Installation¶
First, let's start with the installation:
✅ Tip - If you're new to fastdup, we encourage you to run the notebook in Google Colab or Kaggle for the best experience. If you'd like to just view and skim through the notebook, we recommend viewing using nbviewer.
!pip install fastdup -Uq
Now, test the installation by printing out the version. If there's no error message, we are ready to go!
import fastdup
fastdup.__version__
'2.0.21'
Download Dataset¶
For demonstration, we will use a generally curated Oxford IIIT Pet dataset. Feel free to swap this dataset with your own.
The dataset consists of images and annotations for 37 category pets with roughly 200 images for each class.
🗒 Note - fastdup works on both unlabeled and labeled images. But for now, we are only interested in finding issues in the images and not the annotations. If you're interested in finding annotation issues, head to:
Let's download only from the dataset and extract them into the local directory:
!wget https://thor.robots.ox.ac.uk/~vgg/data/pets/images.tar.gz -O images.tar.gz
!tar xf images.tar.gz
Run fastdup¶
Once the extraction completes, we can run fastdup on the images.
For that let's initialize fastdup and specify the input directory which points to the folder of images.
fd = fastdup.create(input_dir="images/")
Warning: fastdup create() without work_dir argument, output is stored in a folder named work_dir in your current working path.
fastdup By Visual Layer, Inc. 2024. All rights reserved. A fastdup dataset object was created! Input directory is set to "images" Work directory is set to "work_dir" The next steps are: 1. Analyze your dataset with the .run() function of the dataset object 2. Interactively explore your data on your local machine with the .explore() function of the dataset object For more information, use help(fastdup) or check our documentation https://docs.visual-layer.com/docs/getting-started-with-fastdup.
🗒 Note - The
.createmethod also has an optionalwork_dirparameter which specifies the directory to store artifacts from the run.
In other words you can run fastdup.create(input_dir="images/", work_dir="my_work_dir/") if you'd like to store the artifacts in a my_work_dir.
Now, let's run fastdup.
fd.run()
View Run Summary¶
After the run is completed, you can optionally view the summary with:
fd.summary()
########################################################################################
Dataset Analysis Summary:
Dataset contains 7390 images
Valid images are 99.92% (7,384) of the data, invalid are 0.08% (6) of the data
For a detailed analysis, use `.invalid_instances()`.
Components: failed to find images clustered into components, try to run with lower cc_threshold.
Outliers: 6.14% (454) of images are possible outliers, and fall in the bottom 5.00% of similarity values.
For a detailed list of outliers, use `.outliers()`.
['Dataset contains 7390 images', 'Valid images are 99.92% (7,384) of the data, invalid are 0.08% (6) of the data', 'For a detailed analysis, use `.invalid_instances()`.\n', 'Components: failed to find images clustered into components, try to run with lower cc_threshold.', 'Outliers: 6.14% (454) of images are possible outliers, and fall in the bottom 5.00% of similarity values.', 'For a detailed list of outliers, use `.outliers()`.\n']
Removing Duplicates¶
Let's first get the information about which cluster each image belongs to.
connected_components_df , _ = fd.connected_components()
connected_components_df
| index | component_id | count | mean_distance | min_distance | max_distance | filename | error_code | is_valid | fd_index | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 21 | 21 | 4 | 0.968095 | 0.968095 | 0.968095 | images/Abyssinian_11.jpg | VALID | True | 21 |
| 1 | 80 | 21 | 4 | 0.968095 | 0.968095 | 0.968095 | images/Abyssinian_177.jpg | VALID | True | 80 |
| 2 | 162 | 161 | 4 | 0.977554 | 0.977554 | 0.977554 | images/Abyssinian_66.jpg | VALID | True | 162 |
| 3 | 180 | 161 | 4 | 0.977554 | 0.977554 | 0.977554 | images/Abyssinian_82.jpg | VALID | True | 180 |
| 4 | 1307 | 1305 | 4 | 0.994964 | 0.994964 | 0.994964 | images/Birman_199.jpg | VALID | True | 1307 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 143 | 6493 | 6414 | 4 | 0.999907 | 0.999907 | 0.999907 | images/Siamese_203.jpg | VALID | True | 6493 |
| 144 | 7272 | 7199 | 4 | 0.960815 | 0.960815 | 0.960815 | images/yorkshire_terrier_175.jpg | VALID | True | 7272 |
| 145 | 7274 | 7201 | 4 | 0.962909 | 0.962909 | 0.962909 | images/yorkshire_terrier_177.jpg | VALID | True | 7274 |
| 146 | 7278 | 7201 | 4 | 0.962909 | 0.962909 | 0.962909 | images/yorkshire_terrier_180.jpg | VALID | True | 7278 |
| 147 | 7280 | 7199 | 4 | 0.960815 | 0.960815 | 0.960815 | images/yorkshire_terrier_182.jpg | VALID | True | 7280 |
148 rows × 10 columns
Duplicates are stored in a cluster (component_id). Let's group the images based on the component_id.
