versioninfo()
Julia Version 1.6.2 Commit 1b93d53fc4 (2021-07-14 15:36 UTC) Platform Info: OS: macOS (x86_64-apple-darwin18.7.0) CPU: Intel(R) Core(TM) i5-8279U CPU @ 2.40GHz WORD_SIZE: 64 LIBM: libopenlibm LLVM: libLLVM-11.0.1 (ORCJIT, skylake)
using Pkg
Pkg.activate("../..")
Pkg.status()
Activating environment at `~/Dropbox/class/M1399.000200/2021/M1399_000200-2021fall/Project.toml`
Status `~/Dropbox/class/M1399.000200/2021/M1399_000200-2021fall/Project.toml` [7d9fca2a] Arpack v0.5.3 [6e4b80f9] BenchmarkTools v1.1.4 [1e616198] COSMO v0.8.1 [f65535da] Convex v0.14.13 [a93c6f00] DataFrames v1.2.2 [31a5f54b] Debugger v0.6.8 [31c24e10] Distributions v0.24.18 [e2685f51] ECOS v0.12.3 [f6369f11] ForwardDiff v0.10.19 [28b8d3ca] GR v0.58.1 [c91e804a] Gadfly v1.3.3 [bd48cda9] GraphRecipes v0.5.7 [82e4d734] ImageIO v0.5.8 [6218d12a] ImageMagick v1.2.1 [916415d5] Images v0.24.1 [b6b21f68] Ipopt v0.7.0 [42fd0dbc] IterativeSolvers v0.9.1 [4076af6c] JuMP v0.21.9 [b51810bb] MatrixDepot v1.0.4 [1ec41992] MosekTools v0.9.4 [76087f3c] NLopt v0.6.3 [47be7bcc] ORCA v0.5.0 [a03496cd] PlotlyBase v0.4.3 [f0f68f2c] PlotlyJS v0.15.0 [91a5bcdd] Plots v1.21.2 [438e738f] PyCall v1.92.3 [d330b81b] PyPlot v2.9.0 [dca85d43] QuartzImageIO v0.7.3 [6f49c342] RCall v0.13.12 [ce6b1742] RDatasets v0.7.5 [c946c3f1] SCS v0.7.1 [276daf66] SpecialFunctions v1.6.1 [2913bbd2] StatsBase v0.33.10 [b8865327] UnicodePlots v2.0.1 [0f1e0344] WebIO v0.8.15 [8f399da3] Libdl [2f01184e] SparseArrays [10745b16] Statistics
Numerical linear algebra: introduction¶
Topics in numerical linear algebra:
- BLAS
- solve linear equations $\mathbf{A} \mathbf{x} = \mathbf{b}$
- regression computations $\mathbf{X}^T \mathbf{X} \beta = \mathbf{X}^T \mathbf{y}$
- eigen-problems $\mathbf{A} \mathbf{x} = \lambda \mathbf{x}$
- generalized eigen-problems $\mathbf{A} \mathbf{x} = \lambda \mathbf{B} \mathbf{x}$
- singular value decompositions $\mathbf{A} = \mathbf{U} \Sigma \mathbf{V}^T$
- iterative methods for numerical linear algebra
Except for the iterative methods, most of these numerical linear algebra tasks are implemented in the BLAS and LAPACK libraries. They form the building blocks of most statistical computing tasks (optimization, MCMC).
Our major goal (or learning objectives) is to
- know the complexity (flop count) of each task
- be familiar with the BLAS and LAPACK functions (what they do)
- do not re-invent the wheel by implementing these dense linear algebra subroutines by yourself
- understand the need for iterative methods
- apply appropriate numerical algebra tools to various statistical problems
All high-level languages (R, Matlab, Julia) call BLAS and LAPACK for numerical linear algebra.
- Julia offers more flexibility by exposing interfaces to many BLAS/LAPACK subroutines directly. See documentation.
BLAS¶
BLAS stands for basic linear algebra subprograms.
See netlib for a complete list of standardized BLAS functions.
There are many implementations of BLAS.
- Netlib provides a reference implementation.
- Matlab uses Intel's Math Kernel Library (MKL). MKL implementation is the gold standard on market. It is not open source but the compiled library is free for Linux and MacOS.
- Julia uses OpenBLAS. OpenBLAS is a fast, actively maintained fork of GotoBLAS, which has an interesting history.
- Julia can be compiled to use the MKL from the source.
There are 3 levels of BLAS functions.
| Level | Example Operation | Name | Dimension | Flops |
|---|---|---|---|---|
| 1 | $\alpha \gets \mathbf{x}^T \mathbf{y}$ | dot product | $\mathbf{x}, \mathbf{y} \in \mathbb{R}^n$ | $2n$ |
| 1 | $\mathbf{y} \gets \mathbf{y} + \alpha \mathbf{x}$ | axpy | $\alpha \in \mathbb{R}$, $\mathbf{x}, \mathbf{y} \in \mathbb{R}^n$ | $2n$ |
| 2 | $\mathbf{y} \gets \mathbf{y} + \mathbf{A} \mathbf{x}$ | gaxpy | $\mathbf{A} \in \mathbb{R}^{m \times n}$, $\mathbf{x} \in \mathbb{R}^n$, $\mathbf{y} \in \mathbb{R}^m$ | $2mn$ |
| 2 | $\mathbf{A} \gets \mathbf{A} + \mathbf{y} \mathbf{x}^T$ | rank one update | $\mathbf{A} \in \mathbb{R}^{m \times n}$, $\mathbf{x} \in \mathbb{R}^n$, $\mathbf{y} \in \mathbb{R}^m$ | $2mn$ |
| 3 | $\mathbf{C} \gets \mathbf{C} + \mathbf{A} \mathbf{B}$ | matrix multiplication | $\mathbf{A} \in \mathbb{R}^{m \times p}$, $\mathbf{B} \in \mathbb{R}^{p \times n}$, $\mathbf{C} \in \mathbb{R}^{m \times n}$ | $2mnp$ |
- Typical BLAS functions support single precision (S), double precision (D), complex (C), and double complex (Z).
