versioninfo()
Julia Version 1.9.3 Commit bed2cd540a1 (2023-08-24 14:43 UTC) Build Info: Official https://julialang.org/ release Platform Info: OS: macOS (x86_64-apple-darwin22.4.0) CPU: 8 × Intel(R) Core(TM) i5-8279U CPU @ 2.40GHz WORD_SIZE: 64 LIBM: libopenlibm LLVM: libLLVM-14.0.6 (ORCJIT, skylake) Threads: 2 on 8 virtual cores
using Pkg
Pkg.activate(pwd())
Pkg.instantiate()
Pkg.status()
Activating new project at `~/Dropbox/class/M1399.000200/2023/M1300_000200-2023fall/lectures/09-qr` No Changes to `~/Dropbox/class/M1399.000200/2023/M1300_000200-2023fall/lectures/09-qr/Project.toml` No Changes to `~/Dropbox/class/M1399.000200/2023/M1300_000200-2023fall/lectures/09-qr/Manifest.toml`
Status `~/Dropbox/class/M1399.000200/2023/M1300_000200-2023fall/lectures/09-qr/Project.toml` (empty project)
QR Decomposition¶
We learned Cholesky decomposition as one approach for solving linear regression.
Another approach for linear regression uses the QR decomposition.
This is how thelm()function in R does linear regression.
This is also how Julia's (and MATLAB's)\works for rectangular matrices.
using Random
Random.seed!(280) # seed
n, p = 5, 3
X = randn(n, p) # predictor matrix
y = randn(n) # response vector
# backslash finds the (minimum L2 norm) least squares solution
X \ y
3-element Vector{Float64}:
0.3795466676698624
0.6508866456093487
0.39225041956535506
We want to understand what is QR and how it is used for solving least squares problem.
Definitions¶
Assume $\mathbf{X} \in \mathbb{R}^{n \times p}$ has full column rank. Necessarilly $n \ge p$.
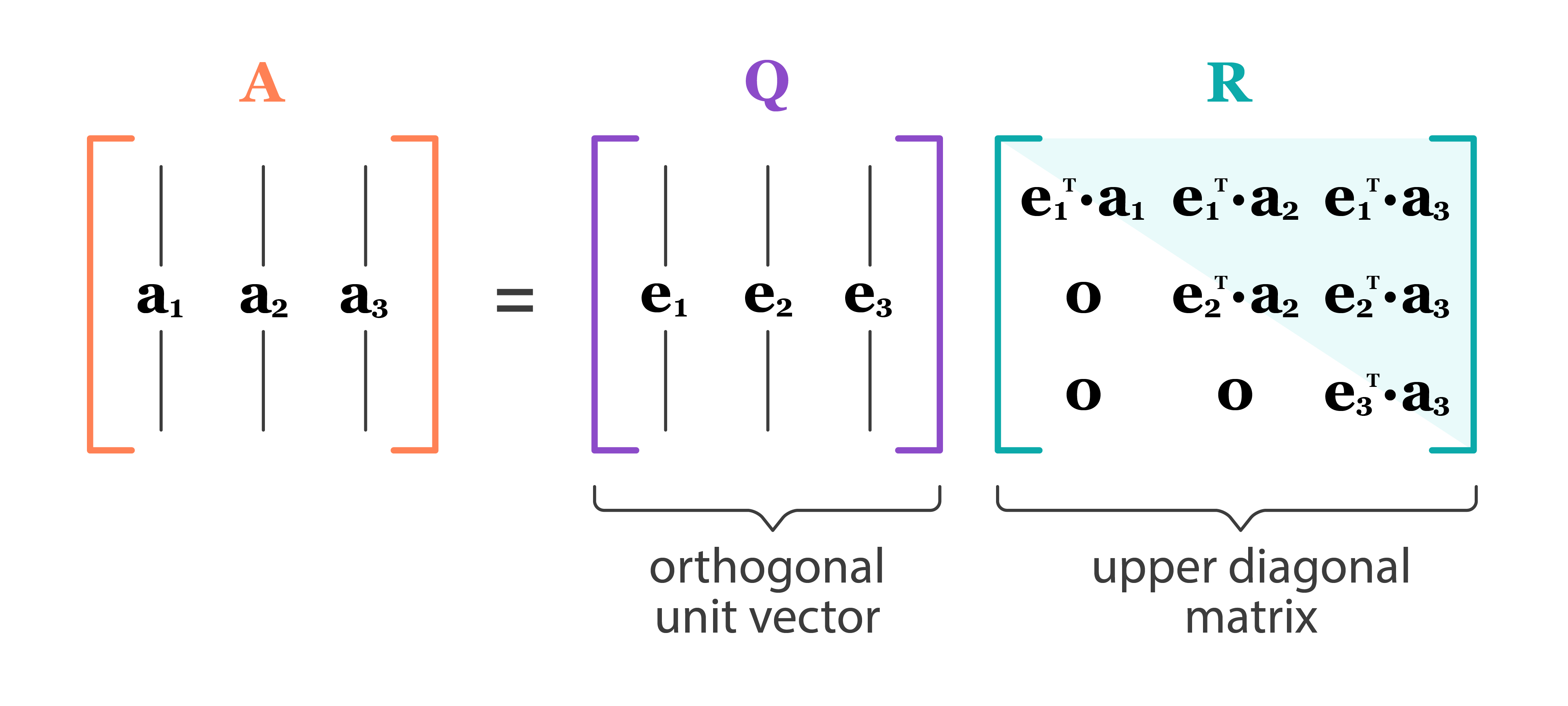
Full QR decomposition:
- $\mathbf{Q} \in \mathbb{R}^{n \times n}$, $\mathbf{Q}^T \mathbf{Q} = \mathbf{Q}\mathbf{Q}^T = \mathbf{I}_n$. In other words, $\mathbf{Q}$ is an orthogonal matrix.
