CS236781: Deep Learning¶
Tutorial 6: Object Detection¶
Introduction¶
In this tutorial, we will cover:
- What is the Object Detection
- Sliding Windows Approach
- Performance Metrics
- Region-based Convolutional Neural Networks (R-CNN) Family
- You Only Look Once (YOLO) Family
This tutorial is heavly based on Technion:EE046746 tutorial
# Setup
%matplotlib inline
import os
import sys
import torch
import torchvision
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 20
data_dir = os.path.expanduser('~/.pytorch-datasets')
What Is Object Detection¶
Recall:
- Image classification takes an image and predicts the object in an image. For example, when we build a cat-dog classifier, we take images of cat or dog and predict their class:

- Object localization - find the location of the cat or the dog. The problem of identifying the location of an object in an image is called localization.
- If the object class is not known, we have to predict both the location and the class of each object!

What challengins setup can it solve for us?
What do we see here?

Classification and localization for multiple instances is called Object Detection
Where this lays in scene understanding?¶

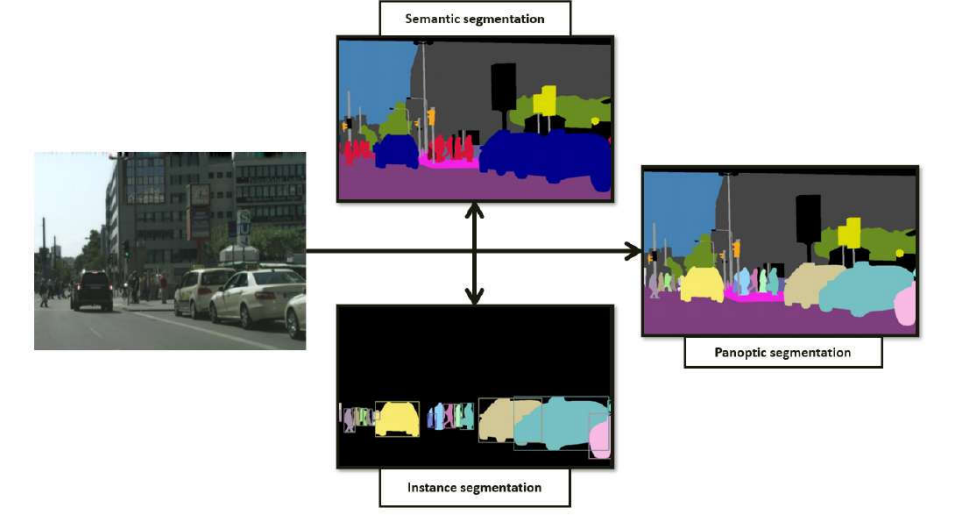
- The instance segmentation task requires a method to segment each object instance in an image. However, it allows overlapping segments, whereas the panoptic segmentation task permits only one semantic label and one instance id to be assigned to each pixel.

Problems
how do you know the size of the window so that it always contains the image?
Let's say that the window predicted the class, how do we know it's a good rectengle?

- As you can see that the object can be of varying sizes.
- To solve this problem an image pyramid is created by scaling the image.
- The idea is to resize the image at multiple scales and rely on the fact that our chosen window size will completely contain the object in one of these resized images.
- Most commonly, the image is downsampled (size is reduced) until a certain condition, typically a minimum size, is reached.
- A fixed size window detector is run on each of these images.
- It’s common to have as many as 64 levels on such pyramids. Now, all these windows are fed to a classifier to detect the object of interest.
- This approach can be very expensive computationally, and thus very slow.

