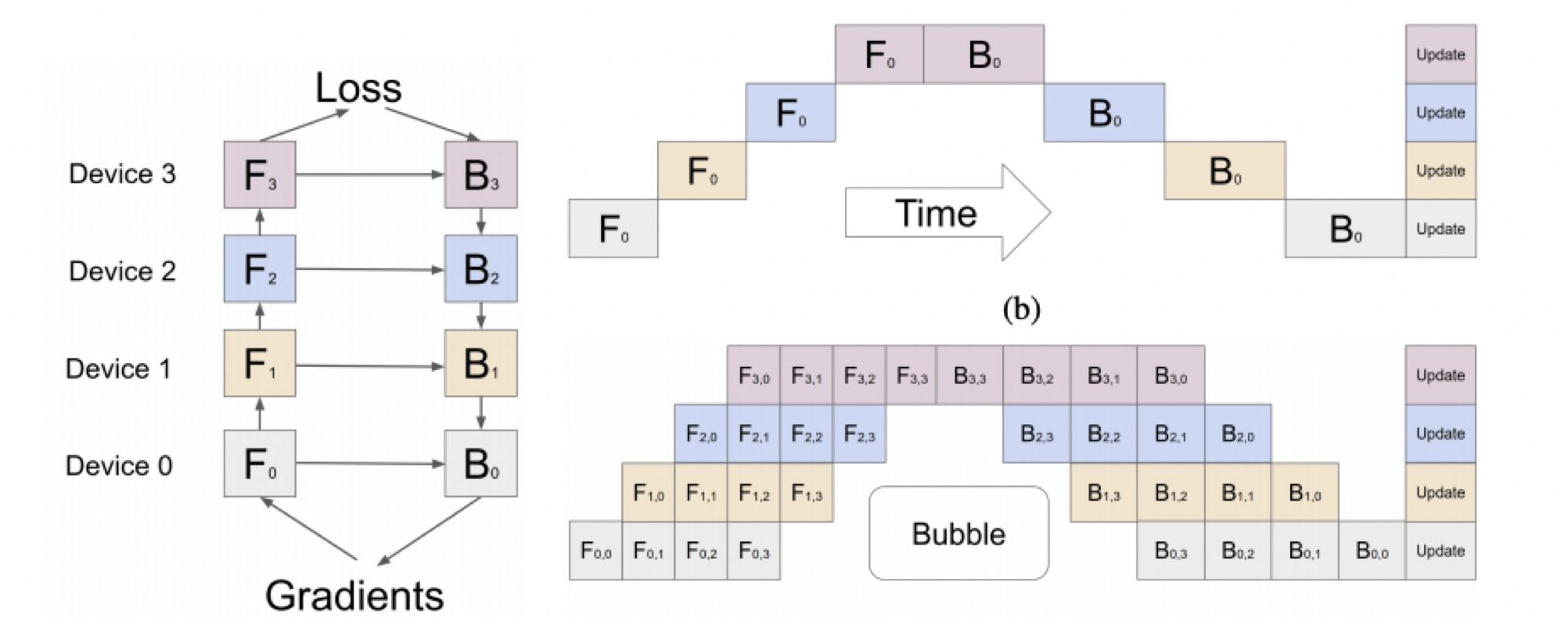
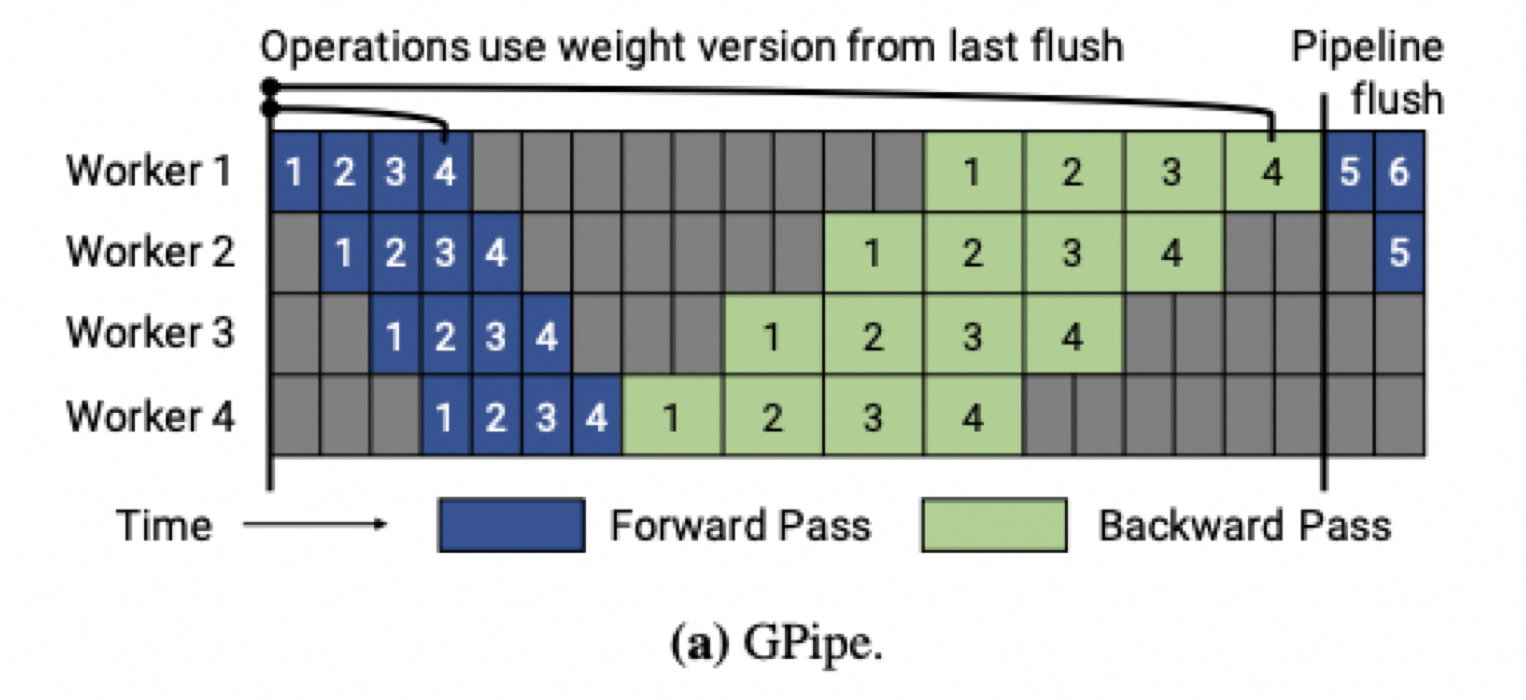
GPipe는 Google에서 개발된 파이프라인 병렬화 기법으로 Inter Layer 모델 병렬화 시 GPU가 쉬는 시간 (idle time)을 줄이기 위해 등장했으며, mini-batch를 micro-batch로 한번 더 쪼개서 학습 과정을 파이프라이닝 하는 방식으로 동작합니다.
