CS236781: Deep Learning¶
Tutorial 10: Transformers¶

Introduction¶
In this tutorial, we will cover:
- Attention is all you need
- Some of the characters of sesame street
- GPT

# Setup
%matplotlib inline
import os
import sys
import math
import time
import tqdm
import torch
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.simplefilter("ignore")
# pytorch
import torch
import torch.nn as nn
import torchtext
import torchtext.data as data
import torchtext.datasets as datasets
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
plt.rcParams['font.size'] = 20
data_dir = os.path.expanduser('~/.pytorch-datasets')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Theory reminders¶
Attention¶
We've talked about the perpues of attention and the motivation resreach for deep learning attention mechanisem

We also defined the scaled dot product attention as:
$$ \begin{align} \mat{B} &= \frac{1}{\sqrt{d}} \mat{Q}\mattr{K} \ \in\set{R}^{m\times n} \\ \mat{A} &= \softmax{\mat{B}}_{\mathrm{dim}=1}, \in\set{R}^{m\times n} \\ \mat{Y} &= \mat{A}\mat{V} \ \in\set{R}^{m\times d_v}. \end{align} $$where K,Q and V for the self attention came as projections of the same input sequnce
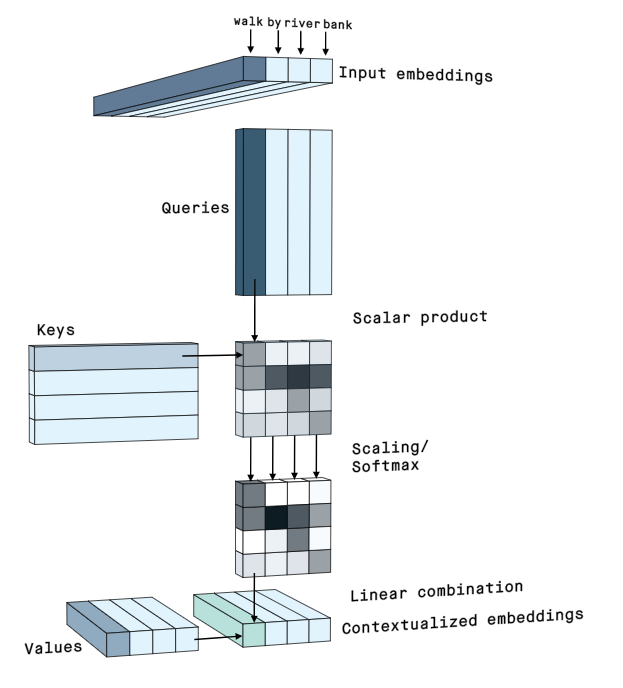
Encoder-decoder architectures¶
A common architecture used in many tasks is the encoder-decoder pattern.
- The encoder maps the input to some latent representation, usually of a low dimension.
- The decoder applies a different mapping, from the latent space to some other space (sometimes back to the input space).
We implemented encoder-decoder with and without attention
| A | B |
|---|---|
 |
 |
All you need is love, or attention¶
Before the tresformers¶
Before the transformer architecture, each family of problems, was ruled by a diffrent architecture, commonly sharing only few characteristics:

Recap of the attention mechanisem:

image by jay alammar
In a matrix stack:


image by jay alammar
def scaled_dot_product(q, k, v, mask=None):
d_k = q.size()[-1]
attn_logits = torch.matmul(q, k.transpose(-2, -1))
attn_logits = attn_logits / math.sqrt(d_k)
if mask is not None:
attn_logits = attn_logits.masked_fill(mask == 0, -9e15)
attention = F.softmax(attn_logits, dim=-1)
values = torch.matmul(attention, v)
return values, attention
seq_len, d_k = 3, 2
q = torch.randn(seq_len, d_k)
k = torch.randn(seq_len, d_k)
v = torch.randn(seq_len, d_k)
values, attention = scaled_dot_product(q, k, v)
print("Q\n", q)
print("K\n", k)
print("V\n", v)
print("Values\n", values)
print("Attention\n", attention)
Q
tensor([[ 0.0842, 0.6029],
[ 2.2176, -0.9276],
[-1.0193, 0.1904]])
K
tensor([[ 0.4362, 0.8059],
[ 1.1931, -0.3469],
[ 0.5787, 0.5497]])
V
tensor([[ 0.8489, 0.3791],
[-0.9486, 0.4248],
[ 1.4218, -2.1640]])
Values
tensor([[ 0.6004, -0.5132],
[-0.3879, 0.0152],
[ 0.6832, -0.5476]])
Attention
tensor([[0.3931, 0.2515, 0.3554],
[0.1057, 0.7379, 0.1564],
[0.4223, 0.2095, 0.3682]])
The paper further refined the self-attention layer by adding a mechanism called “multi-headed” attention. (We're all about childhood today..)

How do we do that?

Can it improve the performance of the attention layer?
It expands the model’s ability to focus on different positions. For eample
The child didn’t cross the street because it was too busy, diffrent heads can give diffrent interpertation. once thechildwas too busy, and another where thestreetwas busy. That way two heads have diffrent meaning and we want the model to capture the ambiguity in language.It learn diffrent attention score (NxN!), as it used diffrent
Q,K,V, when we look at meaning, sometimes we give more attention to diffrent parts of the sentence. If i ask you who didn't cross the road, the focus of the answer is onThe child, while when i ask why, the focus is onit was busy. We want a mechanisem that can answer several questions.
class MultiheadAttention(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "Embedding dimension must be 0 modulo number of heads."
#this is the q,k,v total embeding dim
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# Stack all weight matrices 1...h together for efficiency
self.qkv_proj = nn.Linear(input_dim, 3*embed_dim)
self.o_proj = nn.Linear(embed_dim, embed_dim)
self._reset_parameters()
def _reset_parameters(self):
# Original Transformer initialization, see PyTorch documentation of the paper if you like to
nn.init.xavier_uniform_(self.qkv_proj.weight)
self.qkv_proj.bias.data.fill_(0)
nn.init.xavier_uniform_(self.o_proj.weight)
self.o_proj.bias.data.fill_(0)
def forward(self, x, mask=None, return_attention=False):
#this is the input embed dim
batch_size, seq_length, embed_dim = x.size()
qkv = self.qkv_proj(x) #[Batch, SeqLen, 3*total_embed]
# Separate Q, K, V from linear output
qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3*self.head_dim)
qkv = qkv.permute(0, 2, 1, 3) # [Batch, Head, SeqLen, 3*Dims]
q, k, v = qkv.chunk(3, dim=-1) #[Batch, Head, SeqLen, Dims]
# Determine value outputs
values, attention = scaled_dot_product(q, k, v, mask=mask)
values = values.permute(0, 2, 1, 3) # [Batch, SeqLen, Head, Dims]
values = values.reshape(batch_size, seq_length, embed_dim) #concatination all heads
o = self.o_proj(values)
if return_attention:
return o, attention
else:
return o
seq_len,input_dim, embed_dim = 20,10,10
x = torch.randn(4,seq_len,input_dim)
MhA= MultiheadAttention(input_dim, embed_dim, embed_dim//4)
out,a = MhA(x,return_attention=True)
print(f'MHA output: {out.shape}, attn shape: {a.shape}')
MHA output: torch.Size([4, 20, 10]), attn shape: torch.Size([4, 2, 20, 20])
You can analize the attention scores in here
Recall for the transformer:

feed forward is simply an MLP with GELU activision:
$GELU(x) = x P(X\le x) = x \times \frac{1}{2} [1+ erf(x/\sqrt(2)]$
https://en.wikipedia.org/wiki/Error_function
can also be aproximate by $0.5x (1+ tanh[\sqrt{(2/\pi)} (x+0.044715x^3)]$
#remember?
def elu_forward(z, alpha):
elu_positive = z
elu_negative = alpha * (torch.exp(z) - 1)
elu_output = torch.where(z>0, elu_positive, elu_negative)
return elu_output
def gelu_forward(z,type=1):
if type==1:
return 0.5*z*(1+torch.erf(z/np.sqrt(2)))
return 0.5*z*(1+torch.tanh(np.sqrt(2/np.pi)*(z+0.044715*z**3)))
z = torch.linspace(-5, 5, steps=1000)
plt.plot(z.numpy(), torch.relu(z).numpy(), label='ReLU(z)', linewidth=5);
plt.plot(z.numpy(), elu_forward(z, alpha=.5).numpy(), label='ELU(z)', linewidth=2);
plt.plot(z.numpy(), gelu_forward(z).numpy(), label='GELU(z)', linewidth=2);
plt.legend(); plt.grid();

z = torch.linspace(-5, 5, steps=10000)
plt.plot(z.numpy(), gelu_forward(z).numpy(), label='GELU', linewidth=2);
plt.plot(z.numpy(), gelu_forward(z,2).numpy(), label='GELU tanh aprox', linewidth=2);
plt.legend(); plt.grid();
(gelu_forward(z)- gelu_forward(z,2)).abs().sum()
tensor(1.6022)

There is one major drawback that we didn't refer to so far, can you guess what it is?
Positional Encoding¶
Untill now, we saw a strong tool for learning, but if a token came as the first word in the sentence, or as last, we only learned the power of the relation between them, the order did not matter!
The positional encoding is an idea that reminds Spectral decomposition, like Fourier series, based just on the positions.
The basis is Sin and Cosin functions with different frequencies as coefficients (2pi, 4pi…)
The reason of that is that we want to push each embedding a bit to encode the position as well as the meaning, but we also want it to have the same norm (why?)
It's not special for text, as you saw in the lecture VIT use something similar. When we don't need to add PE?
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
"""
Inputs
d_model - Hidden dimensionality of the input.
max_len - Maximum length of a sequence to expect.
"""
super().__init__()
# Create matrix of [SeqLen, HiddenDim] representing the positional encoding for max_len inputs
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
# register_buffer => Tensor which is not a parameter, but should be part of the modules state.
# Used for tensors that need to be on the same device as the module.
# persistent=False tells PyTorch to not add the buffer to the state dict (e.g. when we save the model)
self.register_buffer('pe', pe, persistent=False)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
encod_block = PositionalEncoding(d_model=48, max_len=96)
pe = encod_block.pe.squeeze().T.cpu().numpy()
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8,3))
pos = ax.imshow(pe, cmap="RdGy", extent=(1,pe.shape[1]+1,pe.shape[0]+1,1))
fig.colorbar(pos, ax=ax)
ax.set_xlabel("Position in sequence")
ax.set_ylabel("Hidden dimension")
ax.set_title("Positional encoding over hidden dimensions")
ax.set_xticks([1]+[i*10 for i in range(1,1+pe.shape[1]//10)])
ax.set_yticks([1]+[i*10 for i in range(1,1+pe.shape[0]//10)])
plt.show()

#!pip install seaborn #- if it's not part of the requrement file
import seaborn as sns
import numpy as np
sns.set_theme()
fig, ax = plt.subplots(2, 2, figsize=(12,4))
ax = [a for a_list in ax for a in a_list]
for i in range(len(ax)):
ax[i].plot(np.arange(1,17), pe[i,:16], color=f'C{i}', marker="o", markersize=6, markeredgecolor="black")
ax[i].set_title(f"Encoding in hidden dimension {i+1}")
ax[i].set_xlabel("Position in sequence", fontsize=10)
ax[i].set_ylabel("Positional encoding", fontsize=10)
ax[i].set_xticks(np.arange(1,17))
ax[i].tick_params(axis='both', which='major', labelsize=10)
ax[i].tick_params(axis='both', which='minor', labelsize=8)
ax[i].set_ylim(-1.2, 1.2)
fig.subplots_adjust(hspace=0.8)
sns.reset_orig()
plt.show()

Ways to use it in NLP¶
- Text-To-Text Transfer Transformer (T5): Translation, summerization, question answering and so on.
* **B**idirectional **E**ncoder **R**epresentations from **T**ransformers (BERT): **Encoder only!** mask prediction over one sequnce, can be use for error fixing, wordtune/gramerly etc..
* **G**enerative **P**re**T**raining (GPT): **Decoder only!**. Generate text, stories using nothing but initial tokens.

