Tokenization doesn't have to be slow !¶
Introduction¶
Before going deep into any Machine Learning or Deep Learning Natural Language Processing models, every practitioner should find a way to map raw input strings to a representation understandable by a trainable model.
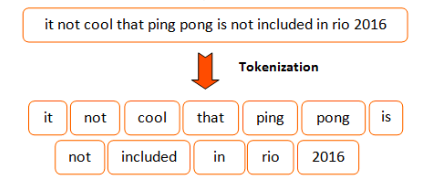
One very simple approach would be to split inputs over every space and assign an identifier to each word. This approach would look similar to the code below in python
s = "very long corpus..."
words = s.split(" ") # Split over space
vocabulary = dict(enumerate(set(words))) # Map storing the word to it's corresponding id
This approach might work well if your vocabulary remains small as it would store every word (or token) present in your original input. Moreover, word variations like "cat" and "cats" would not share the same identifiers even if their meaning is quite close.
Subtoken Tokenization¶
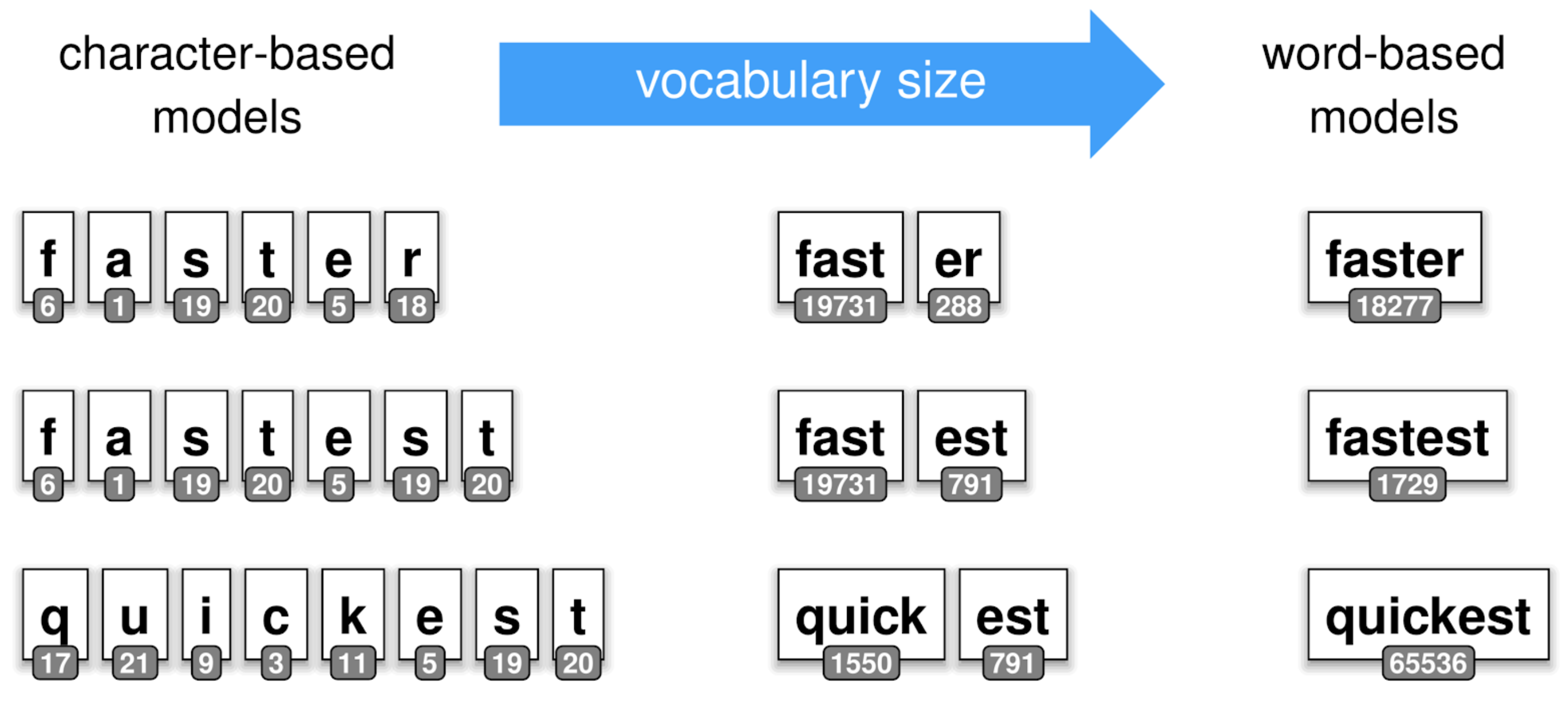
To overcome the issues described above, recent works have been done on tokenization, leveraging "subtoken" tokenization. Subtokens extends the previous splitting strategy to furthermore explode a word into grammatically logicial sub-components learned from the data.