Micro-batch¶
- Mini-batch는 전체 데이터셋을 n개로 분할한 서브샘플 집합입니다.
- Micro-batch는 Mini-batch를 m개로 한번 더 분할한 서브샘플 집합입니다.

Pipelining¶
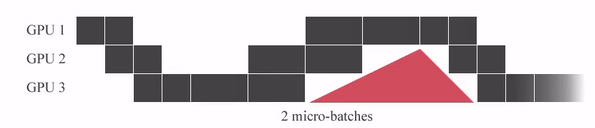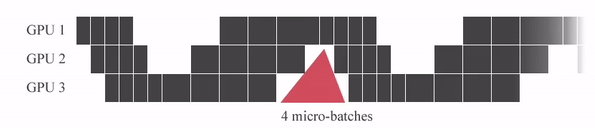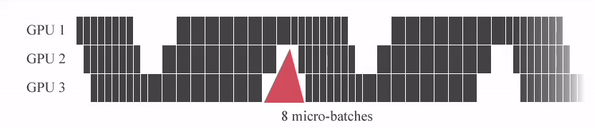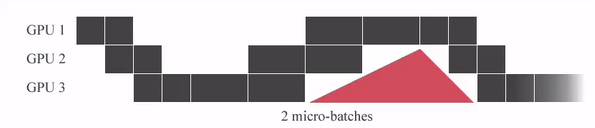
GPipe는 미니배치를 마이크로 배치로 쪼개고 연산을 파이프라이닝 합니다. 붉은색 (GPU가 쉬는 부분)을 Bubble time이라고 하는데, Micro batch 사이즈가 커질 수록 Bubble time이 줄어드는 것을 알 수 있습니다.
GPipe with PyTorch¶
kakaobrain에서 공개한 torchgpipe를 사용하면 손쉽게 GPipe를 사용할 수 있습니다. 단, nn.Sequential로 래핑된 모델만 사용 가능하며 모든 모듈의 입력과 출력 타입은 torch.Tensor 혹은 Tuple[torch.Tensor]로 제한됩니다. 따라서 코딩하기가 상당히 까다롭습니다.
"""
src/gpipe.py
"""
import torch
import torch.nn as nn
from datasets import load_dataset
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchgpipe import GPipe
from transformers import GPT2Tokenizer, GPT2LMHeadModel
from transformers.models.gpt2.modeling_gpt2 import GPT2Block as GPT2BlockBase
class GPT2Preprocessing(nn.Module):
def __init__(self, config):
super().__init__()
self.embed_dim = config.hidden_size
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)
self.drop = nn.Dropout(config.embd_pdrop)
def forward(self, input_ids):
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
position_ids = torch.arange(
0, input_shape[-1], dtype=torch.long, device=input_ids.device
)
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
inputs_embeds = self.wte(input_ids)
position_embeds = self.wpe(position_ids)
hidden_states = inputs_embeds + position_embeds
hidden_states = self.drop(hidden_states)
return hidden_states
class GPT2Block(GPT2BlockBase):
def forward(self, hidden_states):
hidden_states = super(GPT2Block, self).forward(
hidden_states=hidden_states,
)
return hidden_states[0]
class GPT2Postprocessing(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_f = nn.LayerNorm(
config.hidden_size,
eps=config.layer_norm_epsilon,
)
self.lm_head = nn.Linear(
config.hidden_size,
config.vocab_size,
bias=False,
)
def forward(self, hidden_states):
hidden_states = self.ln_f(hidden_states)
lm_logits = self.lm_head(hidden_states)
return lm_logits
def create_model_from_pretrained(model_name):
pretrained = GPT2LMHeadModel.from_pretrained(model_name)
preprocess = GPT2Preprocessing(pretrained.config)
preprocess.wte.weight = pretrained.transformer.wte.weight
preprocess.wpe.weight = pretrained.transformer.wpe.weight
blocks = pretrained.transformer.h
for i, block in enumerate(blocks):
block.__class__ = GPT2Block
postprocess = GPT2Postprocessing(pretrained.config)
postprocess.ln_f.weight = pretrained.transformer.ln_f.weight
postprocess.ln_f.bias = pretrained.transformer.ln_f.bias
postprocess.lm_head.weight.data = pretrained.lm_head.weight.data.clone()
return nn.Sequential(preprocess, *blocks, postprocess)
if __name__ == "__main__":
world_size = 4
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
model = create_model_from_pretrained(model_name="gpt2")
model = GPipe(
model,
balance=[4, 3, 3, 4],
devices=[0, 1, 2, 3],
chunks=world_size,
)
datasets = load_dataset("squad").data["train"]["context"]
datasets = [str(sample) for sample in datasets]
data_loader = DataLoader(datasets, batch_size=8, num_workers=8)
optimizer = Adam(model.parameters(), lr=3e-5)
loss_fn = nn.CrossEntropyLoss()
for i, data in enumerate(data_loader):
optimizer.zero_grad()
tokens = tokenizer(data, return_tensors="pt", truncation=True, padding=True)
input_ids = tokens.input_ids.to(0)
labels = tokens.input_ids.to(world_size - 1)
lm_logits = model(input_ids)
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss = nn.CrossEntropyLoss()(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
loss.backward()
optimizer.step()
if i % 10 == 0:
print(f"step: {i}, loss: {loss}")
if i == 300:
break
# !python -m torch.distributed.launch --nproc_per_node=4 ../src/gpipe.py
!python ../src/gpipe.py
Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453) 100%|█████████████████████████████████████████████| 2/2 [00:00<00:00, 55.94it/s] step: 0, loss: 6.084661483764648 step: 10, loss: 3.2574026584625244 step: 20, loss: 2.796205759048462 step: 30, loss: 2.5538008213043213 step: 40, loss: 2.8463237285614014 step: 50, loss: 2.3466761112213135 step: 60, loss: 2.5407633781433105 step: 70, loss: 2.2434418201446533 step: 80, loss: 2.4792842864990234 step: 90, loss: 2.9400510787963867 step: 100, loss: 2.8163280487060547 step: 110, loss: 2.4787795543670654 step: 120, loss: 2.9588236808776855 step: 130, loss: 2.3893203735351562 step: 140, loss: 2.9571073055267334 step: 150, loss: 3.9219329357147217 step: 160, loss: 3.023880958557129 step: 170, loss: 3.018484592437744 step: 180, loss: 1.6825034618377686 step: 190, loss: 3.5461761951446533 step: 200, loss: 3.6606838703155518 step: 210, loss: 3.527740001678467 step: 220, loss: 2.988645315170288 step: 230, loss: 3.1758480072021484 step: 240, loss: 2.5451812744140625 step: 250, loss: 3.1476473808288574 step: 260, loss: 3.4633867740631104 step: 270, loss: 3.199225902557373 step: 280, loss: 2.612720489501953 step: 290, loss: 2.139256238937378 step: 300, loss: 3.437178373336792
3. 1F1B Pipelining (PipeDream)¶
Microsoft에서 공개한 PipeDream은 GPipe와는 약간 다른 방식의 파이프라이닝을 수행합니다. 흔히 이 방법을 1F1B라고 부르는데, 모든 Forward가 끝나고 나서 Backward를 수행하는 GPipe와 달리 PipeDream은 Forward와 Backward를 번갈아가면서 수행합니다.