The output of the algorithms are usually conducted from 5 outputs:
- class score
and 4 that determine the bounding box:
top_left_xtop_left_ywidthheight
 Performance Metrics
Performance Metrics
How can we tell if the predicted bounding box is good with respect to the ground truth (labeled) bounding box?
The evaluation score is usually mean Average Precision (mAP)
For that we're also going to talk about intersection over union (IoU)
Average Precision (AP)¶
First, let's remember some definisions.
| confusion matrix | precision and recall |
|---|---|
 |
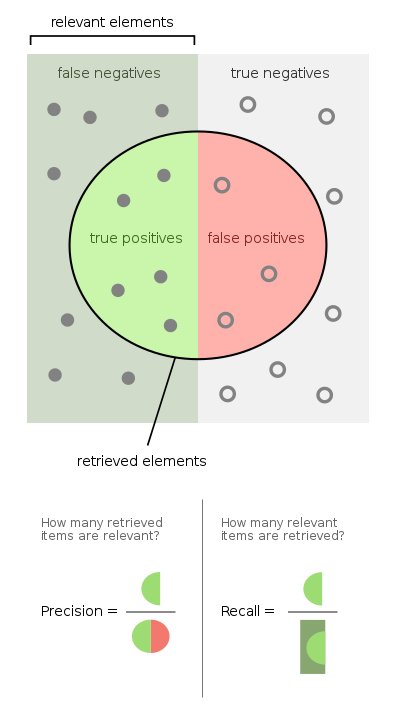 |
Precision is a measure of when ""your model predicts how often does it predicts correctly?"" It indicates how much we can rely on the model's positive predictions.
Recall is a measure of ""has your model predicted every time that it should have predicted?"" It indicates any predictions that it should not have missed if the model is missing.
Intersection over Union (IoU)¶
Also called the Jaccard Index, $$ IoU = \frac{TP}{TP + FP+ FN} = \frac{\mid X \cap Y \mid}{\mid X \mid + \mid Y \mid - \mid X \cap Y \mid} $$
- $X$ and $Y$ are the predicted and ground truth segmentation, respectively.
- TP is the true positives, FP false positives and FN false negatives.

- Image Source: Wikipedia
Yeild a value between 0 and 1 and The higher the IoU, the better the predicted location of the box for a given object.
Typical threshold for detection: 0.5
We can check what is the P and R for each threshold:

- what is high threshold?
and define a AP-AUC

In practice, we choose a small set of thresholds and aproximate the area as follow:

we do that for all the instances of a class in the dataset!
The mean Average Precision (mAP) is the mean of the Average Precisions computed over all the classes of the challenge.
- Let $C$ be the number of classes:
Typically OD models are devided to two categories:
- Two stage (RCNN)
- One stage (YOLO)
 Region-based Convolutional Neural Networks (R-CNN) Family
Region-based Convolutional Neural Networks (R-CNN) Family
- The problem with combining CNNs with the sliding window approach is that CNNs are too slow and computationally very expensive. It is practically impossible to run CNNs on so many patches generated by a sliding window detector.
- The R-CNN family of methods refers to the R-CNN, which may stand for “Regions with CNN Features” or “Region-Based Convolutional Neural Network,” developed by Ross Girshick, et al.
- This includes the techniques R-CNN, Fast R-CNN, and Faster-RCNN designed and demonstrated for object localization and object recognition.
 R-CNN
R-CNN
- The R-CNN was introduced in the 2014 paper by Ross Girshick, et al. from UC Berkeley titled “Rich feature hierarchies for accurate object detection and semantic segmentation.
- It may have been one of the first large and successful application of convolutional neural networks to the problem of object localization, detection, and segmentation.
- The approach was demonstrated on benchmark datasets, achieving then state-of-the-art results on the VOC-2012 dataset and the 200-class ILSVRC-2013 object detection dataset.
- The R-CNN model is comprised of three modules:
- Module 1: Region Proposal - generate and extract category independent region proposals, e.g. candidate bounding boxes.
- Module 2: Feature Extractor - extract feature from each candidate region, e.g. using a deep convolutional neural network.
- Module 3: Classifier - classify features as one of the known class, e.g. linear SVM classifier model.