Examples¶
The form of a mathematical expression and the way the expression should be evaluated in actual practice may be quite different.
-- James Gentle, Matrix Algebra, Springer, New York (2007).
Some operations appear as level-3 but indeed are level-2.
Example 1¶
A common operation in statistics is column scaling or row scaling
$$
\begin{eqnarray*}
\mathbf{A} &=& \mathbf{A} \mathbf{D} \quad \text{(column scaling)} \\
\mathbf{A} &=& \mathbf{D} \mathbf{A} \quad \text{(row scaling)},
\end{eqnarray*}
$$
where $\mathbf{D}$ is diagonal. For example, in generalized linear models (GLMs), the Fisher information matrix takes the form
$$
\mathbf{X}^T \mathbf{W} \mathbf{X},
$$
where $\mathbf{W}$ is a diagonal matrix with observation weights on diagonal.
Column and row scalings are essentially level-2 operations!
using BenchmarkTools, LinearAlgebra, Random
Random.seed!(123) # seed
n = 2000
A = rand(n, n) # n-by-n matrix
d = rand(n) # n vector
D = Diagonal(d) # diagonal matrix with d as diagonal
2000×2000 Diagonal{Float64, Vector{Float64}}:
0.140972 ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅
⋅ 0.143596 ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ 0.612494 ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ 0.0480573 ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋮ ⋱
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ 0.882415 ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ 0.450904 ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 0.814614
Dfull = convert(Matrix, D) # convert to full matrix
2000×2000 Matrix{Float64}:
0.140972 0.0 0.0 0.0 … 0.0 0.0 0.0
0.0 0.143596 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.612494 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0480573 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 … 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 … 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
⋮ ⋱
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 … 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 … 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.882415 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.450904 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.814614
# this is calling BLAS routine for matrix multiplication: O(n^3) flops
# this is SLOW!
@benchmark $A * $Dfull
BenchmarkTools.Trial: 39 samples with 1 evaluation. Range (min … max): 99.756 ms … 183.883 ms ┊ GC (min … max): 0.00% … 4.41% Time (median): 121.387 ms ┊ GC (median): 0.00% Time (mean ± σ): 131.600 ms ± 25.298 ms ┊ GC (mean ± σ): 1.90% ± 2.80% ▁ ▁▁▄ ▁ ▁ ▁ █ ▆▆█▆▆███▁▆█▁▁▆█▆▁▁▁▆▁▁▆▁▁▁▆▆▁▆▁▁▁▁▆█▁▁▁▁▁█▆▁▁▁▆▁▆▆▆▁▁▁▁▁▆▁▁▁▆ ▁ 99.8 ms Histogram: frequency by time 184 ms < Memory estimate: 30.52 MiB, allocs estimate: 2.
# dispatch to special method for diagonal matrix multiplication.
# columnwise scaling: O(n^2) flops
@benchmark $A * $D
BenchmarkTools.Trial: 497 samples with 1 evaluation. Range (min … max): 6.324 ms … 18.680 ms ┊ GC (min … max): 0.00% … 41.11% Time (median): 8.060 ms ┊ GC (median): 0.00% Time (mean ± σ): 10.049 ms ± 3.227 ms ┊ GC (mean ± σ): 20.63% ± 20.55% ▄█▄▂▁ ▄▄▄▃▇█████▅▄▃▃▁▂▃▂▂▃▃▃▃▃▂▃▃▁▁▁▂▁▂▃▃▂▂▂▃███▅▄▃▄▃▃▂▁▂▂▂▂▃▃▃▃▂ ▃ 6.32 ms Histogram: frequency by time 17.2 ms < Memory estimate: 30.52 MiB, allocs estimate: 4.
# in-place: avoid allocating space for result
# rmul!: compute matrix-matrix product AB, overwriting A, and return the result.
@benchmark rmul!(A, D)
BenchmarkTools.Trial: 372 samples with 1 evaluation. Range (min … max): 6.869 ms … 21.703 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 13.772 ms ┊ GC (median): 0.00% Time (mean ± σ): 13.450 ms ± 4.026 ms ┊ GC (mean ± σ): 0.00% ± 0.00% ▁ ▃▂▃▆▅▂ ▅ ▄ ▁▁ ▂▂ ▂▁ ▂▃ ▃█▅▃ ▄▄▃ ▃▅ ▆█▄██████▆█▅█▇▅██▂▆██▇▇██▆▃▄▂▄▆██▇████▆███▅▄▇▆▃▆▃▅▂▅▄██▆▃▆▄ ▄ 6.87 ms Histogram: frequency by time 20.9 ms < Memory estimate: 96 bytes, allocs estimate: 2.