duplicates_df = (
connected_components_df
.groupby('component_id')
.agg(
filenames=('filename', list),
count=('filename', 'size'),
mean_distance=('mean_distance', 'mean')
)
.sort_values('mean_distance', ascending=False)
)
duplicates_df
| filenames | count | mean_distance | |
|---|---|---|---|
| component_id | |||
| 2420 | [images/english_cocker_spaniel_152.jpg, images/english_cocker_spaniel_163.jpg] | 2 | 1.000000 |
| 1484 | [images/Bombay_194.jpg, images/Bombay_32.jpg] | 2 | 1.000000 |
| 1487 | [images/Bombay_200.jpg, images/Bombay_85.jpg] | 2 | 1.000000 |
| 1488 | [images/Bombay_201.jpg, images/Bombay_92.jpg] | 2 | 1.000000 |
| 1489 | [images/Bombay_202.jpg, images/Bombay_99.jpg] | 2 | 1.000000 |
| ... | ... | ... | ... |
| 1459 | [images/Bombay_166.jpg, images/Bombay_177.jpg] | 2 | 0.962989 |
| 7201 | [images/yorkshire_terrier_177.jpg, images/yorkshire_terrier_180.jpg] | 2 | 0.962909 |
| 7199 | [images/yorkshire_terrier_175.jpg, images/yorkshire_terrier_182.jpg] | 2 | 0.960815 |
| 2959 | [images/great_pyrenees_103.jpg, images/great_pyrenees_99.jpg] | 2 | 0.960410 |
| 5266 | [images/Ragdoll_33.jpg, images/Ragdoll_34.jpg] | 2 | 0.960083 |
73 rows × 3 columns
Above, we see that there are 73 clusters. Each cluster represents a set of images that are duplicates or near-duplicates of each other.
Now, let's simplify the above dataframe by keeping only the first image from each cluster and treat the rest as duplicates.
import pandas as pd
def extract_image_duplicates(row):
filenames = row['filenames']
image = filenames[0]
duplicates = filenames[1:] if len(filenames) > 1 else []
return pd.Series({'image': image, 'duplicates': duplicates})
df = duplicates_df.apply(extract_image_duplicates, axis=1)
df
| image | duplicates | |
|---|---|---|
| component_id | ||
| 2420 | images/english_cocker_spaniel_152.jpg | [images/english_cocker_spaniel_163.jpg] |
| 1484 | images/Bombay_194.jpg | [images/Bombay_32.jpg] |
| 1487 | images/Bombay_200.jpg | [images/Bombay_85.jpg] |
| 1488 | images/Bombay_201.jpg | [images/Bombay_92.jpg] |
| 1489 | images/Bombay_202.jpg | [images/Bombay_99.jpg] |
| ... | ... | ... |
| 1459 | images/Bombay_166.jpg | [images/Bombay_177.jpg] |
| 7201 | images/yorkshire_terrier_177.jpg | [images/yorkshire_terrier_180.jpg] |
| 7199 | images/yorkshire_terrier_175.jpg | [images/yorkshire_terrier_182.jpg] |
| 2959 | images/great_pyrenees_103.jpg | [images/great_pyrenees_99.jpg] |
| 5266 | images/Ragdoll_33.jpg | [images/Ragdoll_34.jpg] |
73 rows × 2 columns
Visualizing Duplicates¶
The following steps are optional and are used to visualize the duplicates in the dataset to get a better understanding of the duplicates.