1F1B Pipelining에는 다음과 같은 두가지 챌린지가 존재합니다.
- Weight version managing
- Work partitioning
1) Weight version managinig¶
GPipe의 경우 하나의 weight 버전만 운용하지만 주기적으로 Pipeline flush가 일어납니다. Pipeline flush란 계산된 Gradient를 통해 파라미터를 업데이트 하는 과정입니다. 이러한 flush 과정 중에는 어떠한 forward, backward 연산도 하지 않기 때문에 처리 효율이 떨어집니다.
PipeDream은 이러한 flush 없이 계속해서 파라미터를 업데이트 해나갑니다. 따라서 forward와 backward가 모두 쉬는 시간이 사라집니다. 그러나 이를 위해서는 여러 버전의 파라미터 상태를 지속적으로 관리해야 합니다. 만약 최신버전의 파라미터만 저장하고 있으면 이전 layer의 출력이 다음 layer로 전송될 때, 다음 layer 부분이 업데이트 될 수도 있기 때문이죠.
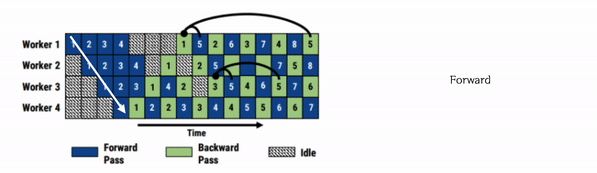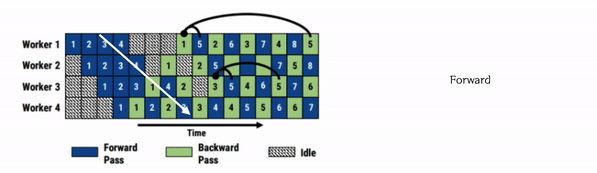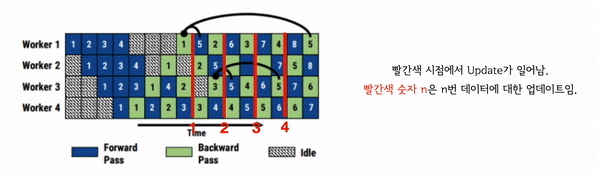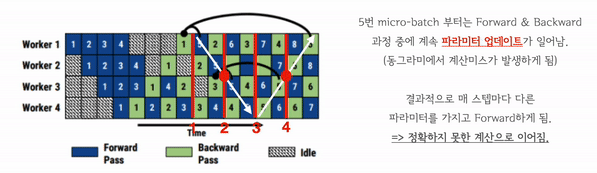
이러한 문제를 막기 위해 여러 버전의 weight를 저장하여 관리하는데 그러면 weight를 저장하면 메모리 공간을 많이 차지하게 됩니다. 따라서 이 부분에서 트레이드 오프가 발생합니다.
- GPipe: 메모리 효율적, 프로세싱 비효율적
- PipeDream: 메모리 비효율적, 프로세싱 효율적
2) Work Partitioning¶
두번쨰 문제는 뉴럴넷을 어떻게 쪼갤건지에 대한 문제입니다. 단순히 Layer별로 동일한 수의 레이어를 갖게끔 하는 것이 항상 최고의 솔루션이라고 할 수는 없겠죠. 우리에게 가장 중요한 것은 idle time을 최소화을 최소화 하는 것입니다. 그러기 위해서는 각 파티션의 running time이 비슷해야겠죠. 그 이외에도 추가로 parameter size, activation memory 등을 고려해야 합니다.