Note: In R, diag(d) will create a full (dense) matrix. Be cautious using diag function: do we really need a full diagonal matrix?
using RCall
R"""
d <- runif(5)
diag(d)
"""
RObject{RealSxp}
[,1] [,2] [,3] [,4] [,5]
[1,] 0.9028847 0.0000000 0.0000000 0.0000000 0.00000000
[2,] 0.0000000 0.2051186 0.0000000 0.0000000 0.00000000
[3,] 0.0000000 0.0000000 0.8915648 0.0000000 0.00000000
[4,] 0.0000000 0.0000000 0.0000000 0.4390209 0.00000000
[5,] 0.0000000 0.0000000 0.0000000 0.0000000 0.05749282
Example 2¶
Inner product between two matrices $\mathbf{A}, \mathbf{B} \in \mathbb{R}^{m \times n}$ is often written as
$$ \langle \mathbf{A}, \mathbf{B} \rangle = \sum_{i,j} \mathbf{A}_{ij}\mathbf{B}_{ij} = \text{trace}(\mathbf{A}^T \mathbf{B}) = \text{trace}(\mathbf{B} \mathbf{A}^T) = \text{trace}(\mathbf{A} \mathbf{B}^T) = \text{trace}(\mathbf{B}^T \mathbf{A}). $$They appear as level-3 operation (matrix multiplication with $O(m^2n)$ or $O(mn^2)$ flops).
Random.seed!(123)
n = 2000
A, B = randn(n, n), randn(n, n)
# slow way to evaluate this thing
@benchmark tr(transpose($A) * $B)
BenchmarkTools.Trial: 32 samples with 1 evaluation. Range (min … max): 104.761 ms … 210.264 ms ┊ GC (min … max): 0.00% … 6.70% Time (median): 174.214 ms ┊ GC (median): 0.00% Time (mean ± σ): 158.338 ms ± 36.217 ms ┊ GC (mean ± σ): 1.80% ± 3.03% ▄ ▁ ▁ █ ▁ ▁▁ █▆▆▁▆▆▁▆█▆▁▁▁▁▁▁▁▁▁▆▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▆▁▁▆█▆█▁▁▆█▁▁▁▁██▆▁▆▁▁▆▁▁▆ ▁ 105 ms Histogram: frequency by time 210 ms < Memory estimate: 30.52 MiB, allocs estimate: 2.
But $\langle \mathbf{A}, \mathbf{B} \rangle = \langle \text{vec}(\mathbf{A}), \text{vec}(\mathbf{B}) \rangle$. The latter is level-2 operation with $O(mn)$ flops.
@benchmark dot($A, $B)
BenchmarkTools.Trial: 3891 samples with 1 evaluation. Range (min … max): 1.213 ms … 3.049 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 1.239 ms ┊ GC (median): 0.00% Time (mean ± σ): 1.271 ms ± 78.007 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▅██▇▆▅▅▄▄▄▄▄▃▃▃▂▂▂▂▁▂▁ ▂ ████████████████████████▆█▇▆▇▆█▇▆▇▆▇▇████████▆██▇▆█▇▇▇▆▆▇▆ █ 1.21 ms Histogram: log(frequency) by time 1.52 ms < Memory estimate: 0 bytes, allocs estimate: 0.
Example 3¶
Similarly $\text{diag}(\mathbf{A}^T \mathbf{B})=\text{diag}(\sum_{j}\mathbf{A}_{ij}\mathbf{B}_{ij})$ can be calculated in $O(mn)$ flops.
# slow way to evaluate this thing
@benchmark diag(transpose($A) * $B)
BenchmarkTools.Trial: 38 samples with 1 evaluation. Range (min … max): 105.100 ms … 205.494 ms ┊ GC (min … max): 0.00% … 6.87% Time (median): 127.099 ms ┊ GC (median): 0.00% Time (mean ± σ): 133.460 ms ± 26.864 ms ┊ GC (mean ± σ): 2.20% ± 3.58% █ █▄▁ ▁ ▄ ▁ ▁ █▆▆▆███▁▆▁▁▁█▆▆█▁▁▁▁▆▆▆▆▁▁▁▁█▁▁▁█▆▁▁▁▁▁▁▆▆▁▁▁▆▁▁▁▁▁▁▁▁▁▁▁▆▁▁▆ ▁ 105 ms Histogram: frequency by time 205 ms < Memory estimate: 30.53 MiB, allocs estimate: 3.
# smarter
@benchmark Diagonal(vec(sum($A .* $B, dims=1)))
BenchmarkTools.Trial: 399 samples with 1 evaluation. Range (min … max): 7.757 ms … 24.467 ms ┊ GC (min … max): 0.00% … 49.34% Time (median): 10.987 ms ┊ GC (median): 0.00% Time (mean ± σ): 12.525 ms ± 4.776 ms ┊ GC (mean ± σ): 19.39% ± 21.20% █▄ ▅██▄▄▄▃▃▃▄▃▄▄▃▃▄▂▄▆▄▄▄▂▃▂▃▂▁▁▁▁▁▁▁▁▂▄▅▄▃▂▂▂▃▁▁▂▃▃▂▃▃▂▁▃▂▃▃▃ ▃ 7.76 ms Histogram: frequency by time 23.7 ms < Memory estimate: 30.53 MiB, allocs estimate: 5.