import base64
from io import BytesIO
from PIL import Image
def resize_and_encode_image(image_path, width=100):
with Image.open(image_path) as img:
wpercent = (width / float(img.size[0]))
height = int((float(img.size[1]) * float(wpercent)))
resized_img = img.resize((width, height))
buffered = BytesIO()
resized_img.save(buffered, format="PNG")
encoded_string = base64.b64encode(buffered.getvalue()).decode('utf-8')
return f'<img src="data:image/png;base64,{encoded_string}" width="{width}">'
def display_image_list(image_list, width=100):
if isinstance(image_list, list):
return ''.join([resize_and_encode_image(image, width) for image in image_list])
else:
return ''
# Apply the resize_and_encode_image function to the 'image' column
df['image_preview'] = df['image'].apply(lambda x: resize_and_encode_image(x, width=100))
# Apply the display_image_list function to the 'duplicates' column
df['duplicates_preview'] = df['duplicates'].apply(lambda x: display_image_list(x, width=100))
display(df.style)
| image | duplicates | image_preview | duplicates_preview | |
|---|---|---|---|---|
| component_id | ||||
| 2420 | images/english_cocker_spaniel_152.jpg | ['images/english_cocker_spaniel_163.jpg'] |  |
|
| 1484 | images/Bombay_194.jpg | ['images/Bombay_32.jpg'] |  |
|
| 1487 | images/Bombay_200.jpg | ['images/Bombay_85.jpg'] |  |
|
| 1488 | images/Bombay_201.jpg | ['images/Bombay_92.jpg'] |  |
|
| 1489 | images/Bombay_202.jpg | ['images/Bombay_99.jpg'] |  |
|
| 1587 | images/boxer_114.jpg | ['images/boxer_82.jpg'] |  |
|
| 2179 | images/Egyptian_Mau_10.jpg | ['images/Egyptian_Mau_183.jpg'] |  |
|
| 2203 | images/Egyptian_Mau_131.jpg | ['images/Egyptian_Mau_202.jpg'] |  |
|
| 2288 | images/Egyptian_Mau_224.jpg | ['images/Egyptian_Mau_71.jpg'] |  |
|
| 2419 | images/english_cocker_spaniel_151.jpg | ['images/english_cocker_spaniel_162.jpg'] |  |
|
| 2422 | images/english_cocker_spaniel_154.jpg | ['images/english_cocker_spaniel_164.jpg'] |  |
|
| 2443 | images/english_cocker_spaniel_176.jpg | ['images/english_cocker_spaniel_179.jpg'] |  |
|
| 3691 | images/keeshond_54.jpg | ['images/keeshond_59.jpg'] |  |
|
| 4377 | images/newfoundland_137.jpg | ['images/newfoundland_153.jpg'] |  |
|
| 4378 | images/newfoundland_138.jpg | ['images/newfoundland_154.jpg'] |  |
|
| 4379 | images/newfoundland_139.jpg | ['images/newfoundland_155.jpg'] |  |
|
| 4388 | images/newfoundland_147.jpg | ['images/newfoundland_152.jpg'] |  |
|
| 1485 | images/Bombay_198.jpg | ['images/Bombay_69.jpg'] |  |
|
| 2277 | images/Egyptian_Mau_210.jpg | ['images/Egyptian_Mau_41.jpg'] |  |
|
| 1483 | images/Bombay_193.jpg | ['images/Bombay_22.jpg'] |  |
|