- First $p$ columns of $\mathbf{Q}$ form an orthonormal basis of ${\cal R}(\mathbf{X})$ (**range** or column space of $\mathbf{X}$)
- Last $n-p$ columns of $\mathbf{Q}$ form an orthonormal basis of ${\cal N}(\mathbf{X}^T)$ (**null space** of $\mathbf{X}^T$)
- Recall that $\mathcal{N}(\mathbf{X}^T)=\mathcal{R}(\mathbf{X})^{\perp}$ and $\mathcal{R}(\mathbf{X}) \oplus \mathcal{N}(\mathbf{X}^T) = \mathbb{R}^n$.
- $\mathbf{R} \in \mathbb{R}^{n \times p}$ is upper triangular with positive diagonal entries.
- The lower $(n-p)\times p$ block of $\mathbf{R}$ is $\mathbf{0}$ (why?).
- Reduced QR decomposition:
where - $\mathbf{Q}_1 \in \mathbb{R}^{n \times p}$, $\mathbf{Q}_1^T \mathbf{Q}_1 = \mathbf{I}_p$. In other words, $\mathbf{Q}_1$ is a partially orthogonal matrix. Note $\mathbf{Q}_1\mathbf{Q}_1^T \neq \mathbf{I}_n$. - $\mathbf{R}_1 \in \mathbb{R}^{p \times p}$ is an upper triangular matrix with positive diagonal entries.
- Given QR decomposition $\mathbf{X} = \mathbf{Q} \mathbf{R}$,
$$
\mathbf{X}^T \mathbf{X} = \mathbf{R}^T \mathbf{Q}^T \mathbf{Q} \mathbf{R} = \mathbf{R}^T \mathbf{R} = \mathbf{R}_1^T \mathbf{R}_1.
$$
- Once we have a (reduced) QR decomposition of $\mathbf{X}$, we automatically have the Cholesky decomposition of the Gram matrix $\mathbf{X}^T \mathbf{X}$.
Application: least squares¶
- Normal equation
is equivalently written with reduced QR as $$ \mathbf{R}_1^T\mathbf{R}_1\beta = \mathbf{R}_1^T\mathbf{Q}_1^T\mathbf{y} $$
- $\mathbf{R}_1$ is invertible: we only need to solve the triangluar system
Multiplication $\mathbf{Q}_1^T \mathbf{y}$ is done implicitly (see below).
This method is numerically more stable than directly solving the normal equation, since $\kappa(\mathbf{X}^T\mathbf{X}) = \kappa(\mathbf{X})^2$!
In case we need standard errors, compute inverse of $\mathbf{R}_1^T \mathbf{R}_1$. This involves triangular solves.