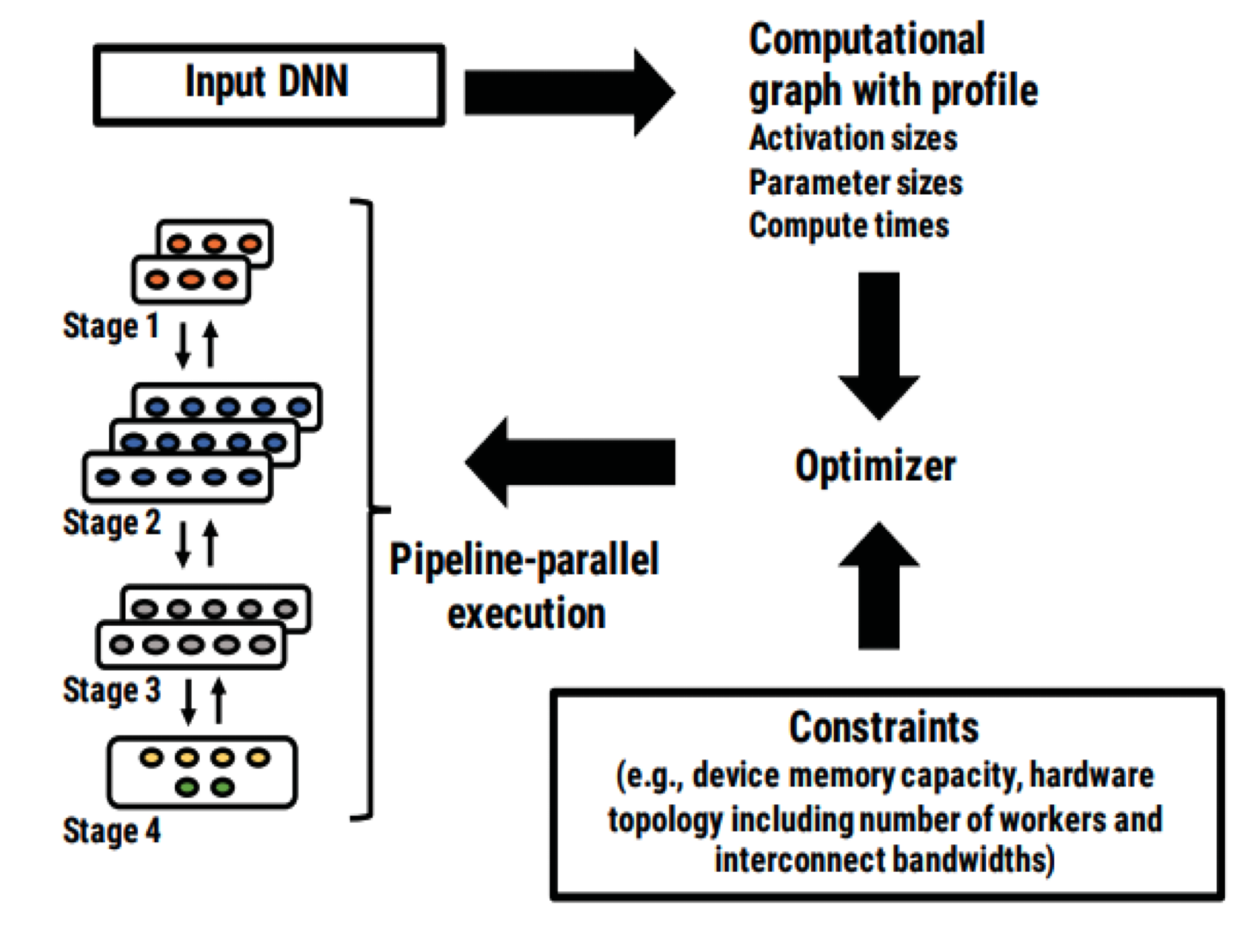
PipeDream은 Profiling과 Optimizing을 통해 최적의 Partioning 전략을 찾아냅니다.
4. Variations of 1F1B Pipelining¶
PipeDream의 1F1B 파이프라이닝을 개선한 두가지 버전의 파이프라인 전략을 소개합니다.
1) PipeDream 2BW (2-buffered weight update)¶
PipeDream 2BW는 PipeDream의 메모리 비효율성을 개선하기 위해 등장했습니다. 핵심 아이디어는 파이프라이닝 중에 Gradient Accumulation을 수행하는 것입니다. 여러개의 Gradient들을 모아두다가 한번에 업데이트를 수행하는 방식으로 메모리 비효율성 문제를 해결했죠. 2BW는 이전과 달리 단 두개의 weight version만 유지하면 됩니다.
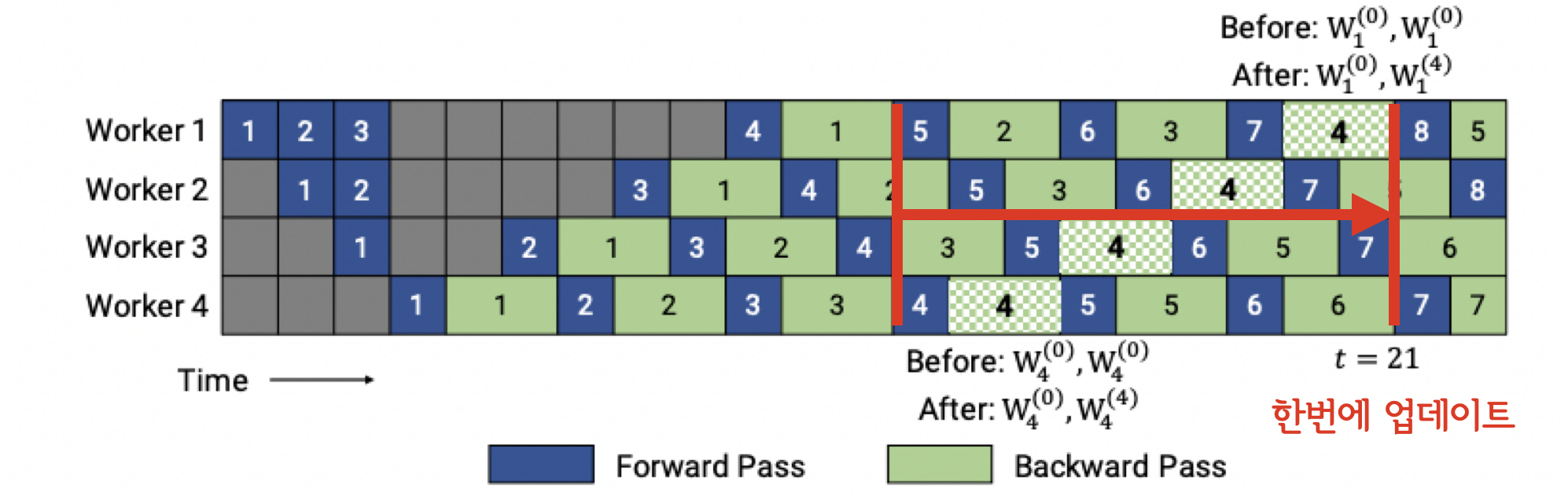
2) PipeDream Flush¶
PipeDream Flush는 1F1B와 Pipeline Flush를 결합한 파이프라이닝 방법입니다. 이 파이프라이닝 방법은 Flush가 일어나기 때문에 GPIpe와 비교하여 idle time은 비슷하나, forward-backward 과정에서 유지해야 하는 activation memory가 줄어듭니다. PipeDream Flush는 Flush가 일어나기 때문에 여러버전의 파라미터를 관리할 필요가 없습니다. 따라서 단일 가중치만 유지하면 되기 때문에 PipeDream 2BW보다도 더 메모리 효율적입니다. (지금까지 소개드린 기법들 중 가장 메모리 효율적입니다.)


잠깐... 근데 Activation Memory가 뭐야?¶
대부분의 Layer들은 Backward를 호출하기 전에 Forward에서 나온 출력값들을 저장하고 있습니다. 이는 torch.autograd.Function을 사용해보신 분들은 잘 아실텐데요. ctx변수에 forward 레이어의 출력값들을 저장해둡니다.
"""
참고: https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html
"""
import torch
class ReLU(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
# input 값을 저장하고 있음.
return input.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[input < 0] = 0
return grad_input
이는 미분값(Gradient)을 계산할때 Forward 과정에서 사용했던 값들이 필요하기 때문입니다. 다음 예시를 봅시다.