To get rid of allocation of intermediate array at all, we can just write a double loop or use dot function.
function diag_matmul(A, B)
m, n = size(A)
@assert size(B) == (m, n) "A and B should have same size"
# @views: Convert every array-slicing operation in the given expression to return a view.
# See below for avoiding memory allocation
@views d = [dot(A[:, j], B[:, j]) for j in 1:n]
# d = zeros(eltype(A), n)
# for j in 1:n, i in 1:m
# d[j] += A[i, j] * B[i, j]
# end
Diagonal(d)
end
@benchmark diag_matmul($A, $B)
BenchmarkTools.Trial: 1892 samples with 1 evaluation. Range (min … max): 2.146 ms … 5.498 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 2.453 ms ┊ GC (median): 0.00% Time (mean ± σ): 2.629 ms ± 447.989 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▁▃▃▃▃██▆▅▂▂▂▂▁▂▁▁ ▁ ▆███████████████████▇████▇█▆▇▇▇█▇▆▅▆▅▇▆▆▆▃▄▆▄▅▄▃▅▃▄▆▃▄▃▄▃▃▅ █ 2.15 ms Histogram: log(frequency) by time 4.5 ms < Memory estimate: 15.75 KiB, allocs estimate: 1.
Memory hierarchy and level-3 fraction¶
Key to high performance is effective use of memory hierarchy. True on all architectures.
- Flop count is not the sole determinant of algorithm efficiency. Another important factor is data movement through the memory hierarchy.


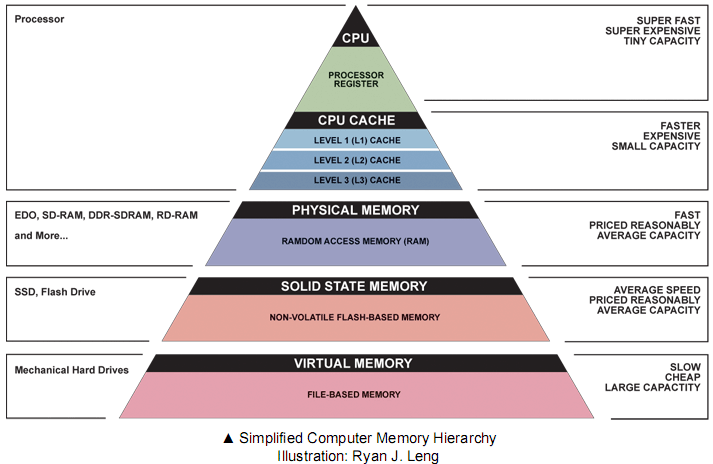
- Numbers everyone should know
| Operation | Time |
|---|---|
| L1 cache reference | 0.5 ns |
| L2 cache reference | 7 ns |
| Main memory reference | 100 ns |
| Read 1 MB sequentially from memory | 250,000 ns |
| Read 1 MB sequentially from SSD | 1,000,000 ns |
| Read 1 MB sequentially from disk | 20,000,000 ns |
Source: https://gist.github.com/jboner/2841832
For example, Xeon X5650 CPU has a theoretical throughput of 128 DP GFLOPS but a max memory bandwidth of 32GB/s.
Can we keep CPU cores busy with enough deliveries of matrix data and ship the results to memory fast enough to avoid backlog?
Answer: use high-level BLAS as much as possible.
| BLAS | Dimension | Mem. Refs. | Flops | Ratio |
|---|---|---|---|---|
| Level 1: $\mathbf{y} \gets \mathbf{y} + \alpha \mathbf{x}$ | $\mathbf{x}, \mathbf{y} \in \mathbb{R}^n$ | $3n$ | $2n$ | 3:2 |
| Level 2: $\mathbf{y} \gets \mathbf{y} + \mathbf{A} \mathbf{x}$ | $\mathbf{x}, \mathbf{y} \in \mathbb{R}^n$, $\mathbf{A} \in \mathbb{R}^{n \times n}$ | $n^2$ | $2n^2$ | 1:2 |
| Level 3: $\mathbf{C} \gets \mathbf{C} + \mathbf{A} \mathbf{B}$ | $\mathbf{A}, \mathbf{B}, \mathbf{C} \in\mathbb{R}^{n \times n}$ | $4n^2$ | $2n^3$ | 2:n |
- Higher level BLAS (3 or 2) make more effective use of arithmetic logic units (ALU) by keeping them busy.
See Dongarra slides.

A distinction between LAPACK and LINPACK (older version of R uses LINPACK) is that LAPACK makes use of higher level BLAS as much as possible (usually by smart partitioning) to increase the so-called level-3 fraction.
To appreciate the efforts in an optimized BLAS implementation such as OpenBLAS (evolved from GotoBLAS), see this video. The bottom line is
Get familiar with (good implementations of) BLAS/LAPACK and use them as much as possible.
Effect of data layout¶
Data layout in memory affects algorithmic efficiency too. It is much faster to move chunks of data in memory than retrieving/writing scattered data.
Storage mode: column-major (Fortran, Matlab, R, Julia) vs row-major (C/C++).
Cache line is the minimum amount of cache which can be loaded and stored to memory.