Gram-Schmidt procedure¶
- Wait! Does $\mathbf{X}$ always have a QR decomposition?
- Yes. It is equivalent to the Gram-Schmidt procedure for basis orthonormalization.
:::: {.columns}
::: {.column width="50%"}

Jørgen Pedersen Gram, 1850-1916 :::
::: {.column width="50%"}

::::
Assume $\mathbf{X} = [\mathbf{x}_1 | \dotsb | \mathbf{x}_p] \in \mathbb{R}^{n \times p}$ has full column rank. That is, $\mathbf{x}_1,\ldots,\mathbf{x}_p$ are linearly independent.
Gram-Schmidt (GS) procedure produces nested orthonormal basis vectors $\{\mathbf{q}_1, \dotsc, \mathbf{q}_p\}$ that spans $\mathcal{R}(\mathbf{X})$, i.e.,
and $\langle \mathbf{q}_i, \mathbf{q}_j \rangle = \delta_{ij}$.
- The algorithm: 0. Initialize $\mathbf{q}_1 = \mathbf{x}_1 / \|\mathbf{x}_1\|_2$ 0. For $k=2, \ldots, p$,
GS conducts reduced QR¶
$\mathbf{Q} = [\mathbf{q}_1 | \dotsb | \mathbf{q}_p]$. Obviously $\mathbf{Q}^T \mathbf{Q} = \mathbf{I}_p$.
Where is $\mathbf{R}$?
- Let $r_{jk} = \langle \mathbf{q}_j, \mathbf{x}_k \rangle$ for $j < k$, and $r_{kk} = \|\mathbf{v}_k\|_2$.
- Re-write the above expression:
or
- If we let $r_{jk} = 0$ for $j > k$, then $\mathbf{R}=(r_{jk})$ is upper triangular and $$ \mathbf{X} = \mathbf{Q}\mathbf{R} . $$
{background-color="white"}¶
 {width=800}
{width=800}
Classical Gram-Schmidt¶
using LinearAlgebra
function cgs(X::Matrix{T}) where T<:AbstractFloat
n, p = size(X)
Q = Matrix{T}(undef, n, p)
R = zeros(T, p, p)
for j=1:p
Q[:, j] .= X[:, j]
for i=1:j-1
R[i, j] = dot(Q[:, i], X[:, j])
Q[:, j] .-= R[i, j] * Q[:, i]
end
R[j, j] = norm(Q[:, j])
Q[:, j] /= R[j, j]
end
Q, R
end
cgs (generic function with 1 method)
- CGS is unstable (we lose orthogonality due to roundoff errors) when columns of $\mathbf{X}$ are almost collinear.
e = eps(Float32)
A = [1f0 1f0 1f0; e 0 0; 0 e 0; 0 0 e]
4×3 Matrix{Float32}:
1.0 1.0 1.0
1.19209f-7 0.0 0.0
0.0 1.19209f-7 0.0
0.0 0.0 1.19209f-7
Q, R = cgs(A)
Q
4×3 Matrix{Float32}:
1.0 0.0 0.0
1.19209f-7 -0.707107 -0.707107
0.0 0.707107 0.0
0.0 0.0 0.707107
transpose(Q)*Q
3×3 Matrix{Float32}:
1.0 -8.42937f-8 -8.42937f-8
-8.42937f-8 1.0 0.5
-8.42937f-8 0.5 1.0
Qis hardly orthogonal.- Where exactly does the problem occur? (HW)
Modified Gram-Schmidt¶
- The algorithm: 0. Initialize $\mathbf{q}_1 = \mathbf{x}_1 / \|\mathbf{x}_1\|_2$ 0. For $k=2, \ldots, p$,
function mgs!(X::Matrix{T}) where T<:AbstractFloat
n, p = size(X)
R = zeros(T, p, p)
for j=1:p
for i=1:j-1
R[i, j] = dot(X[:, i], X[:, j])
X[:, j] -= R[i, j] * X[:, i]
end
R[j, j] = norm(X[:, j])
X[:, j] /= R[j, j]
end
X, R
end
mgs! (generic function with 1 method)
- $\mathbf{X}$ is overwritten by $\mathbf{Q}$ and $\mathbf{R}$ is stored in a separate array.