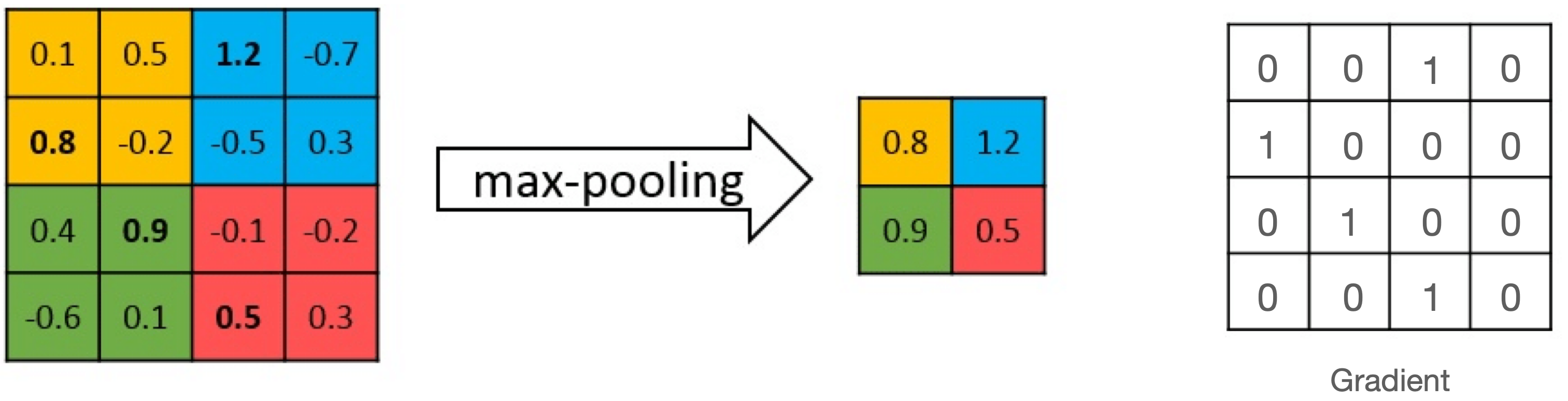
위는 Max Pooling 연산과 그에 대한 Gradient를 계산한 것입니다. Backward를 수행할때는 [[0.8, 1.2], [0.9, 0.5]]와 같은 (2, 2) 텐서가 입력으로 들어옵니다. 이 값을 가지고 오른쪽의 Gradient Matrix를 찾아내야 하는데 반드시 Forward에서 받았던 (4, 4)의 텐서가 필요합니다. 따라서 이 텐서를 메모리에 저장하고 있는 것이죠. 이렇게 Backward를 수행하기 위해 Forward 당시에 쓰였던 텐서들을 저장해두기 위해 필요한 메모리를 Activation Memory라고 합니다.
이제 Activation Memory가 뭔지 알았으니, PipeDream을 실습해볼까요? PipeDream Flush는 MS의 분산처리 라이브러리 DeepSpeed에 구현되어 있습니다. (참고: https://github.com/microsoft/DeepSpeed/issues/1110) 따라서 DeepSpeed를 사용해봅시다.
DeepSpeed 명령어 사용법¶
아 참, 그 전에 deepspeed가 제공하는 매우 편리한 기능을 먼저 알아보고 가겠습니다. 기존에는 분산처리를 위해 python -m torch.distributed.launch --nproc_per_node=n OOO.py를 사용했으나 너무 길어서 불편했죠. DeepSpeed는 deepspeed 혹은 ds와 같은 명령어를 제공하고 있습니다.
ds --num_gpus=n OOO.pydeepspeed --num_gpus=n OOO.py
위와 같은 명령어를 입력하면 torch.distributed.launch와 동일하게 작동합니다. 이제부터는 모든 분산처리 프로그램에 deepspeed의 명령어를 사용하도록 하겠습니다. (솔직히 torch.distributed.launch는 너무 길어요 😭)
"""
src/pipe_dream.py
"""
import deepspeed
import torch
import torch.nn as nn
from datasets import load_dataset
from deepspeed import PipelineModule
from torch.optim import Adam
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import GPT2Tokenizer, GPT2LMHeadModel
from transformers.models.gpt2.modeling_gpt2 import GPT2Block as GPT2BlockBase
import torch.distributed as dist
class GPT2Preprocessing(nn.Module):
def __init__(self, config):
super().__init__()
self.embed_dim = config.hidden_size
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)
self.drop = nn.Dropout(config.embd_pdrop)
def forward(self, input_ids):
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
position_ids = torch.arange(
0, input_shape[-1], dtype=torch.long, device=input_ids.device
)
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
inputs_embeds = self.wte(input_ids)
position_embeds = self.wpe(position_ids)
hidden_states = inputs_embeds + position_embeds
hidden_states = self.drop(hidden_states)
return hidden_states
class GPT2Block(GPT2BlockBase):
def forward(self, hidden_states):
hidden_states = super(GPT2Block, self).forward(
hidden_states=hidden_states,
)
return hidden_states[0]
class GPT2Postprocessing(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_f = nn.LayerNorm(
config.hidden_size,
eps=config.layer_norm_epsilon,
)
self.lm_head = nn.Linear(
config.hidden_size,
config.vocab_size,
bias=False,
)
def forward(self, hidden_states):
hidden_states = self.ln_f(hidden_states)
lm_logits = self.lm_head(hidden_states)
return lm_logits
def create_model_from_pretrained(model_name):
pretrained = GPT2LMHeadModel.from_pretrained(model_name)
preprocess = GPT2Preprocessing(pretrained.config)
preprocess.wte.weight = pretrained.transformer.wte.weight
preprocess.wpe.weight = pretrained.transformer.wpe.weight
blocks = pretrained.transformer.h
for i, block in enumerate(blocks):
block.__class__ = GPT2Block
postprocess = GPT2Postprocessing(pretrained.config)
postprocess.ln_f.weight = pretrained.transformer.ln_f.weight
postprocess.ln_f.bias = pretrained.transformer.ln_f.bias
postprocess.lm_head.weight.data = pretrained.lm_head.weight.data.clone()
return nn.Sequential(preprocess, *blocks, postprocess)
def collate_fn(batch):
batch_encoding = tokenizer.pad(
{"input_ids": batch}, padding="max_length", max_length=1024
)
return batch_encoding.input_ids
def batch_fn(data):
input_ids = data
labels = data
return input_ids, labels
def loss_fn(logits, labels):
logits = logits[..., :-1, :].contiguous()
labels = labels[..., 1:].contiguous()
return nn.CrossEntropyLoss()(
logits.view(-1, logits.size(-1)),
labels.view(-1),
)
if __name__ == "__main__":
dist.init_process_group("nccl")
world_size, rank = dist.get_world_size(), dist.get_rank()
batch_size, train_steps = 16, 300
train_samples = batch_size * train_steps
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
model = PipelineModule(
create_model_from_pretrained(model_name="gpt2"),
loss_fn=loss_fn,
num_stages=world_size,
partition_method="type:GPT2Block"