BRRT¶

Uses pre-training of semi (self) supervision of two tasks:
- masked prediction: mask out 15% of the tokens and predict them using bi-directional encoding of the sentense.
make use of the spacial token [MASK] instead of some of the inputs
- NSP: Next sentence prediction: predict if the next sentence come after the current one or not.
sentences of the same paragraph comes one after the other with a seperation of the special token [SEP]
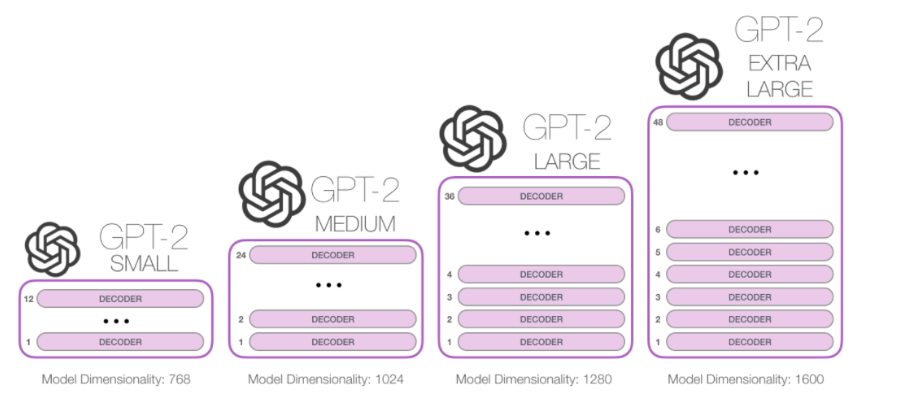
GPT¶

GPT4: 100 Trillion PARAMS!
What's next? i call it The moor's law of parameters:

From a survey on LLM
Let's try to work with something that is way to big to train here, but we can play with a pre-trained version: GPT2:
!pip install transformers
Collecting transformers
Downloading transformers-4.38.2-py3-none-any.whl.metadata (130 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 130.7/130.7 kB 1.2 MB/s eta 0:00:00a 0:00:01
Requirement already satisfied: filelock in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (3.13.1)
Collecting huggingface-hub<1.0,>=0.19.3 (from transformers)
Downloading huggingface_hub-0.21.4-py3-none-any.whl.metadata (13 kB)
Requirement already satisfied: numpy>=1.17 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (1.24.4)
Requirement already satisfied: packaging>=20.0 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (23.2)
Requirement already satisfied: pyyaml>=5.1 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (6.0.1)
Requirement already satisfied: regex!=2019.12.17 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (2023.12.25)
Requirement already satisfied: requests in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (2.31.0)
Collecting tokenizers<0.19,>=0.14 (from transformers)
Downloading tokenizers-0.15.2-cp38-cp38-macosx_11_0_arm64.whl.metadata (6.7 kB)
Collecting safetensors>=0.4.1 (from transformers)
Downloading safetensors-0.4.2-cp38-cp38-macosx_11_0_arm64.whl.metadata (3.8 kB)
Requirement already satisfied: tqdm>=4.27 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from transformers) (4.66.1)
Requirement already satisfied: fsspec>=2023.5.0 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from huggingface-hub<1.0,>=0.19.3->transformers) (2023.12.2)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from huggingface-hub<1.0,>=0.19.3->transformers) (4.9.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from requests->transformers) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from requests->transformers) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from requests->transformers) (2.1.0)
Requirement already satisfied: certifi>=2017.4.17 in /Users/moshekimhi/miniconda3/envs/cs236781/lib/python3.8/site-packages (from requests->transformers) (2023.11.17)
Downloading transformers-4.38.2-py3-none-any.whl (8.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.5/8.5 MB 24.4 MB/s eta 0:00:00a 0:00:01
Downloading huggingface_hub-0.21.4-py3-none-any.whl (346 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 346.4/346.4 kB 6.3 MB/s eta 0:00:00ta 0:00:01
Downloading safetensors-0.4.2-cp38-cp38-macosx_11_0_arm64.whl (392 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 392.9/392.9 kB 5.8 MB/s eta 0:00:00ta 0:00:01
Downloading tokenizers-0.15.2-cp38-cp38-macosx_11_0_arm64.whl (2.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.4/2.4 MB 10.9 MB/s eta 0:00:00a 0:00:01
Installing collected packages: safetensors, huggingface-hub, tokenizers, transformers
Successfully installed huggingface-hub-0.21.4 safetensors-0.4.2 tokenizers-0.15.2 transformers-4.38.2
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
config.json: 0%| | 0.00/665 [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/548M [00:00<?, ?B/s]
generation_config.json: 0%| | 0.00/124 [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/26.0 [00:00<?, ?B/s]
vocab.json: 0%| | 0.00/1.04M [00:00<?, ?B/s]
merges.txt: 0%| | 0.00/456k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/1.36M [00:00<?, ?B/s]
completes = generator("if i had a nickel for every time a student asked me ", max_length=50, num_return_sequences=5)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
for i, sentence in enumerate(completes):
print(f'===generated sentence number {i}: ===')
print(' ' + sentence['generated_text']+ '\n\n')
===generated sentence number 0: === if i had a nickel for every time a student asked me or who I had seen the pictures of my friends at IITs, etc. and they never answered my questions. People I knew would ask when she could, and ===generated sentence number 1: === if i had a nickel for every time a student asked me to take a class that had been handed out that day, i would have put in 10 bucks for each class. So now you have three months to do your homework to pay the ===generated sentence number 2: === if i had a nickel for every time a student asked me *********************/ This is why it's just easier to be honest. This is another way to see the student that has a lot of misconceptions about the industry as a whole. ===generated sentence number 3: === if i had a nickel for every time a student asked me how much candy I bought, I could get one extra pound a year from them because school wasn't paying enough on the bills, I also could have candy ===generated sentence number 4: === if i had a nickel for every time a student asked me to sell something, then I would just try to do it in the name of 'value'. A student at a big state school who is trying to earn more than $1
We can also explore some of the biases of the LLMs, since they are trained in a self-supervised fashion, the biases are just what can be found online:
generator("This man worked as a", max_length=10, num_return_sequences=5)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'This man worked as a private detective for the district'},
{'generated_text': 'This man worked as a bartender but as a writer'},
{'generated_text': 'This man worked as a nurse. He was not'},
{'generated_text': 'This man worked as a janitor in the city'},
{'generated_text': "This man worked as a lab assistant. We're"}]
generator("This woman worked as a", max_length=10, num_return_sequences=5)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'This woman worked as a waitress at a grocery store'},
{'generated_text': 'This woman worked as a janitor and was married'},
{'generated_text': 'This woman worked as a nurse and got married on'},
{'generated_text': 'This woman worked as a waitress at a local grocery'},
{'generated_text': 'This woman worked as a kitchen cleaner here before moving'}]
Thank you¶
Credits
This tutorial was written by Moshe Kimhi .
To re-use, please provide attribution and link to the original.
Some images in this tutorial were taken and/or adapted from the following sources:
- Jay Alammar blog - https://jalammar.github.io/illustrated-transformer/
- Attention is all you need paper - https://arxiv.org/abs/1706.03762
- Lucas Beyer - transformer presentation