| 1429 | images/Bombay_131.jpg | ['images/Bombay_217.jpg'] |  |
|
| 1397 | images/Bombay_100.jpg | ['images/Bombay_11.jpg', 'images/Bombay_192.jpg'] |  |
|
| 1458 | images/Bombay_164.jpg | ['images/Bombay_189.jpg'] |  |
|
| 1399 | images/Bombay_102.jpg | ['images/Bombay_203.jpg'] |  |
|
| 1478 | images/Bombay_185.jpg | ['images/Bombay_190.jpg'] |  |
|
| 1406 | images/Bombay_109.jpg | ['images/Bombay_206.jpg'] |  |
|
| 1416 | images/Bombay_118.jpg | ['images/Bombay_209.jpg'] |  |
|
| 1419 | images/Bombay_121.jpg | ['images/Bombay_210.jpg'] |  |
|
| 1423 | images/Bombay_126.jpg | ['images/Bombay_220.jpg'] |  |
|
| 3550 | images/keeshond_103.jpg | ['images/keeshond_167.jpg'] |  |
 |
| 3626 | images/keeshond_175.jpg | ['images/keeshond_27.jpg'] |  |
 |
| 3548 | images/keeshond_101.jpg | ['images/keeshond_162.jpg'] |  |
 |
| 3592 | images/keeshond_141.jpg | ['images/keeshond_47.jpg'] |  |
 |
| 3394 | images/japanese_chin_137.jpg | ['images/japanese_chin_85.jpg'] |  |
 |
| 2814 | images/german_shorthaired_150.jpg | ['images/german_shorthaired_3.jpg'] |  |
 |
| 3604 | images/keeshond_152.jpg | ['images/keeshond_99.jpg'] |  |
 |
| 3398 | images/japanese_chin_140.jpg | ['images/japanese_chin_88.jpg'] |  |
 |
| 2845 | images/german_shorthaired_179.jpg | ['images/german_shorthaired_19.jpg'] |  |
 |
| 3450 | images/japanese_chin_188.jpg | ['images/japanese_chin_78.jpg'] |  |
 |
| 3449 | images/japanese_chin_187.jpg | ['images/japanese_chin_200.jpg'] |  |
 |
| 3417 | images/japanese_chin_158.jpg | ['images/japanese_chin_81.jpg'] |  |
 |
| 3834 | images/leonberger_187.jpg | ['images/leonberger_1.jpg'] |  |
 |
| 2847 | images/german_shorthaired_180.jpg | ['images/german_shorthaired_20.jpg'] |  |
 |
| 3437 | images/japanese_chin_176.jpg | ['images/japanese_chin_20.jpg'] |  |
 |
| 4390 | images/newfoundland_149.jpg | ['images/newfoundland_2.jpg'] |  |
 |
| 3036 | images/great_pyrenees_173.jpg | ['images/great_pyrenees_89.jpg'] |  |
 |
| 6414 | images/Siamese_196.jpg | ['images/Siamese_203.jpg'] |  |
 |
| 3457 | images/japanese_chin_194.jpg | ['images/japanese_chin_79.jpg'] |  |
 |
| 3551 | images/keeshond_104.jpg | ['images/keeshond_170.jpg'] |  |
 |
| 3591 | images/keeshond_140.jpg | ['images/keeshond_97.jpg'] |  |
 |
| 3836 | images/leonberger_189.jpg | ['images/leonberger_2.jpg'] |  |
 |
| 2208 | images/Egyptian_Mau_138.jpg | ['images/Egyptian_Mau_219.jpg'] |  |
 |
| 1824 | images/British_Shorthair_160.jpg | ['images/British_Shorthair_278.jpg'] |  |
 |
| 1433 | images/Bombay_136.jpg | ['images/Bombay_150.jpg'] |  |
 |
| 1553 | images/Bombay_79.jpg | ['images/Bombay_97.jpg'] |  |
 |
| 1305 | images/Birman_199.jpg | ['images/Birman_25.jpg'] |  |
 |