# partition_method를 통해 병렬화 하고 싶은 레이어를 고를 수 있습니다.
)
engine, optimizer, _, _ = deepspeed.initialize(
model=model,
optimizer=Adam(model.parameters(), lr=3e-5),
config={
"train_batch_size": batch_size,
"steps_per_print": 9999999,
# turn off: https://github.com/microsoft/DeepSpeed/issues/1119
},
)
engine.set_batch_fn(batch_fn)
datasets = load_dataset("squad").data["train"]["context"]
datasets = [str(sample) for i, sample in enumerate(datasets) if i < train_samples]
datasets = [
tokenizer(data, return_tensors="pt", max_length=1024).input_ids[0]
for data in tqdm(datasets)
]
data_loader = iter(
DataLoader(
sorted(datasets, key=len, reverse=True),
# uniform length batching
# https://mccormickml.com/2020/07/29/smart-batching-tutorial/
batch_size=batch_size,
num_workers=8,
collate_fn=collate_fn,
shuffle=False,
)
)
for i in range(train_steps):
loss = engine.train_batch(data_loader)
if i % 10 == 0 and rank == 0:
print(f"step: {i}, loss: {loss}")
!ds --num_gpus=4 ../src/pipe_dream.py
[2021-10-21 23:11:01,063] [WARNING] [runner.py:122:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2021-10-21 23:11:01,184] [INFO] [runner.py:360:main] cmd = /home/ubuntu/kevin/kevin_env/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgM119 --master_addr=127.0.0.1 --master_port=29500 ../src/pipe_dream.py
[2021-10-21 23:11:02,065] [INFO] [launch.py:80:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3]}
[2021-10-21 23:11:02,065] [INFO] [launch.py:86:main] nnodes=1, num_local_procs=4, node_rank=0
[2021-10-21 23:11:02,065] [INFO] [launch.py:101:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1, 2, 3]})
[2021-10-21 23:11:02,065] [INFO] [launch.py:102:main] dist_world_size=4
[2021-10-21 23:11:02,065] [INFO] [launch.py:104:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3
SEED_LAYERS=False BASE_SEED=1234 SEED_FN=None
Using topology: {ProcessCoord(pipe=0, data=0): 0, ProcessCoord(pipe=1, data=0): 1, ProcessCoord(pipe=2, data=0): 2, ProcessCoord(pipe=3, data=0): 3}
[2021-10-21 23:11:24,460] [INFO] [module.py:365:_partition_layers] Partitioning pipeline stages with method type:GPT2Block
stage=0 layers=4
0: GPT2Preprocessing
1: GPT2Block
2: GPT2Block
3: GPT2Block
stage=1 layers=3
4: GPT2Block
5: GPT2Block
6: GPT2Block
stage=2 layers=3
7: GPT2Block
8: GPT2Block
9: GPT2Block
stage=3 layers=4
10: GPT2Block
11: GPT2Block
12: GPT2Block
13: GPT2Postprocessing
loss: loss_fn
[2021-10-21 23:14:05,483] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed info: version=0.5.4+c6d1418, git-hash=c6d1418, git-branch=master
[2021-10-21 23:14:05,869] [INFO] [engine.py:204:__init__] DeepSpeed Flops Profiler Enabled: False
[2021-10-21 23:14:05,869] [INFO] [engine.py:848:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer
[2021-10-21 23:14:05,869] [INFO] [engine.py:854:_configure_optimizer] Using client Optimizer as basic optimizer
[2021-10-21 23:14:05,892] [INFO] [engine.py:870:_configure_optimizer] DeepSpeed Basic Optimizer = Adam
[2021-10-21 23:14:05,892] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed Final Optimizer = Adam
[2021-10-21 23:14:05,892] [INFO] [engine.py:596:_configure_lr_scheduler] DeepSpeed using client LR scheduler
[2021-10-21 23:14:05,892] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed LR Scheduler = None
[2021-10-21 23:14:05,892] [INFO] [logging.py:68:log_dist] [Rank 0] step=0, skipped=0, lr=[3e-05], mom=[(0.9, 0.999)]
[2021-10-21 23:14:05,892] [INFO] [config.py:940:print] DeepSpeedEngine configuration:
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] allreduce_always_fp32 ........ False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] amp_enabled .................. False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] amp_params ................... False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] checkpoint_tag_validation_enabled True
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] checkpoint_tag_validation_fail False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] curriculum_enabled ........... False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] curriculum_params ............ False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] dataloader_drop_last ......... False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] disable_allgather ............ False
[2021-10-21 23:14:05,893] [INFO] [config.py:944:print] dump_state ................... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] dynamic_loss_scale_args ...... None
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_enabled ........... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_gas_boundary_resolution 1
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_layer_name ........ bert.encoder.layer
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_layer_num ......... 0
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_max_iter .......... 100
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_stability ......... 1e-06
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_tol ............... 0.01
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] eigenvalue_verbose ........... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] elasticity_enabled ........... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] flops_profiler_config ........ {
"enabled": false,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] fp16_enabled ................. False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] fp16_master_weights_and_gradients False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] fp16_mixed_quantize .......... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] global_rank .................. 0
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] gradient_accumulation_steps .. 1
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] gradient_clipping ............ 0.0
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] gradient_predivide_factor .... 1.0
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] initial_dynamic_scale ........ 4294967296
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] loss_scale ................... 0
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] memory_breakdown ............. False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] optimizer_legacy_fusion ...... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] optimizer_name ............... None
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] optimizer_params ............. None
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] pld_enabled .................. False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] pld_params ................... False
[2021-10-21 23:14:05,894] [INFO] [config.py:944:print] prescale_gradients ........... False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_change_rate ......... 0.001
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_groups .............. 1
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_offset .............. 1000
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_period .............. 1000
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_rounding ............ 0
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_start_bits .......... 16
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_target_bits ......... 8
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_training_enabled .... False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_type ................ 0
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] quantize_verbose ............. False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] scheduler_name ............... None
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] scheduler_params ............. None
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] sparse_attention ............. None
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] sparse_gradients_enabled ..... False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] steps_per_print .............. 9999999
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] tensorboard_enabled .......... False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] tensorboard_job_name ......... DeepSpeedJobName
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] tensorboard_output_path ......