Q, R = mgs!(copy(A))
Q
4×3 Matrix{Float32}:
1.0 0.0 0.0
1.19209f-7 -0.707107 -0.408248
0.0 0.707107 -0.408248
0.0 0.0 0.816497
transpose(Q)*Q
3×3 Matrix{Float32}:
1.0 -8.42937f-8 -4.8667f-8
-8.42937f-8 1.0 3.14007f-8
-4.8667f-8 3.14007f-8 1.0
- So MGS is more stable than CGS. However, even MGS is not completely immune to instability.
B = [0.7f0 0.7071068f0; 0.7000001f0 0.7071068f0]
2×2 Matrix{Float32}:
0.7 0.707107
0.7 0.707107
Q, R = mgs!(copy(B))
Q
2×2 Matrix{Float32}:
0.707107 1.0
0.707107 0.0
transpose(Q)*Q
2×2 Matrix{Float32}:
1.0 0.707107
0.707107 1.0
Qis hardly orthogonal.- Where exactly the problem occurs? (HW)
Computational cost of CGS and MGS is $\sum_{k=1}^p 4n(k-1) \approx 2np^2$.
There are 3 algorithms to compute QR: (modified) Gram-Schmidt, Householder transform, (fast) Givens transform.
In particular, the Householder transform for QR is implemented in LAPACK and thus used in R and Julia.
QR by Householder transform¶
](http://www-history.mcs.st-andrews.ac.uk/BigPictures/Householder_2.jpeg) {width=200}
{width=200}
This is the algorithm for solving linear regression in R.
Assume again $\mathbf{X} = [\mathbf{x}_1 | \dotsb | \mathbf{x}_p] \in \mathbb{R}^{n \times p}$ has full column rank.
- Gram-Schmidt can be understood as:
where $\mathbf{R}_j$ are a sequence of upper triangular matrices.
- Householder QR does
where $\mathbf{H}_j \in \mathbf{R}^{n \times n}$ are a sequence of Householder transformation matrices.
It yields the **full QR** where $\mathbf{Q} = \mathbf{H}_1 \cdots \mathbf{H}_p \in \mathbb{R}^{n \times n}$. Recall that CGS/MGS only produces the **reduced QR** decomposition.
Householder transformation¶
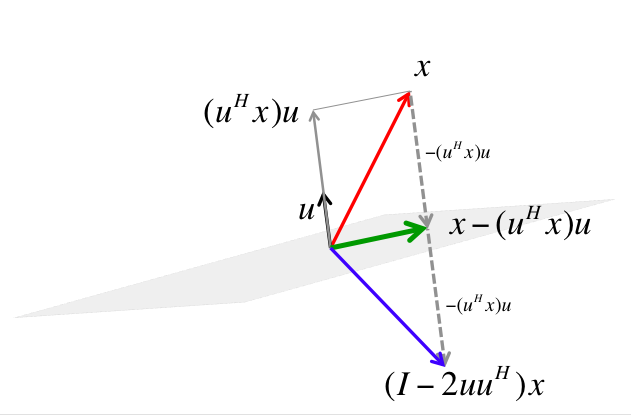
- For arbitrary $\mathbf{v}, \mathbf{w} \in \mathbb{R}^{n}$ with $\|\mathbf{v}\|_2 = \|\mathbf{w}\|_2$, we can construct a Householder matrix (or Householder reflector)
that transforms $\mathbf{v}$ to $\mathbf{w}$: $$ \mathbf{H} \mathbf{v} = \mathbf{w}. $$ $\mathbf{H}$ is symmetric and orthogonal. Calculation of Householder vector $\mathbf{u}$ costs $4n$ flops for general $\mathbf{u}$ and $\mathbf{w}$.
 {width=400}
{width=400}
- Now choose $\mathbf{H}_1$ so that
That is, $\mathbf{x} = \mathbf{x}_1$ and $\mathbf{w} = \pm\|\mathbf{x}_1\|_2\mathbf{e}_1$.
- Left-multiplying $\mathbf{H}_1$ zeros out the first column of $\mathbf{X}$ below (1, 1).