| 1512 | images/Bombay_38.jpg | ['images/Bombay_57.jpg'] |  |
 |
| 6103 | images/scottish_terrier_78.jpg | ['images/scottish_terrier_94.jpg'] |  |
 |
| 1851 | images/British_Shorthair_186.jpg | ['images/British_Shorthair_271.jpg'] |  |
 |
| 2255 | images/Egyptian_Mau_186.jpg | ['images/Egyptian_Mau_6.jpg'] |  |
 |
| 1442 | images/Bombay_146.jpg | ['images/Bombay_82.jpg'] |  |
 |
| 1411 | images/Bombay_113.jpg | ['images/Bombay_157.jpg'] |  |
 |
| 161 | images/Abyssinian_66.jpg | ['images/Abyssinian_82.jpg'] |  |
 |
| 1404 | images/Bombay_107.jpg | ['images/Bombay_132.jpg', 'images/Bombay_19.jpg'] |  |
  |
| 1412 | images/Bombay_114.jpg | ['images/Bombay_139.jpg'] |  |
 |
| 5188 | images/Ragdoll_160.jpg | ['images/Ragdoll_161.jpg'] |  |
 |
| 21 | images/Abyssinian_11.jpg | ['images/Abyssinian_177.jpg'] |  |
 |
| 5592 | images/saint_bernard_157.jpg | ['images/saint_bernard_158.jpg'] |  |
 |
| 1459 | images/Bombay_166.jpg | ['images/Bombay_177.jpg'] |  |
 |
| 7201 | images/yorkshire_terrier_177.jpg | ['images/yorkshire_terrier_180.jpg'] |  |
 |
| 7199 | images/yorkshire_terrier_175.jpg | ['images/yorkshire_terrier_182.jpg'] |  |
 |
| 2959 | images/great_pyrenees_103.jpg | ['images/great_pyrenees_99.jpg'] |  |
 |
| 5266 | images/Ragdoll_33.jpg | ['images/Ragdoll_34.jpg'] |  |
 |
Get Duplicates List¶
duplicates_to_remove = df['duplicates'].tolist()
duplicates_to_remove
[['images/english_cocker_spaniel_163.jpg'], ['images/Bombay_32.jpg'], ['images/Bombay_85.jpg'], ['images/Bombay_92.jpg'], ['images/Bombay_99.jpg'], ['images/boxer_82.jpg'], ['images/Egyptian_Mau_183.jpg'], ['images/Egyptian_Mau_202.jpg'], ['images/Egyptian_Mau_71.jpg'], ['images/english_cocker_spaniel_162.jpg'], ['images/english_cocker_spaniel_164.jpg'], ['images/english_cocker_spaniel_179.jpg'], ['images/keeshond_59.jpg'], ['images/newfoundland_153.jpg'], ['images/newfoundland_154.jpg'], ['images/newfoundland_155.jpg'], ['images/newfoundland_152.jpg'], ['images/Bombay_69.jpg'], ['images/Egyptian_Mau_41.jpg'], ['images/Bombay_22.jpg'], ['images/Bombay_217.jpg'], ['images/Bombay_11.jpg', 'images/Bombay_192.jpg'], ['images/Bombay_189.jpg'], ['images/Bombay_203.jpg'], ['images/Bombay_190.jpg'], ['images/Bombay_206.jpg'], ['images/Bombay_209.jpg'], ['images/Bombay_210.jpg'], ['images/Bombay_220.jpg'], ['images/keeshond_167.jpg'], ['images/keeshond_27.jpg'], ['images/keeshond_162.jpg'], ['images/keeshond_47.jpg'], ['images/japanese_chin_85.jpg'], ['images/german_shorthaired_3.jpg'], ['images/keeshond_99.jpg'], ['images/japanese_chin_88.jpg'], ['images/german_shorthaired_19.jpg'], ['images/japanese_chin_78.jpg'], ['images/japanese_chin_200.jpg'], ['images/japanese_chin_81.jpg'], ['images