Module 1 - Region Proposal¶
- Selective Search - computer vision technique that is used to propose candidate regions or bounding boxes of potential objects in the image (by over segment with graph-based segmentation method)
- Stage 1 - calculate initial regions.
- Stage 2 - group regions with the highest similarity - repeat.
- Stage 3 - generate a hierarchy of bounding boxes.
- Selective search uses local cues like texture, intensity, color and/or a measure of insideness and etc to generate all the possible locations of the object.

Module 2 - Feature Extractor¶
- A feature vector of 4,096 dimensions is extracted for each object proposal using a CNN.
- The feature extractor used by the model was the AlexNet deep CNN that won the ILSVRC-2012 image classification competition.
- Problem - the input of the CNN should be a fixed size (224x224) but the size of each proposal is different.
- The size of the objects must be changed to a fixed size!
- Solution - use warping - anisotropically scales the object proposals (different scale in two directions).
- The choice of the CNN architecture has a large effect on the detection performance (obviously...).

Module 3 - Classifier¶
- The output of the CNN was a 4,096 element vector that describes the contents of the image that is fed to a linear SVM for classification, specifically one SVM is trained for each known class.
- Why use SVM and not a Softmax layer? It empirically worked better.

Training R-CNNs¶
- Training the CNN:
- R-CNNs uses pre-trained CNNs.
- Adapting Uses proposals with $IoU > 0.5$ as positive examples (the rest are negative).
- Training the SVM:
- Uses proposals with $IoU < 0.3$ as negative examples and ground truth regions as positive examples.
- Why is it different than the CNN threshold? It empirically works better and reduces overfitting.
- Uses proposals with $IoU < 0.3$ as negative examples and ground truth regions as positive examples.
Detecting Objects with R-CNNs¶
- At test time, non-maximum suppression (NMS) is applied greedily given all scored regions in an image.
- Non-Maximum Supression (NMS) - a technique which filters the proposals based on some threshold value (rejects proposals).
- Input: A list of Proposal boxes $B$, corresponding confidence scores $S$ and overlap threshold $N$.
- Output: A list of filtered proposals $D$.

Drawbacks of R-CNN¶
- Training is not end-to-end, but a multi-stage pipeline.
- Trainning is computationally expensive in space and time (training a deep CNN on so many region proposals per image is very slow).
- At test-time object-detection is slow, requiring a CNN-based feature extraction to pass on each of the candidate regions generated by the region proposal algorithm.

 Fast R-CNNs
Fast R-CNNs
- Given the great success of R-CNN, Ross Girshick, proposed an extension to address the speed issues of R-CNN in a 2015 paper titled “Fast R-CNN”.
- Fast R-CNN is proposed as a single-stage model instead of a pipeline to learn and output regions and classifications directly.
- Fast RCNN combined the bounding box regression and classification in the neural network training itself.
- Now the network has two heads, classification head, and bounding box regression head.
- The architecture of the model takes the photograph and a set of region proposals (from a selective search) as input that are passed through a deep convolutional neural network.
- A pre-trained CNN, such as a VGG-16, is used for feature extraction.
- The end of the deep CNN is a custom layer called a Region of Interest Pooling Layer, or RoI Pooling, that extracts features specific for a given input candidate region.


- The output of the CNN is then interpreted by a fully connected layer then the model has two outputs, one for the class prediction via a Softmax layer, and another with a linear output for the bounding box.
- This process is then repeated multiple times for each region of interest in a given image.

- Significantly faster both train and inference
- Faster detection uses Truncated SVD to compresses the FC, reduces detection time by 30% with small drop in mAP.
 Faster R-CNNs
Faster R-CNNs
- The slowest part in Fast RCNN was Selective Search or Edge boxes.
- The Fast RCNN model architecture was further improved for both speed of training and detection by Shaoqing Ren, et al. in the 2016 paper titled “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”.
- The architecture was the basis for the first-place results achieved on both the ILSVRC-2015 and MS COCO-2015 object recognition and detection competition tasks.
- The idea was to replace selective search with a very small convolutional network called Region Proposal Network to generate regions of Interests.