- Take $\mathbf{H}_2$ to zero the second column below diagonal:
- In general, choose the $j$-th Householder transform $\mathbf{H}_j = \mathbf{I}_n - 2 \mathbf{u}_j \mathbf{u}_j^T$, where
to zero the $j$-th column below diagonal. $\mathbf{H}_j$ takes the form $$ \mathbf{H}_j = \begin{bmatrix} \mathbf{I}_{j-1} & \\ & \mathbf{I}_{n-j+1} - 2 {\tilde u}_j {\tilde u}_j^T \end{bmatrix} = \begin{bmatrix} \mathbf{I}_{j-1} & \\ & {\tilde H}_{j} \end{bmatrix}. $$
- Applying a Householder transform $\mathbf{H} = \mathbf{I} - 2 \mathbf{u} \mathbf{u}^T$ to a matrix $\mathbf{X} \in \mathbb{R}^{n \times p}$
costs $4np$ flops. Householder updates never entails explicit formation of the Householder matrices.
- Note applying ${\tilde H}_j$ to $\mathbf{X}$ only needs $4(n-j+1)(p-j+1)$ flops.
Algorithm¶
for j=1:p
u = House!(X[j:n, j])
for i=j:p
X[j:n, j:p] .-= 2u*(u'X[j:n, j:p])
end
end
The process is done in place. Upper triangular part of $\mathbf{X}$ is overwritten by $\mathbf{R}_1$ and the essential Householder vectors ($\tilde u_{j1}$ is normalized to 1) are stored in $\mathbf{X}[j:n,j]$.
- Can ensure $u_{j1} \neq 0$ by a clever choice of the sign in determining vector $\mathbf{w}$ above (HW).
At the $j$-th stage
- computing the Householder vector ${\tilde u}_j$ costs $3(n-j+1)$ flops
- applying the Householder transform ${\tilde H}_j$ to the $\mathbf{X}[j:n, j:p]$ block costs $4(n-j+1)(p-j+1)$ flops
In total we need $\sum_{j=1}^p [3(n-j+1) + 4(n-j+1)(p-j+1)] \approx 2np^2 - \frac 23 p^3$ flops.
Where is $\mathbf{Q}$?
- $\mathbf{Q} = \mathbf{H}_1 \cdots \mathbf{H}_p$. In some applications, it's necessary to form the orthogonal matrix $\mathbf{Q}$.
Accumulating $\mathbf{Q}$ costs another $2np^2 - \frac 23 p^3$ flops.
When computing $\mathbf{Q}^T \mathbf{v}$ or $\mathbf{Q} \mathbf{v}$ as in some applications (e.g., solve linear equation using QR), no need to form $\mathbf{Q}$. Simply apply Householder transforms successively to the vector $\mathbf{v}$. (HW)
Computational cost of Householder QR for linear regression: $2n p^2 - \frac 23 p^3$ (regression coefficients and $\hat \sigma^2$) or more (fitted values, s.e., ...).
Householder QR with column pivoting¶
Consider rank deficient $\mathbf{X}$.
- At the $j$-th stage, swap the column
X[:, j]withX[:, k]wherekis the column number inX[j:n,j:p]with maximum $\ell_2$ norm to be the pivot column. If the maximum $\ell_2$ norm is 0, it stops, ending with
where $\mathbf{P} \in \mathbb{R}^{p \times p}$ is a permutation matrix and $r$ is the rank of $\mathbf{X}$. QR with column pivoting is rank revealing.
X, y
([0.12623784496408763 -1.1278278196026448 -0.8826696457022515; -2.3468794813834966 1.1478628422667982 1.7138424693341203; … ; -0.23920888512829233 -0.23706547458394342 1.0818212935057896; -0.5784508270929073 -0.6809935026697 -0.17040614729185025], [-1.794259674143309, 1.0913793110025305, 0.4266277597108536, -0.6244337204329091, 0.03204861737738283])
X \ y # least squares solution by QR
3-element Vector{Float64}:
0.3795466676698624
0.6508866456093487
0.39225041956535506
# same as
qr(X) \ y
3-element Vector{Float64}:
0.37954666766986195
0.6508866456093481
0.3922504195653549
cholesky(X'X) \ (X'y) # least squares solution by Cholesky
3-element Vector{Float64}:
0.37954666766986256
0.6508866456093485
0.3922504195653555
# QR factorization with column pivoting
xqr = qr(X, Val(true))
QRPivoted{Float64, Matrix{Float64}}
Q factor:
5×5 LinearAlgebra.QRPackedQ{Float64, Matrix{Float64}}:
-0.0407665 -0.692007 0.318693 0.185526 -0.619257
0.757887 -0.0465712 -0.260086 -0.522259 -0.288166
-0.618938 -0.233814 -0.404293 -0.624592 -0.0931611
0.0772486 -0.235405 -0.808135 0.53435 0.00216687
0.186801 -0.639431 0.119392 -0.131075 0.724429
R factor:
3×3 Matrix{Float64}:
-3.09661 1.60888 1.84089
0.0 1.53501 0.556903
0.0 0.0 -1.32492
permutation:
3-element Vector{Int64}:
1
2
3
xqr \ y # least squares solution
3-element Vector{Float64}:
0.3795466676698624
0.6508866456093487
0.39225041956535506
# thin Q matrix multiplication (a sequence of Householder transforms)
norm(xqr.Q * xqr.R - X[:, xqr.p]) # recovers X (with columns permuted)
1.071020016095422e-15
QR by Givens rotation¶
Householder transform $\mathbf{H}_j$ introduces batch of zeros into a vector.