Taking our previous example of the words cat and cats, a sub-tokenization of the word cats would be [cat, ##s]. Where the prefix "##" indicates a subtoken of the initial input. Such training algorithms might extract sub-tokens such as "##ing", "##ed" over English corpus.
As you might think of, this kind of sub-tokens construction leveraging compositions of "pieces" overall reduces the size of the vocabulary you have to carry to train a Machine Learning model. On the other side, as one token might be exploded into multiple subtokens, the input of your model might increase and become an issue on model with non-linear complexity over the input sequence's length.
Among all the tokenization algorithms, we can highlight a few subtokens algorithms used in Transformers-based SoTA models :
- Byte Pair Encoding (BPE) - Neural Machine Translation of Rare Words with Subword Units (Sennrich et al., 2015)
- Word Piece - Japanese and Korean voice search (Schuster, M., and Nakajima, K., 2015)
- Unigram Language Model - Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, T., 2018)
- Sentence Piece - A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Taku Kudo and John Richardson, 2018)
Going through all of them is out of the scope of this notebook, so we will just highlight how you can use them.
@huggingface/tokenizers library¶
Along with the transformers library, we @huggingface provide a blazing fast tokenization library able to train, tokenize and decode dozens of Gb/s of text on a common multi-core machine.
The library is written in Rust allowing us to take full advantage of multi-core parallel computations in a native and memory-aware way, on-top of which we provide bindings for Python and NodeJS (more bindings may be added in the future).
We designed the library so that it provides all the required blocks to create end-to-end tokenizers in an interchangeable way. In that sense, we provide these various components:
- Normalizer: Executes all the initial transformations over the initial input string. For example when you need to
lowercase some text, maybe strip it, or even apply one of the common unicode normalization process, you will add a Normalizer.
- PreTokenizer: In charge of splitting the initial input string. That's the component that decides where and how to
pre-segment the origin string. The simplest example would be like we saw before, to simply split on spaces.
- Model: Handles all the sub-token discovery and generation, this part is trainable and really dependant
of your input data.
- Post-Processor: Provides advanced construction features to be compatible with some of the Transformers-based SoTA
models. For instance, for BERT it would wrap the tokenized sentence around [CLS] and [SEP] tokens.
- Decoder: In charge of mapping back a tokenized input to the original string. The decoder is usually chosen according
to the PreTokenizer we used previously.
- Trainer: Provides training capabilities to each model.
For each of the components above we provide multiple implementations:
- Normalizer: Lowercase, Unicode (NFD, NFKD, NFC, NFKC), Bert, Strip, ...
- PreTokenizer: ByteLevel, WhitespaceSplit, CharDelimiterSplit, Metaspace, ...
- Model: WordLevel, BPE, WordPiece
- Post-Processor: BertProcessor, ...
- Decoder: WordLevel, BPE, WordPiece, ...
All of these building blocks can be combined to create working tokenization pipelines. In the next section we will go over our first pipeline.
Alright, now we are ready to implement our first tokenization pipeline through tokenizers.
For this, we will train a Byte-Pair Encoding (BPE) tokenizer on a quite small input for the purpose of this notebook. We will work with the file from Peter Norving. This file contains around 130.000 lines of raw text that will be processed by the library to generate a working tokenizer.