- The architecture was designed to both propose and refine region proposals as part of the training process, referred to as a Region Proposal Network, or RPN.
- These regions are then used in concert with a Fast R-CNN model in a single model design.
- These improvements both reduce the number of region proposals and accelerate the test-time operation of the model to near real-time with then state-of-the-art performance.
- The architecture is comprised of two modules:
- Module 1: Region Proposal Network - CNN for proposing regions and the type of object to consider in the region.
- Module 2: Fast R-CNN - CNN for extracting features from the proposed regions and outputting the bounding box and class labels.
- Both modules operate on the same output of a deep CNN.
- The region proposal network acts as an attention mechanism for the Fast R-CNN network, informing the second network of where to look or pay attention.
- The RPN works by taking the output of a pre-trained deep CNN, such as VGG-16, and passing a small network over the feature map and outputting multiple region proposals and a class prediction for each.
- Region proposals are bounding boxes, based on anchor boxes or pre-defined shapes designed to accelerate and improve the proposal of regions.
- The class prediction is binary, indicating the presence of an object, or not, so-called “objectness” of the proposed region.
- RPN Steps:
- Generate anchor boxes.
- Feed the possible regions into the RPN and classify each anchor box whether it is foreground or background (anchors that have a higher overlap with ground-truth boxes should be labeled as foreground, while others should be labeled as background).
- The output is fed into a Softmax or logistic regression activation function, to predict the labels for each anchor. A similar process is used to refine the anchors and define the bounding boxes for the selected features (learn the shape offsets for anchor boxes to fit them for objects).

- Faster-RCNN is 10 times faster than Fast-RCNN with similar accuracy of datasets like VOC-2007.
- That is why Faster-RCNN is one of the most accurate object detection algorithms.
| R-CNN | Fast R-CNN | Faster R-CNN | |
|---|---|---|---|
| Test Time Per Image (sec) | 50 | 2 | 0.2 |
| Speed Up | 1x | 25x | 250x |

 R-CNN Family Implementations
R-CNN Family Implementations
- R-CNN, Fast R-CNN, Faster R-CNN and even Mask R-CNN are all implemented in Detectron2 for PyTorch.
- It is better to use Faster R-CNN or Mask R-CNN (if you need segmentation).
- Detectron2 for PyTorch

 You Only Look Once (YOLO) Family
You Only Look Once (YOLO) Family
- All the methods discussed above handled detection as a classification problem by building a pipeline where first object proposals are generated and then these proposals are sent to classification/regression heads.
- Another popular family of object recognition models is referred to collectively as YOLO or “You Only Look Once,” developed by Joseph Redmon, et al. which is a regression-based detection method.
- The R-CNN models may be generally more accurate, yet the YOLO family of models are fast, much faster than R-CNN, achieving object detection in real-time.
- YOLO Official Website
YOLO (v1)¶
- The YOLO model was first described by Joseph Redmon, et al. in the 2015 paper titled “You Only Look Once: Unified, Real-Time Object Detection”.
- The approach involves a single neural network trained end-to-end that takes an image as input and predicts bounding boxes and class labels for each bounding box directly.
- The technique offers lower predictive accuracy (e.g. more localization errors), although operates at 45 frames per second and up to 155 frames per second for a speed-optimized version of the model.
- First, split the image into a grid of cells, where each cell is responsible for predicting a bounding box if the center of a bounding box falls within it.
- YOLO divides each image into a grid of $S \times S$ and each grid cell predicts $N$ (usually $N=2$) bounding boxes and confidence where a bounding box involving the $x, y$ coordinate, the width, the height and the confidence.
- The confidence reflects the accuracy of the bounding box and whether the bounding box actually contains an object (regardless of class).
- YOLO uses Non-Maximal Suppression (NMS) to only keep the best bounding box. The first step in NMS is to remove all the predicted bounding boxes that have a detection probability that is less than a given NMS threshold.
- YOLO also predicts the classification score for each box for every class in training.
- A total $S\times S \times N$ boxes are predicted. However, most of these boxes have low confidence scores.