Givens transform (aka Givens rotation, Jacobi rotation, plane rotation) selectively zeros one element of a vector.
Overall QR by Givens rotation is less efficient than the Householder method, but is better suited for matrices with structured patterns of nonzero elements.
- Givens/Jacobi rotations:
where $c = \cos(\theta)$ and $s = \sin(\theta)$. $\mathbf{G}(i,k,\theta)$ is orthogonal.
- Pre-multiplication by $\mathbf{G}(i,k,\theta)^T$ rotates counterclockwise $\theta$ radians in the $(i,k)$ coordinate plane. If $\mathbf{x} \in \mathbb{R}^n$ and $\mathbf{y} = \mathbf{G}(i,k,\theta)^T \mathbf{x}$, then
Apparently if we choose $\tan(\theta) = -x_k / x_i$, or equivalently, $$ \small \begin{eqnarray*} c = \frac{x_i}{\sqrt{x_i^2 + x_k^2}}, \quad s = \frac{-x_k}{\sqrt{x_i^2 + x_k^2}}, \end{eqnarray*} $$ then $y_k=0$.
- Pre-applying Givens transform $\mathbf{G}(i,k,\theta)^T \in \mathbb{R}^{n \times n}$ to a matrix $\mathbf{A} \in \mathbb{R}^{n \times m}$ only effects two rows of $\mathbf{
A}$: $$ \mathbf{A}([i, k], :) \gets \begin{bmatrix} c & s \\ -s & c \end{bmatrix}^T \mathbf{A}([i, k], :), $$ costing $6m$ flops.
- Post-applying Givens transform $\mathbf{G}(i,k,\theta) \in \mathbb{R}^{m \times m}$ to a matrix $\mathbf{A} \in \mathbb{R}^{n \times m}$ only effects two columns of $\mathbf{A}$:
costing $6n$ flops.
- QR by Givens: $\mathbf{G}_t^T \cdots \mathbf{G}_1^T \mathbf{X} = \begin{bmatrix} \mathbf{R}_1 \\ \mathbf{0} \end{bmatrix}$.
 {width=600}
{width=600}
Zeros in $\mathbf{X}$ can also be introduced row-by-row.
If $\mathbf{X} \in \mathbb{R}^{n \times p}$, the total cost is $3np^2 - p^3$ flops and $O(np)$ square roots.
Note each Givens transform can be summarized by a single number, which is stored in the zeroed entry of $\mathbf{X}$.
Applications: linear regression¶
QR decomposition of $\mathbf{X}$: $2np^2 - \frac 23 p^3$ flops.
Solve $\mathbf{R}^T \mathbf{R} \beta = \mathbf{R}^T \mathbf{Q}^T \mathbf{y}$ for $\beta$.
If $\mathbf{X}$ is full rank, then $\mathbf{R}$ is invertible, so we only need to solve the triangular system
Multiplication $\mathbf{Q}^T \mathbf{y}$ is done implicitly.
- If need standard errors, compute inverse of $\mathbf{R}^T \mathbf{R}$. This involves triangular solves.
Further reading¶
Section II.5.3 of Computational Statistics by James Gentle (2010).
Chapter 5 of Matrix Computation by Gene Golub and Charles Van Loan (2013).