!pip install tokenizers
BIG_FILE_URL = 'https://raw.githubusercontent.com/dscape/spell/master/test/resources/big.txt'
# Let's download the file and save it somewhere
from requests import get
with open('big.txt', 'wb') as big_f:
response = get(BIG_FILE_URL, )
if response.status_code == 200:
big_f.write(response.content)
else:
print("Unable to get the file: {}".format(response.reason))
Now that we have our training data we need to create the overall pipeline for the tokenizer
# For the user's convenience `tokenizers` provides some very high-level classes encapsulating
# the overall pipeline for various well-known tokenization algorithm.
# Everything described below can be replaced by the ByteLevelBPETokenizer class.
from tokenizers import Tokenizer
from tokenizers.decoders import ByteLevel as ByteLevelDecoder
from tokenizers.models import BPE
from tokenizers.normalizers import Lowercase, NFKC, Sequence
from tokenizers.pre_tokenizers import ByteLevel
# First we create an empty Byte-Pair Encoding model (i.e. not trained model)
tokenizer = Tokenizer(BPE.empty())
# Then we enable lower-casing and unicode-normalization
# The Sequence normalizer allows us to combine multiple Normalizer that will be
# executed in order.
tokenizer.normalizer = Sequence([
NFKC(),
Lowercase()
])
# Our tokenizer also needs a pre-tokenizer responsible for converting the input to a ByteLevel representation.
tokenizer.pre_tokenizer = ByteLevel()
# And finally, let's plug a decoder so we can recover from a tokenized input to the original one
tokenizer.decoder = ByteLevelDecoder()
The overall pipeline is now ready to be trained on the corpus we downloaded earlier in this notebook.
from tokenizers.trainers import BpeTrainer
# We initialize our trainer, giving him the details about the vocabulary we want to generate
trainer = BpeTrainer(vocab_size=25000, show_progress=True, initial_alphabet=ByteLevel.alphabet())
tokenizer.train(trainer, ["big.txt"])
print("Trained vocab size: {}".format(tokenizer.get_vocab_size()))
Trained vocab size: 25000
Et voilà ! You trained your very first tokenizer from scratch using tokenizers. Of course, this
covers only the basics, and you may want to have a look at the add_special_tokens or special_tokens parameters
on the Trainer class, but the overall process should be very similar.
We can save the content of the model to reuse it later.
# You will see the generated files in the output.
tokenizer.model.save('.')
['./vocab.json', './merges.txt']
Now, let load the trained model and start using out newly trained tokenizer
# Let's tokenizer a simple input
tokenizer.model = BPE.from_files('vocab.json', 'merges.txt')
encoding = tokenizer.encode("This is a simple input to be tokenized")
print("Encoded string: {}".format(encoding.tokens))
decoded = tokenizer.decode(encoding.ids)
print("Decoded string: {}".format(decoded))
Encoded string: ['Ġthis', 'Ġis', 'Ġa', 'Ġsimple', 'Ġin', 'put', 'Ġto', 'Ġbe', 'Ġtoken', 'ized'] Decoded string: this is a simple input to be tokenized
The Encoding structure exposes multiple properties which are useful when working with transformers models
- normalized_str: The input string after normalization (lower-casing, unicode, stripping, etc.)
- original_str: The input string as it was provided
- tokens: The generated tokens with their string representation
- input_ids: The generated tokens with their integer representation
- attention_mask: If your input has been padded by the tokenizer, then this would be a vector of 1 for any non padded token and 0 for padded ones.
- special_token_mask: If your input contains special tokens such as [CLS], [SEP], [MASK], [PAD], then this would be a vector with 1 in places where a special token has been added.
- type_ids: If your input was made of multiple "parts" such as (question, context), then this would be a vector with for each token the segment it belongs to.
- overflowing: If your input has been truncated into multiple subparts because of a length limit (for BERT for example the sequence length is limited to 512), this will contain all the remaining overflowing parts.