- $B$ is the number of bounding boxes from each cell, $C$ is the number of classes.
- Image Source
There is no change in test time.
YOLO sees the complete image at once as opposed to looking at only a generated region proposals.
One limitation for YOLO is that it only predicts one type of class in one grid cell. Hence, it struggles with very small objects.
YOLO v2¶
- The model was updated by Joseph Redmon and Ali Farhadi in an effort to further improve model performance in their 2016 paper titled "YOLO9000: Better, Faster, Stronger".

https://soundcloud.com/tsirifein/daft-punk-harder-better-faster-stronger-trfn-remix
Main Improvements¶
BatchNorm
Image resolution matters: Fine-tuning the base model with high resolution images improves the detection performance.
Convolutional anchor box detection: like in faster R-CNN.
K-mean clustering of box dimensions: Different from faster R-CNN that uses hand-picked sizes of anchor boxes, YOLOv2 runs k-mean clustering on the training data to find good priors on anchor box dimensions.
- Direct location prediction: YOLOv2 formulates the bounding box prediction in a way that it would not diverge from the center location too much.

Add fine-grained features: YOLOv2 adds a passthrough layer to bring fine-grained features from an earlier layer to the last output layer. The mechanism of this passthrough layer is similar to identity mappings in ResNet to extract higher-dimensional features from previous layers.
Multi-scale training.
Light-weighted base model: To make prediction even faster, YOLOv2 adopts a light-weighted base model, DarkNet-19, which has 19 conv layers and 5 max-pooling layers. The key point is to insert avg poolings and 1x1 conv filters between 3x3 conv layers.
Reach data: made use of Imagenet Dataset as well, used a graph distance to determine the class.
YOLO v3¶
- Further improvements to the model were proposed by Joseph Redmon and Ali Farhadi in their 2018 paper titled "YOLOv3: An Incremental Improvement".
- The objectness score uses sigmoid.
- Switched from multiclass classification to multilabel classification, so no softmaxes in favor of binary cross-entropy.
- Predictions are made for bboxes at three scales, output tensor size: N * N * B * (3 * (4 + 1 + num_classes))
- New, deeper, and more accurate backbone/feature extractor Darknet-53 (omparable to ResNet-152, but with 1.5 times fewer operations-> double the FPS on GPU).
 YOLO v4
YOLO v4
- In 2020, a major improvement to the YOLO model was intorduced in the paper YOLOv4: Optimal Speed and Accuracy of Object Detection.
- YOLOv4’s architecture is composed of CSPDarknet53 (CSP: Cross-Stage-Partial connections, separating the current layer into 2 parts, one that will go through a block of convolutions, and one that won’t and then aggregate the results) as a backbone, spatial pyramid pooling additional module, PANet path-aggregation neck and YOLOv3 head.
- Bag-Of-Freebies (BoF) and Bag-Of-Specials (BoS) - improvements such as strong augementations, regularizations and special activations.
- YOLOv4 PyTorch Code

- AP (Average Precision) and FPS (Frames Per Second) increased by 10% and 12% compared to YOLOv3

Other then that¶
We do not have the time to cover all the algorithms exist.
If you want to dive deeper i recommand to look at:
- Retina Net - introduce the focall loss
EfficientDet - NAS based detector
SSD in pytorch- Single Shot MultiBox Detector model for object detection
After we will see the vision transofrmers, you can also look at
At any time, you can find the state of the art models in here
Credits
This tutorial was written by Moshe Kimhi.
To re-use, please provide attribution and link to the original.
some content from:
images without specific credit:
- Panoptic Segmentation: A Review