- x86 CPUs: 64 bytes
- ARM CPUs: 32 bytes
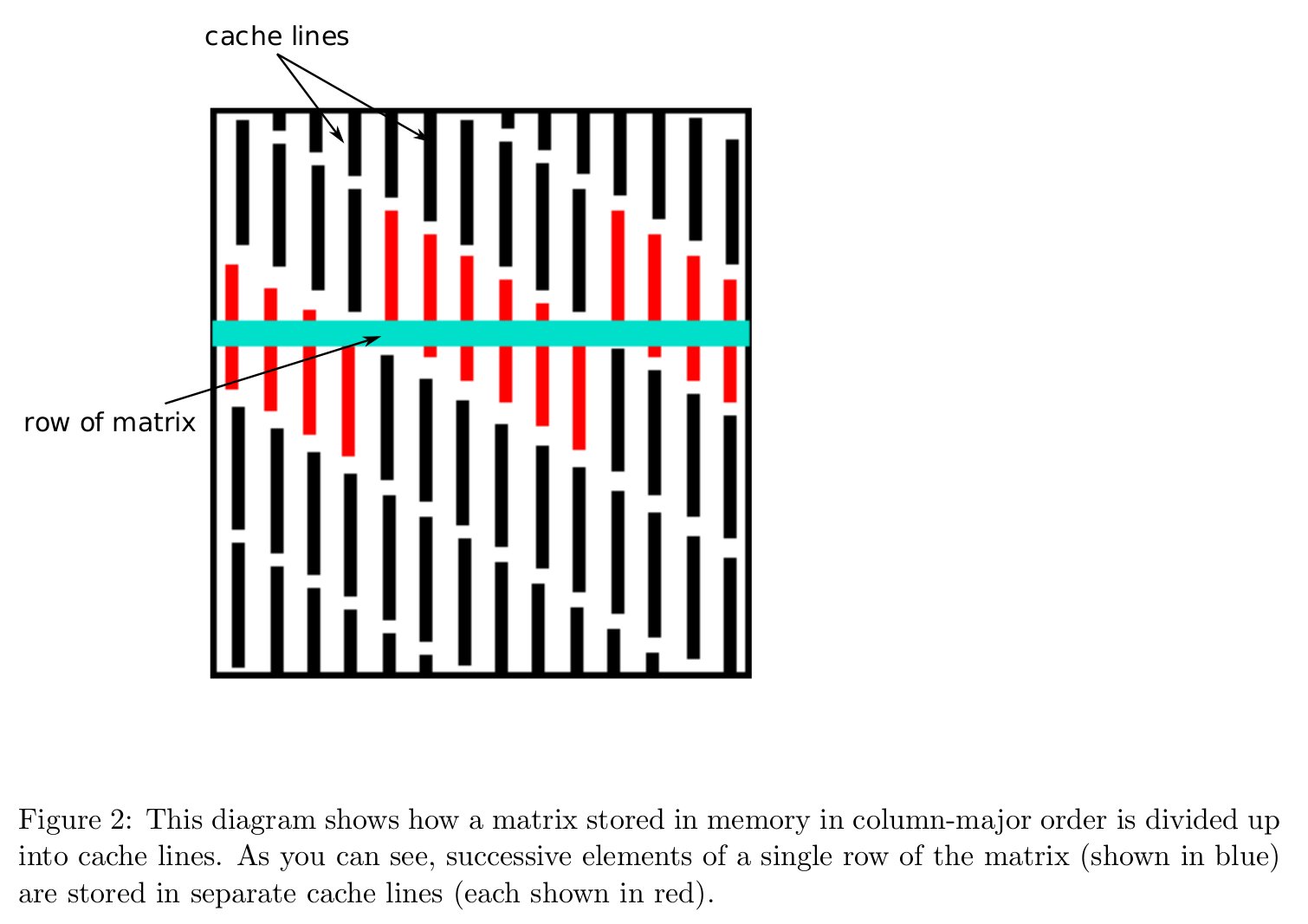
Source: https://patterns.eecs.berkeley.edu/?page_id=158
Accessing column-major stored matrix by rows ($ij$ looping) causes lots of cache misses.
Take matrix multiplication as an example
Assume the storage is column-major, such as in Julia. There are 6 variants of the algorithms according to the order in the triple loops.
- jki or kji looping:
julia # inner most loop for i = 1:m C[i, j] = C[i, j] + A[i, k] * B[k, j] end
- ikj or kij looping:
julia # inner most loop for j = 1:n C[i, j] = C[i, j] + A[i, k] * B[k, j] end
- ijk or jik looping:
julia # inner most loop for k = 1:p C[i, j] = C[i, j] + A[i, k] * B[k, j] end
- We pay attention to the innermost loop, where the vector calculation occurs. The associated stride when accessing the three matrices in memory (assuming column-major storage) is
| Variant | A Stride | B Stride | C Stride |
|---|---|---|---|
jki or kji |
Unit | 0 | Unit |
ikj or kij |
0 | Non-Unit | Non-Unit |
ijk or jik |
Non-Unit | Unit | 0 |
- Apparently the variants
jkiorkjiare preferred.
"""
matmul_by_loop!(A, B, C, order)
Overwrite `C` by `A * B`. `order` indicates the looping order for triple loop.