/leonberger_1.jpg'], ['images/german_shorthaired_20.jpg'], ['images/japanese_chin_20.jpg'], ['images/newfoundland_2.jpg'], ['images/great_pyrenees_89.jpg'], ['images/Siamese_203.jpg'], ['images/japanese_chin_79.jpg'], ['images/keeshond_170.jpg'], ['images/keeshond_97.jpg'], ['images/leonberger_2.jpg'], ['images/Egyptian_Mau_219.jpg'], ['images/British_Shorthair_278.jpg'], ['images/Bombay_150.jpg'], ['images/Bombay_97.jpg'], ['images/Birman_25.jpg'], ['images/Bombay_57.jpg'], ['images/scottish_terrier_94.jpg'], ['images/British_Shorthair_271.jpg'], ['images/Egyptian_Mau_6.jpg'], ['images/Bombay_82.jpg'], ['images/Bombay_157.jpg'], ['images/Abyssinian_82.jpg'], ['images/Bombay_132.jpg', 'images/Bombay_19.jpg'], ['images/Bombay_139.jpg'], ['images/Ragdoll_161.jpg'], ['images/Abyssinian_177.jpg'], ['images/saint_bernard_158.jpg'], ['images/Bombay_177.jpg'], ['images/yorkshire_terrier_180.jpg'], ['images/yorkshire_terrier_182.jpg'], ['images/great_pyrenees_99.jpg'], ['images/Ragdoll_34.jpg']]
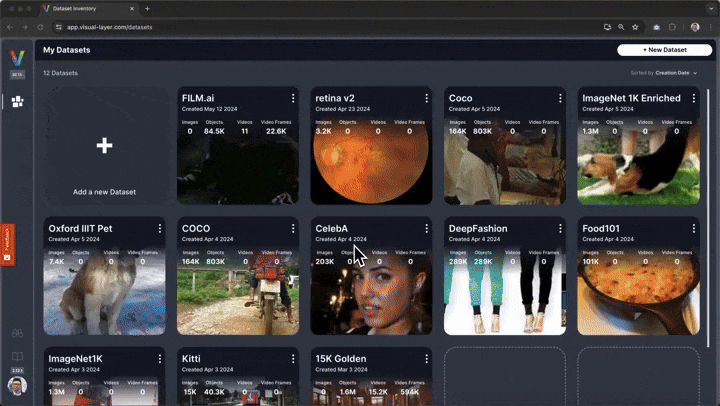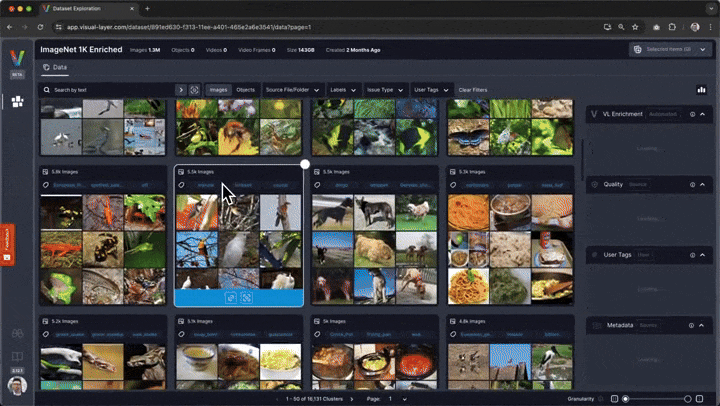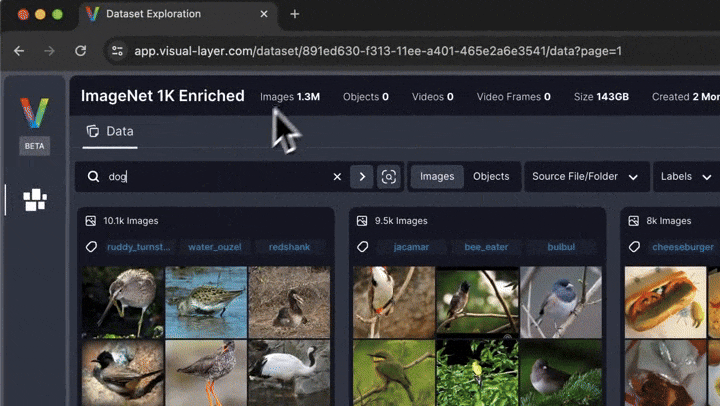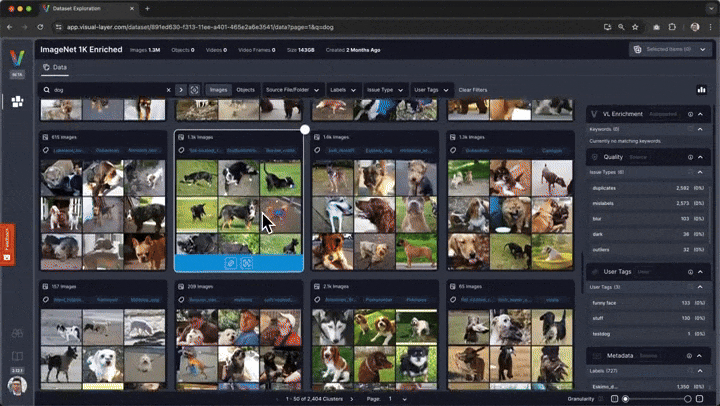
Interactive Exploration¶
In addition to the static visualizations presented above, fastdup also offers interactive exploration of the dataset.
To explore the dataset and issues interactively in a browser, run:
fd.explore()
🗒 Note - This currently requires you to sign-up (for free) to view the interactive exploration. Alternatively, you can visualize fastdup in a non-interactive way using fastdup's built in galleries shown in the upcoming cells.
You'll be presented with a web interface that lets you conveniently view, filter, and curate your dataset in a web interface.
Wrap Up¶
That's a wrap! In this notebook we showed how you can run fastdup on a dataset or any folder of images.
We've seen how to use fastdup to find:
- Broken images.
- Duplicate/near-duplicates.
- Outliers.
- Dark, bright and blurry images.
- Image clusters.
Next, feel free to check out other tutorials -
- ⚡ Quickstart: Learn how to install fastdup, load a dataset and analyze it for potential issues such as duplicates/near-duplicates, broken images, outliers, dark/bright/blurry images, and view visually similar image clusters. If you're new, start here!
- 🧹 Clean Image Folder: Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
- 🖼 Analyze Image Classification Dataset: Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
- 🎁 Analyze Object Detection Dataset: Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
As usual, feedback is welcome! Questions? Drop by our Slack channel or open an issue on GitHub.






