MM Algorithm (KL Chapter 12)¶

MM algorithm¶
- Recall our picture for understanding the ascent property of EM
- EM as a minorization-maximization (MM) algorithm
- The $Q$ function constitutes a minorizing function of the objective function up to an additive constant
* **Maximizing** the $Q$ function generates an ascent iterate $\theta^{(t+1)}$
Questions:
- Is EM principle only limited to maximizing likelihood model?
- Can we flip the picture and apply same principle to minimization problem?
- Is there any other way to produce such surrogate function?
These thoughts lead to a powerful tool - MM algorithm.
Lange, K., Hunter, D. R., and Yang, I. (2000). Optimization transfer using surrogate objective functions. J. Comput. Graph. Statist., 9(1):1-59. With discussion, and a rejoinder by Hunter and Lange.
- For maximization of $f(\theta)$ - minorization-maximization (MM) algorithm
- Minorization step: Construct a surrogate function $g(\theta|\theta^{(t)})$ that satisfies
* **M**aximization step:
- Ascent property of minorization-maximization algorithm
EM is a special case of minorization-maximization (MM) algorithm.
For minimization of $f(\theta)$ - majorization-minimization (MM) algorithm
- Majorization step: Construct a surrogate function $g(\theta|\theta^{(t)})$ that satisfies
* **M**inimization step:

Similarly we have the descent property of majorization-minimization algorithm.
Same convergence theory as EM.
Rational of the MM principle for developing optimization algorithms
- Free the derivation from missing data structure.
- Avoid matrix inversion.
- Linearize an optimization problem.
- Deal gracefully with certain equality and inequality constraints.
- Turn a non-differentiable problem into a smooth problem.
- Separate the parameters of a problem (perfect for massive, fine-scale parallelization).
Generic methods for majorization and minorization - inequalities
- Jensen's (information) inequality - EM algorithms
- Supporting hyperplane property of a convex function
- The Cauchy-Schwartz inequality - multidimensional scaling
- Arithmetic-geometric mean inequality
- Quadratic upper bound principle - Bohning and Lindsay
- ...
Numerous examples in KL chapter 12, or take Kenneth Lange's optimization course BIOMATH 210.
History: the name MM algorithm originates from the discussion (by Xiaoli Meng) and rejoinder of the Lange, Hunter, Yang (2000) paper.
MM example: t-distribution revisited¶
- Recall that given iid data $\mathbf{w}_1, \ldots, \mathbf{w}_n$ from multivariate $t$-distribution $t_p(\mu,\Sigma,\nu)$, the log-likelihood is
Early on we discussed EM algorithm and its variants for maximizing the log-likelihood.
Since $t \mapsto - \log t$ is a convex function, we can invoke the supporting hyperplane inequality to minorize the terms $- \log [\nu + \delta (\mathbf{w}_j,\mu;\Sigma)$:
where $c^{(t)}$ is a constant irrelevant to optimization.
- This yields a minorization function
Now we can deploy the block ascent strategy.
* Fixing $\nu$, update of $\mu$ and $\Sigma$ are same as in EM algorithm.
* Fixing $\mu$ and $\Sigma$, we can update $\nu$ by working on the observed log-likelihood directly.
Overall this MM algorithm coincides with ECME.
- An alternative MM derivation leads to the optimal EM algorithm derived in Meng and van Dyk (1997). See Wu and Lange (2010).
MM example: non-negative matrix factorization (NNMF)¶