"""
function matmul_by_loop!(A::Matrix, B::Matrix, C::Matrix, order::String)
m = size(A, 1)
p = size(A, 2)
n = size(B, 2)
fill!(C, 0)
if order == "jki"
for j = 1:n, k = 1:p, i = 1:m
C[i, j] += A[i, k] * B[k, j]
end
end
if order == "kji"
for k = 1:p, j = 1:n, i = 1:m
C[i, j] += A[i, k] * B[k, j]
end
end
if order == "ikj"
for i = 1:m, k = 1:p, j = 1:n
C[i, j] += A[i, k] * B[k, j]
end
end
if order == "kij"
for k = 1:p, i = 1:m, j = 1:n
C[i, j] += A[i, k] * B[k, j]
end
end
if order == "ijk"
for i = 1:m, j = 1:n, k = 1:p
C[i, j] += A[i, k] * B[k, j]
end
end
if order == "jik"
for j = 1:n, i = 1:m, k = 1:p
C[i, j] += A[i, k] * B[k, j]
end
end
end
using Random
Random.seed!(123)
m, p, n = 2000, 100, 2000
A = rand(m, p)
B = rand(p, n)
C = zeros(m, n);
jkiandkjilooping:
using BenchmarkTools
@benchmark matmul_by_loop!($A, $B, $C, "jki")
BenchmarkTools.Trial: 12 samples with 1 evaluation. Range (min … max): 409.931 ms … 548.997 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 425.141 ms ┊ GC (median): 0.00% Time (mean ± σ): 444.185 ms ± 46.687 ms ┊ GC (mean ± σ): 0.00% ± 0.00% █ █▆▁▁▁▆▁▆▆▁▁▁▁▁▁▁▁▁▆▁▁▁▁▁▁▁▁▁▁▁▆▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▆▁▁▁▁▁▁▁▁▁▁▁▁▁▆ ▁ 410 ms Histogram: frequency by time 549 ms < Memory estimate: 0 bytes, allocs estimate: 0.
@benchmark matmul_by_loop!($A, $B, $C, "kji")
BenchmarkTools.Trial: 8 samples with 1 evaluation. Range (min … max): 674.248 ms … 729.114 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 714.277 ms ┊ GC (median): 0.00% Time (mean ± σ): 712.280 ms ± 16.689 ms ┊ GC (mean ± σ): 0.00% ± 0.00% ▁ ▁ ▁ █ ▁ ▁ ▁ █▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█▁█▁█▁▁█▁▁▁▁▁▁▁▁▁█▁▁█ ▁ 674 ms Histogram: frequency by time 729 ms < Memory estimate: 0 bytes, allocs estimate: 0.
ikjandkijlooping:
@benchmark matmul_by_loop!($A, $B, $C, "ikj")
BenchmarkTools.Trial: 3 samples with 1 evaluation. Range (min … max): 2.321 s … 2.386 s ┊ GC (min … max): 0.00% … 0.00% Time (median): 2.375 s ┊ GC (median): 0.00% Time (mean ± σ): 2.361 s ± 34.822 ms ┊ GC (mean ± σ): 0.00% ± 0.00% █ █ █ █▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█▁▁▁▁▁▁▁▁▁█ ▁ 2.32 s Histogram: frequency by time 2.39 s < Memory estimate: 0 bytes, allocs estimate: 0.
@benchmark matmul_by_loop!($A, $B, $C, "kij")
BenchmarkTools.Trial: 3 samples with 1 evaluation. Range (min … max): 2.333 s … 2.348 s ┊ GC (min … max): 0.00% … 0.00% Time (median): 2.344 s ┊ GC (median): 0.00% Time (mean ± σ): 2.342 s ± 7.773 ms ┊ GC (mean ± σ): 0.00% ± 0.00% █ █ █ █▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█▁▁▁▁▁▁▁▁▁▁▁▁▁▁█ ▁ 2.33 s Histogram: frequency by time 2.35 s < Memory estimate: 0 bytes, allocs estimate: 0.
ijkandjiklooping:
@benchmark matmul_by_loop!($A, $B, $C, "ijk")
BenchmarkTools.Trial: 6 samples with 1 evaluation. Range (min … max): 889.913 ms … 1.017 s ┊ GC (min … max): 0.00% … 0.00% Time (median): 930.412 ms ┊ GC (median): 0.00% Time (mean ± σ): 940.485 ms ± 42.680 ms ┊ GC (mean ± σ): 0.00% ± 0.00% ▁ ▁ █ ▁ ▁ █▁▁▁▁▁▁▁▁▁▁▁▁▁▁█▁▁▁█▁▁▁▁▁▁▁▁▁█▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█ ▁ 890 ms Histogram: frequency by time 1.02 s < Memory estimate: 0 bytes, allocs estimate: 0.
@benchmark matmul_by_loop!($A, $B, $C, "ijk")
BenchmarkTools.Trial: 6 samples with 1 evaluation. Range (min … max): 886.608 ms … 922.833 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 903.909 ms ┊ GC (median): 0.00% Time (mean ± σ): 903.385 ms ± 13.468 ms ┊ GC (mean ± σ): 0.00% ± 0.00% █ █ █ █ █ █ █▁▁▁▁▁▁█▁▁▁▁▁▁▁▁▁▁▁▁▁▁█▁▁▁▁▁▁▁▁▁▁▁▁█▁▁▁▁▁▁█▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█ ▁ 887 ms Histogram: frequency by time 923 ms < Memory estimate: 0 bytes, allocs estimate: 0.
- Julia wraps BLAS library for matrix multiplication. We see BLAS library wins the
jkiandkjilooping by a large margin (multi-threading, Strassen algorithm, higher level-3 fraction by block outer product).