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] train_batch_size ............. 16
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] train_micro_batch_size_per_gpu 16
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] use_quantizer_kernel ......... False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] wall_clock_breakdown ......... False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] world_size ................... 1
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] zero_allow_untested_optimizer False
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] zero_config .................. {
"stage": 0,
"contiguous_gradients": true,
"reduce_scatter": true,
"reduce_bucket_size": 5.000000e+08,
"allgather_partitions": true,
"allgather_bucket_size": 5.000000e+08,
"overlap_comm": false,
"load_from_fp32_weights": true,
"elastic_checkpoint": true,
"offload_param": null,
"offload_optimizer": null,
"sub_group_size": 1.000000e+09,
"prefetch_bucket_size": 5.000000e+07,
"param_persistence_threshold": 1.000000e+05,
"max_live_parameters": 1.000000e+09,
"max_reuse_distance": 1.000000e+09,
"gather_fp16_weights_on_model_save": false,
"ignore_unused_parameters": true,
"round_robin_gradients": false,
"legacy_stage1": false
}
[2021-10-21 23:14:05,895] [INFO] [config.py:944:print] zero_enabled ................. False
[2021-10-21 23:14:05,896] [INFO] [config.py:944:print] zero_optimization_stage ...... 0
[2021-10-21 23:14:05,896] [INFO] [config.py:946:print] json = {
"train_batch_size": 16,
"steps_per_print": 9.999999e+06
}
Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...
Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...
Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...
Emitting ninja build file /home/ubuntu/.cache/torch_extensions/utils/build.ninja...
Building extension module utils...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
Using /home/ubuntu/.cache/torch_extensions as PyTorch extensions root...
ninja: no work to do.
Loading extension module utils...
Time to load utils op: 0.6987707614898682 seconds
Loading extension module utils...
Time to load utils op: 0.30276012420654297 seconds
[2021-10-21 23:14:06,793] [INFO] [engine.py:77:__init__] CONFIG: micro_batches=1 micro_batch_size=16
Loading extension module utils...
Time to load utils op: 0.3035085201263428 seconds
Loading extension module utils...
Time to load utils op: 0.10213756561279297 seconds
[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=0 STAGE=0 LAYERS=4 [0, 4) STAGE_PARAMS=60647424 (60.647M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)
[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=1 STAGE=1 LAYERS=3 [4, 7) STAGE_PARAMS=21263616 (21.264M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)
[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=3 STAGE=3 LAYERS=4 [10, 14) STAGE_PARAMS=59862528 (59.863M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)
[2021-10-21 23:14:08,589] [INFO] [engine.py:135:__init__] RANK=2 STAGE=2 LAYERS=3 [7, 10) STAGE_PARAMS=21263616 (21.264M) TOTAL_PARAMS=163037184 (163.037M) UNIQUE_PARAMS=163037184 (163.037M)
WARNING:datasets.builder:Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)
100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 256.29it/s]