Nonnegative matrix factorization (NNMF) was introduced by Lee and Seung (1999, 2001) as an analog of principal components and vector quantization with applications in data compression and clustering.
In mathematical terms, one approximates a data matrix $\mathbf{X} \in \mathbb{R}^{m \times n}$ with nonnegative entries $x_{ij}$ by a product of two low-rank matrices $\mathbf{V} \in \mathbb{R}^{m \times r}$ and $\mathbf{W} \in \mathbb{R}^{r \times n}$ with nonnegative entries $v_{ik}$ and $w_{kj}$.
Consider minimization of the squared Frobenius norm
which should lead to a good factorization.
$L(\mathbf{V}, \mathbf{W})$ is not convex, but bi-convex. The strategy is to alternately update $\mathbf{V}$ and $\mathbf{W}$.
The key is the majorization, via convexity of the function $(x_{ij} - x)^2$,
where $$ a_{ikj}^{(t)} = v_{ik}^{(t)} w_{kj}^{(t)}, \quad b_{ij}^{(t)} = \sum_k v_{ik}^{(t)} w_{kj}^{(t)}. $$
- This suggests the alternating multiplicative updates
- The update in matrix notation is extremely simple
where $\odot$ denotes elementwise multiplication and $\oslash$ denotes elementwise division. If we start with $v_{ik}, w_{kj} > 0$, parameter iterates stay positive.
Monotoniciy of the algorithm is free (from MM principle).
Database #1 from the MIT Center for Biological and Computational Learning (CBCL, http://cbcl.mit.edu) reduces to a matrix X containing $m = 2,429$ gray-scale face images with $n = 19 \times 19 = 361$ pixels per face. Each image (row) is scaled to have mean and standard deviation 0.25.
My implementation in around 2010:
CPU: Intel Core 2 @ 3.2GHZ (4 cores), implemented using BLAS in the GNU Scientific Library (GSL)
GPU: NVIDIA GeForce GTX 280 (240 cores), implemented using cuBLAS.

MM example: Netflix and matrix completion¶
- Snapshot of the kind of data collected by Netflix. Only 100,480,507 ratings (1.2% entries of the 480K-by-18K matrix) are observed
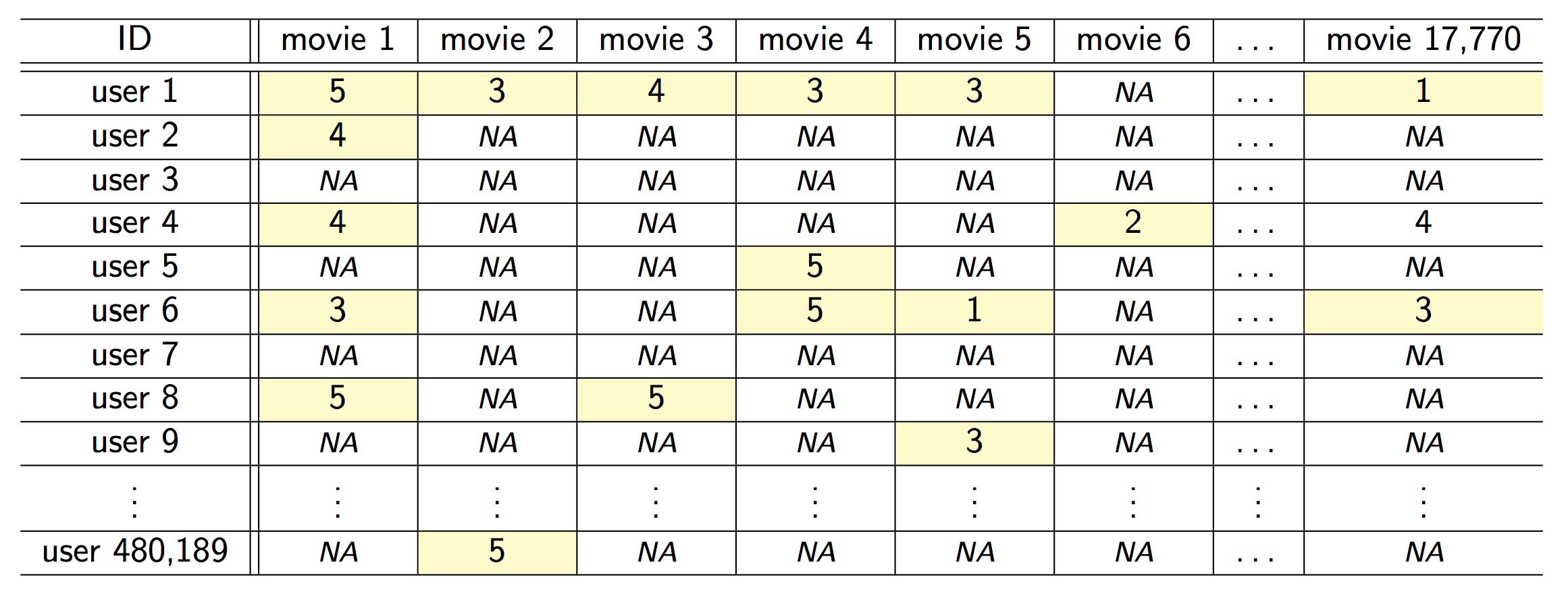
- Netflix challenge: impute the unobserved ratings for personalized recommendation.
http://en.wikipedia.org/wiki/Netflix_Prize