@benchmark mul!($C, $A, $B)
BenchmarkTools.Trial: 793 samples with 1 evaluation. Range (min … max): 4.850 ms … 11.389 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 6.007 ms ┊ GC (median): 0.00% Time (mean ± σ): 6.291 ms ± 1.009 ms ┊ GC (mean ± σ): 0.00% ± 0.00% ▁▂▇█▆▅▄▂▆▇▅▁▃ ▄▇▄▄▇▅█████████████▇▆██▇▆▇██▇▇▇▇▄▇▅█▇▇▇▄▅▇▇▇▅▅▅▁▇▆▅▆▇▆▅▆▄▆ █ 4.85 ms Histogram: log(frequency) by time 9.9 ms < Memory estimate: 0 bytes, allocs estimate: 0.
# direct call of BLAS wrapper function
@benchmark LinearAlgebra.BLAS.gemm!('N', 'N', 1.0, $A, $B, 0.0, $C)
BenchmarkTools.Trial: 790 samples with 1 evaluation. Range (min … max): 5.715 ms … 12.214 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 5.976 ms ┊ GC (median): 0.00% Time (mean ± σ): 6.312 ms ± 952.165 μs ┊ GC (mean ± σ): 0.00% ± 0.00% █▇▆█▆▄▂▃▂ ███████████▇▇▄▇▅▇█▇▅▇▇▇▆▇▆▇▅▄▅▆▄▄▁▇▇▇▆▆▇▄▁▁▁▇▄▄▆▄▇▅▆▅▄▅▄▁▁▄ █ 5.71 ms Histogram: log(frequency) by time 10.1 ms < Memory estimate: 0 bytes, allocs estimate: 0.
BLAS in R¶
- Tip for R usesr. Standard R distribution from CRAN uses a very out-dated BLAS/LAPACK library.
using RCall
R"""
library("microbenchmark")
microbenchmark($A %*% $B)
"""
RObject{VecSxp}
Unit: milliseconds
expr min lq mean median uq max neval
`#JL`$A %*% `#JL`$B 909.2172 916.2797 940.2293 931.8024 947.0514 1230.23 100
Re-building R from scratch using OpenBLAS or MKL will immediately boost linear algebra performance in R. Google
build R using MKLto get started. Similarly we can build Julia using MKL.Matlab uses MKL. Usually it's very hard to beat Matlab in terms of linear algebra (and it's expensive!).
Avoid memory allocation: some examples¶
- Transposing matrix is an expensive memory operation.
- In R, the command
t(A) %*% x
Athen perform matrix multiplication, causing unnecessary memory allocation- Julia is smart to avoid transposing matrix if possible.
- In R, the command
using Random, LinearAlgebra, BenchmarkTools
Random.seed!(123)
n = 1000
A = rand(n, n)
x = rand(n);
typeof(transpose(A))
Transpose{Float64, Matrix{Float64}}
fieldnames(typeof(transpose(A)))
(:parent,)
# same data in tranpose(A) and original matrix A
pointer(transpose(A).parent), pointer(A)
(Ptr{Float64} @0x00007fe7a7800000, Ptr{Float64} @0x00007fe7a7800000)
# dispatch to BLAS
# does *not* actually transpose the matrix
@benchmark transpose($A) * $x
BenchmarkTools.Trial: 10000 samples with 1 evaluation. Range (min … max): 71.486 μs … 692.121 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 87.752 μs ┊ GC (median): 0.00% Time (mean ± σ): 92.042 μs ± 17.339 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▁▃▅▇▇█▇▆▅▂▁ ▁▁▂▃▄▆███████████▇▅▅▄▄▃▃▃▃▃▃▃▃▂▂▂▂▂▂▂▂▂▂▂▁▂▂▁▁▁▂▁▁▁▁▁▁▁▁▁▁▁▁ ▃ 71.5 μs Histogram: frequency by time 147 μs < Memory estimate: 7.94 KiB, allocs estimate: 1.
# pre-allocate result
out = zeros(size(A, 2))
@benchmark mul!($out, transpose($A), $x)
BenchmarkTools.Trial: 10000 samples with 1 evaluation. Range (min … max): 69.739 μs … 475.971 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 83.509 μs ┊ GC (median): 0.00% Time (mean ± σ): 87.852 μs ± 14.373 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▃▅█▇█▇▅▄▂ ▁▂▃▄▆███████████▆▅▄▄▃▃▃▃▃▃▂▃▃▃▃▃▂▂▂▂▂▂▂▁▁▁▁▁▂▁▁▁▂▁▁▁▂▁▁▁▁▁▂▁ ▃ 69.7 μs Histogram: frequency by time 140 μs < Memory estimate: 0 bytes, allocs estimate: 0.
# or call BLAS wrapper directly
@benchmark LinearAlgebra.BLAS.gemv!('T', 1.0, $A, $x, 0.0, $out)
BenchmarkTools.Trial: 10000 samples with 1 evaluation. Range (min … max): 68.930 μs … 459.098 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 85.314 μs ┊ GC (median): 0.00% Time (mean ± σ): 92.348 μs ± 18.167 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▁▃▆▇█▇▇▅▃▁ ▁▁▂▃▄▆██████████▇▆▅▃▃▄▃▄▃▄▄▄▄▃▄▃▃▃▃▃▃▂▂▃▃▃▃▃▃▂▃▃▃▂▂▂▂▂▂▂▁▁▁▁ ▃ 68.9 μs Histogram: frequency by time 141 μs < Memory estimate: 0 bytes, allocs estimate: 0.
Broadcasting in Julia achieves vectorized code without creating intermediate arrays.