WARNING:datasets.builder:Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)
100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 472.65it/s]
0%| | 0/4800 [00:00<?, ?it/s]Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
0%| | 0/4800 [00:00<?, ?it/s]Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
1%|▌ | 68/4800 [00:00<00:07, 675.70it/s]WARNING:datasets.builder:Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)
100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 258.86it/s]
3%|█ | 136/4800 [00:00<00:07, 654.28it/s]WARNING:datasets.builder:Reusing dataset squad (/home/ubuntu/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453)
0%| | 0/4800 [00:00<?, ?it/s]Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 275.05it/s]
0%| | 0/4800 [00:00<?, ?it/s]Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.
100%|██████████████████████████████████████| 4800/4800 [00:04<00:00, 973.69it/s]
100%|██████████████████████████████████████| 4800/4800 [00:05<00:00, 954.25it/s]
100%|██████████████████████████████████████| 4800/4800 [00:04<00:00, 991.46it/s]
100%|██████████████████████████████████████| 4800/4800 [00:04<00:00, 978.01it/s]
/home/ubuntu/kevin/kevin_env/lib/python3.8/site-packages/deepspeed/runtime/pipe/engine.py:1067: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
if inputs.grad is not None:
/home/ubuntu/kevin/kevin_env/lib/python3.8/site-packages/deepspeed/runtime/pipe/engine.py:1067: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
if inputs.grad is not None:
/home/ubuntu/kevin/kevin_env/lib/python3.8/site-packages/deepspeed/runtime/pipe/engine.py:1067: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
if inputs.grad is not None:
step: 0, loss: 6.578999996185303
step: 10, loss: 1.040749192237854
step: 20, loss: 1.0263590812683105
step: 30, loss: 0.7057000398635864
step: 40, loss: 0.7450851798057556
step: 50, loss: 0.8148608207702637
step: 60, loss: 0.8103674650192261
step: 70, loss: 0.744097113609314
step: 80, loss: 0.6200798749923706
step: 90, loss: 0.5470073819160461
step: 100, loss: 0.6563196778297424
step: 110, loss: 0.5391805768013
step: 120, loss: 0.6279033422470093
step: 130, loss: 0.6154615879058838
step: 140, loss: 0.5165692567825317
step: 150, loss: 0.4756263792514801
step: 160, loss: 0.4647936522960663
step: 170, loss: 0.5400715470314026
step: 180, loss: 0.48079714179039
step: 190, loss: 0.41679126024246216
step: 200, loss: 0.44041475653648376
step: 210, loss: 0.39728063344955444
step: 220, loss: 0.364980012178421
step: 230, loss: 0.3382536768913269
step: 240, loss: 0.30256345868110657
step: 250, loss: 0.260995090007782
step: 260, loss: 0.2987060546875
step: 270, loss: 0.2671171724796295
step: 280, loss: 0.2043372541666031
step: 290, loss: 0.18478398025035858
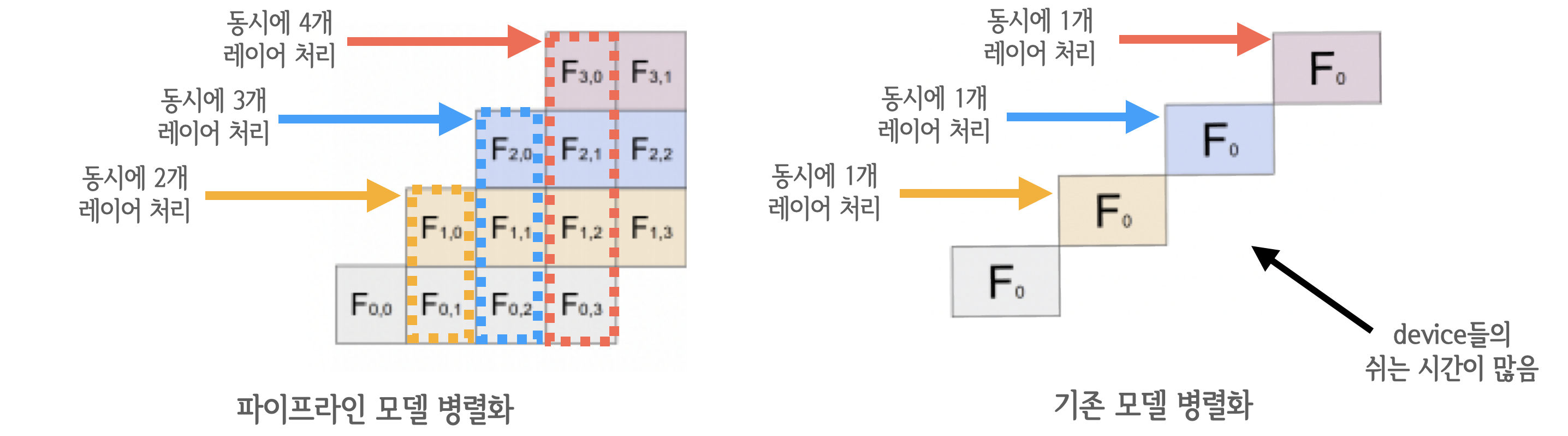
5. Interleaved Scheduling¶
이전에는 하나의 스테이지(연속된 레이어 집합)를 순차적으로 계산해서 결과 값을 출력했습니다. 예를 들면 8개의 레이어가 있고 2개의 디바이스가 주어졌다고 가정한다면, 일반적으로 1번 device에 1-4번 레이어, 2번 device에 5-8번 레이어에 할당되겠죠. 그러면 1번 device는 1~4번 레이어를 순차적으로 진행하여 출력했습니다. (GPipe, 1F1B 모두 이렇게 동작함)
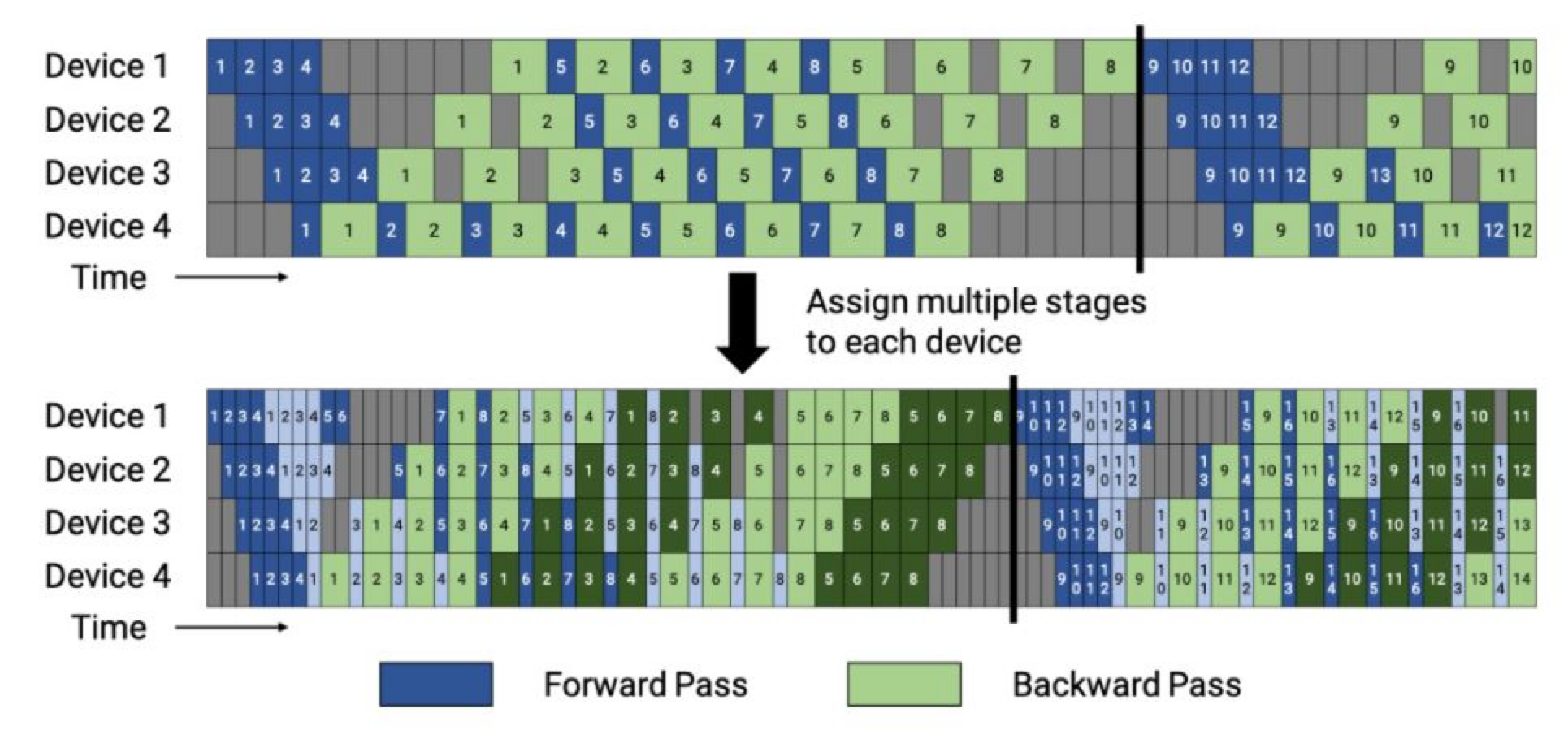
그러나 Interleaved Scheduling은 Bubble time을 극도로 줄이기 위해 하나의 스테이지를 중첩해서 진행합니다. 예를 들면 1번 device가 1-4번 레이어에 할당 되었다면, 1-2번 레이어의 동시에 3-4번 레이어를 동시에 수행합니다. 이렇게 되면 Bubble time은 줄어들지만 통신비용이 커지기 때문에 잘 조절할 필요가 있습니다. (트레이드 오프 존재)