Matrix completion problem. Observe a very sparse matrix $\mathbf{Y} = (y_{ij})$. Want to impute all the missing entries. It is possible only when the matrix is structured, e.g., of low rank.
Let $\Omega = \{(i,j): \text{observed entries}\}$ index the set of observed entries and $P_\Omega(\mathbf{M})$ denote the projection of matrix $\mathbf{M}$ to $\Omega$. The problem
unfortunately is non-convex and difficult.
- Convex relaxation: Mazumder, Hastie, Tibshirani (2010)
where $\|\mathbf{X}\|_* = \|\sigma(\mathbf{X})\|_1 = \sum_i \sigma_i(\mathbf{X})$ is the nuclear norm.
- Majorization step:
where $\mathbf{Z}^{(t)} = P_\Omega(\mathbf{Y}) + P_{\Omega^\perp}(\mathbf{X}^{(t)})$. "fill in missing entries by the current imputation"
- Minimization step: Rewrite the surrogate function
Let $\sigma_i$ be the (ordered) singular values of $\mathbf{X}$ and $\omega_i$ be the (ordered) singular values of $\mathbf{Z}^{(t)}$. Observe $$ \begin{eqnarray*} \|\mathbf{X}\|_{\text{F}}^2 &=& \|\sigma(\mathbf{X})\|_2^2 = \sum_{i} \sigma_i^2 \\ \|\mathbf{Z}^{(t)}\|_{\text{F}}^2 &=& \|\sigma(\mathbf{Z}^{(t)})\|_2^2 = \sum_{i} \omega_i^2 \end{eqnarray*} $$ and by the Fan-von Neuman's inequality $$ \begin{eqnarray*} \text{tr}(\mathbf{X}^T \mathbf{Z}^{(t)}) \le \sum_i \sigma_i \omega_i \end{eqnarray*} $$ with equality achieved if and only if the left and right singular vectors of the two matrices coincide. Thus we should choose $\mathbf{X}$ to have same singular vectors as $\mathbf{Z}^{(t)}$ and $$ \begin{eqnarray*} g(\mathbf{X}|\mathbf{X}^{(t)}) &=& \frac{1}{2} \sum_i \sigma_i^2 - \sum_i \sigma_i \omega_i + \frac{1}{2} \sum_i \omega_i^2 + \lambda \sum_i \sigma_i \\ &=& \frac{1}{2} \sum_i (\sigma_i - \omega_i)^2 + \lambda \sum_i \sigma_i, \end{eqnarray*} $$ with minimizer given by singular value thresholding $$ \sigma_i^{(t+1)} = \max(0, \omega_i - \lambda) = (\omega_i - \lambda)_+. $$
Algorithm for matrix completion:
- Initialize $\mathbf{X}^{(0)} \in \mathbb{R}^{m \times n}$
- Repeat
- $\mathbf{Z}^{(t)} \gets P_\Omega(\mathbf{Y}) + P_{\Omega^\perp}(\mathbf{X}^{(t)})$
- Compute SVD: $\mathbf{U} \text{diag}(\mathbf{w}) \mathbf{V}^T \gets \mathbf{Z}^{(t)}$
- $\mathbf{X}^{(t+1)} \gets \mathbf{U} \text{diag}[(\mathbf{w}-\lambda)_+] \mathbf{V}^T$
- objective value converges
"Golub-Kahan-Reinsch" algorithm takes $4m^2n + 8mn^2 + 9n^3$ flops for an $m \ge n$ matrix and is not going to work for 480K-by-18K Netflix matrix.
Notice only top singular values are needed since low rank solutions are achieved by large $\lambda$. Lanczos/Arnoldi algorithm is the way to go. Matrix-vector multiplication $\mathbf{Z}^{(t)} \mathbf{v}$ is fast (why?)