Suppose we want to calculate elementsize maximum of absolute values of two large arrays. In R or Matlab, the command
max(abs(X), abs(Y))
will create two intermediate arrays and then one result array.
using RCall
Random.seed!(123)
X, Y = rand(1000, 1000), rand(1000, 1000)
R"""
library(microbenchmark)
microbenchmark(max(abs($X), abs($Y)))
"""
RObject{VecSxp}
Unit: milliseconds
expr min lq mean median uq
max(abs(`#JL`$X), abs(`#JL`$Y)) 5.418381 6.065276 9.559118 7.078557 8.298674
max neval
83.00264 100
In Julia, dot operations are fused so no intermediate arrays are created.
# no intermediate arrays created, only result array created
@benchmark max.(abs.($X), abs.($Y))
BenchmarkTools.Trial: 2582 samples with 1 evaluation. Range (min … max): 892.227 μs … 13.614 ms ┊ GC (min … max): 0.00% … 66.26% Time (median): 1.299 ms ┊ GC (median): 0.00% Time (mean ± σ): 1.928 ms ± 2.262 ms ┊ GC (mean ± σ): 21.39% ± 15.21% ▃▇█▆▃▂ ▁ ██████▇▇▇▇▇▆▇▆▅▅▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▃▁▁▁▁▁▁▁▁▁▃▇██▇█▇▆▅▇ █ 892 μs Histogram: log(frequency) by time 11.5 ms < Memory estimate: 7.63 MiB, allocs estimate: 2.
Pre-allocating result array gets rid of memory allocation at all.
# no memory allocation at all!
Z = zeros(size(X)) # zero matrix of same size as X
@benchmark $Z .= max.(abs.($X), abs.($Y)) # .= (vs =) is important!
BenchmarkTools.Trial: 6054 samples with 1 evaluation. Range (min … max): 740.775 μs … 2.007 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 771.994 μs ┊ GC (median): 0.00% Time (mean ± σ): 816.781 μs ± 102.622 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▅█▇▆▅▄▄▃▃▃▃▄▄▃▂▂▃▂▁▁▂▁▁▁ ▁ ▁ ▂ ███████████████████████████████▇▇▇▆██▇▅▇▆▇▆▆▆▇▆▅▅▆▅▅▅▆▅▅▄▄▄▅▅ █ 741 μs Histogram: log(frequency) by time 1.23 ms < Memory estimate: 0 bytes, allocs estimate: 0.
- View avoids creating extra copy of matrix data.
Random.seed!(123)
A = randn(1000, 1000)
# sum entries in a sub-matrix
@benchmark sum($A[1:2:500, 1:2:500])
BenchmarkTools.Trial: 10000 samples with 1 evaluation. Range (min … max): 79.961 μs … 9.766 ms ┊ GC (min … max): 0.00% … 96.49% Time (median): 268.438 μs ┊ GC (median): 0.00% Time (mean ± σ): 296.359 μs ± 507.203 μs ┊ GC (mean ± σ): 10.42% ± 5.92% ▆▃ ▁▅▇▇███▇▇▆▅▃▃▂▂▂▂▂▁▂▁▁▁ ▁▁▁ ▃ ██▅█▆▅▅█▇▄▃▃▃▅▁▃▄▅▁▄▃▁▁▁▃▇███████████████████████████████▇▇▇▇ █ 80 μs Histogram: log(frequency) by time 440 μs < Memory estimate: 488.39 KiB, allocs estimate: 2.
# view avoids creating a separate sub-matrix
@benchmark sum(@view $A[1:2:500, 1:2:500])
BenchmarkTools.Trial: 10000 samples with 1 evaluation. Range (min … max): 102.922 μs … 303.586 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 103.595 μs ┊ GC (median): 0.00% Time (mean ± σ): 110.998 μs ± 20.398 μs ┊ GC (mean ± σ): 0.00% ± 0.00% █▆▄▅▃▂▁ ▁ ███████████▇▇▇▇▇▇▇▆▇█▇▇▇▆▆▇▇▇▆▇▇▆▅▅▅▆▅▅▆▇▆▆▆▆▆▅▅▅▅▅▅▅▆▅▅▄▅▄▄▅ █ 103 μs Histogram: log(frequency) by time 209 μs < Memory estimate: 0 bytes, allocs estimate: 0.
The @views macro, which can be useful in some operations. (See also Example 3 above.)
@benchmark @views sum($A[1:2:500, 1:2:500])
BenchmarkTools.Trial: 10000 samples with 1 evaluation. Range (min … max): 102.900 μs … 305.959 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 103.132 μs ┊ GC (median): 0.00% Time (mean ± σ): 108.654 μs ± 18.127 μs ┊ GC (mean ± σ): 0.00% ± 0.00% █▄▃▂▁▁ ▁ ████████▇▇▆▇█▇▆▅▆▆▅▄▄▅▆▇▆▆▆▅▅▅▅▅▅▅▅▅▆▅▅▄▅▄▆▄▆▆▆▆▆▆▅▅▅▅▅▄▅▅▄▅▄ █ 103 μs Histogram: log(frequency) by time 197 μs < Memory estimate: 0 bytes, allocs estimate: 0.
Acknowledgment¶
This lecture note has evolved from Dr. Hua Zhou's 2019 Spring Statistical Computing course notes available at http://hua-zhou.github.io/teaching/biostatm280-2019spring/index.html.