第二讲:监督学习应用-线性回归¶
我们从监督学习的一些例子开始讲起。假设我们有一个经调查得到的数据集,内容是关于俄勒冈州波特兰地区$47$间出租公寓的面积与价格之间的关系表:
$$\begin{array}{c|c}living\ area(feet^2)&price(1000\$s)\\\hline2104&400\\1600&330\\2400&369\\1416&232\\3000&540\\\vdots&\vdots\end{array}$$我们可以画出一张关于面积-价格的图像:
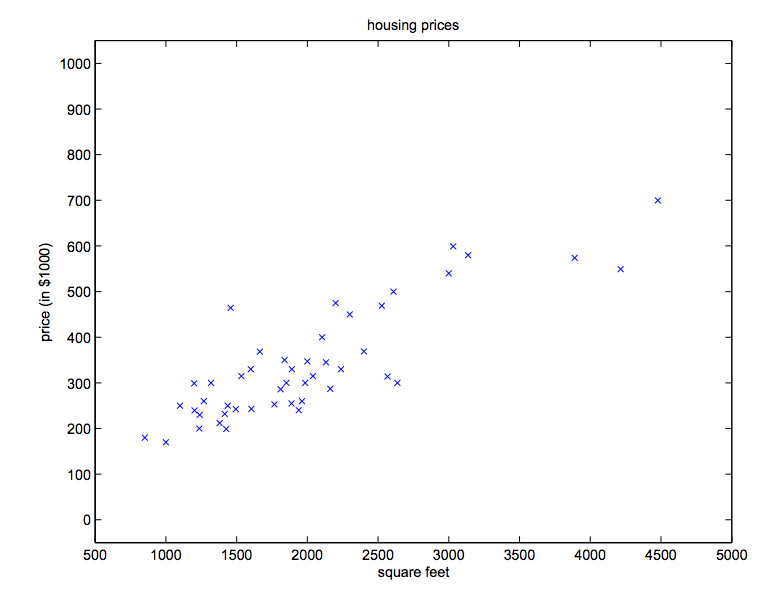
有了这样的数据,我们怎样才能预测波特兰地区其他出租公寓的价格,比如推导出一个从面积得出价格的函数。
为了今后的课程书写方便,我们约定一些未来将要用到的符号:
使用$x^{(i)}$来表示输入变量,也称作输入特征(feature),即本例中的实用面积(living area);
使用$y^{(i)}$来表示输入变量或目标变量(target),也就是我们尝试做出预测的值;
一对$(x^{(i)}),\ y^{(i)}$称作一个训练样本(training example);
用于做学习的数据集,也就是由$m$个$(x^{(i)}),\ y^{(i)}$组成的列表$\left\{\left(x^{(i)},\ y^{(i)}\right);\ i=1,\cdots,m\right\}$,称作训练集(training set);
需要注意的是,标记中的上标$^{(i)}$仅用于在训练集中标识训练样本的序号,并不表示指数。
$X$表示输入值空间,$Y$表示输出值空间,在本例中$X=Y=\mathbb{R}$(即都是一维实向量空间)。
更加正式的描述监督学习问题:我们的目标是,通过一个给定的训练集,训练一个函数$h:\ X\to Y$,如果$h(x)$能够通过较为准确的预测而得到结果$y$,则我们称这个$h(x)$是“好的”。因为一些历史原因,函数$h$被称为假设(hypothesis),监督学习用流程图表示如下:

当我们尝试预测的目标变量是连续的(就像我们公寓租金的例子一样),我们就说这是一个回归问题(regression problem)。
当$y$只能取几个分立的值(例如已知房间面积大小,我们需要判断这是一栋房屋还是一套公寓)时,我们称其为分类问题(classification problem)。
第一部分:线性回归(Linear Regression)¶
为了让例子更有趣,我们丰富一下数据集,在已知条件里再加上卧室的数量:
$$\begin{array}{c|c|c}living\ area(feet^2)&\#bedrooms&price(1000\$s)\\\hline2104&3&400\\1600&3&330\\2400&3&369\\1416&2&232\\3000&4&540\\\vdots&\vdots&\vdots\end{array}$$此时$x$是一个在$\mathbb{R}^2$向量空间中的二维向量,即$x_1^{(i)}$表示第$i$个房间样本的实用面积,$x_2^{(i)}$表示第$i$个房间样本的卧室的数量。(通常在设计学习算法时,我们都是自行决定选取哪些特征。假设我们在其他地方做房屋价格调研,那么我们可能会将“是否每个房间都有壁炉”、“卫生间数量”等其他因素纳入输入特征。)
要实现一个监督学习算法,我们必须确定函数(假设)$h$的形式,作为本课程的第一个例子,我们选择使用一个简单的线性函数来逼近$y$:
$$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2$$在式子里的$\theta_i$叫做参数(或权重),用于参数化$X\to Y$的线性函数映射空间。在不产生混淆的情况下,我们会省略$h_\theta(x)$中的下标$\theta$,简单记为$h(x)$。在上式中我们省略了第一项中的$x_0=1$(即截距项),补上这一项后有:
$$h(x)=\sum_{i=1}^n\theta_ix_i=\theta^Tx$$上式最右侧中的$\theta$和$x$都是向量,$n$代表输入向量中元素个数(不包含$x_0$)。
现在,有了训练集,我们应该如何选择(训练)参数$\theta$呢?其中一种合理的方法是使得计算出的$h(x)$与真实结果$y$尽量接近(至少对训练集中的已有数据做到尽量接近)。为了形式化这个“尽量接近”的问题,我们定义一个关于$\theta$的函数,使其能够描述$h(x^{(i)})$与相应$y^{(i)}$间的差距,并称其为成本函数(cost function):
$$J(\theta)=\frac{1}{2}\sum_{i=1}^n\left(h_\theta\left(x^{(i)}\right)-y^{(i)}\right)^2\tag{J}$$以前见过线性回归的同学应该熟悉上式,这就是最小二乘回归模型中常见的最小二乘成本函数。随着课程的进行,我们会发现最小二乘法仅是它所在的一族算法中的特例。
1. 最小均方法(LMS: Least mean squares algorithm)¶
我们需要选取合适的$\theta$以使得$J(\theta)$取最小值。为了达到这种效果,我们可以使用一种搜索算法,算法起始于某个关于$\theta$的“初始猜测值”,然后不断的修改$\theta$以使$J(\theta)$减小,直到最终$\theta$收敛于使得$J(\theta)$取最小处。特别的,我们讲一下梯度下降(gradient descent)法:算法从某个初始的$\theta$起,不断更新$\theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)$($:=$表示赋值,该赋值运算同时作用于所有的$\theta_j,\ j=0,\cdots,n$)。赋值运算中的$\alpha$称为学习速率,通常采用手动设置(learning rate,在本例中,它决定了我们“向下山走”时每一步的大小,过小的话收敛太慢,过大的话可能错过最小值)。这是一种很自然的算法,每一步总是寻找使$J$下降最“陡”的方向(就像找最快下山的路一样)。
为了实现这是算法,我们需要找出偏导数是什么。我们从最简单的情况入手,假设只有一个训练样本$(x,\ y)$,这样我们就可以忽略$(J)$式中的求和步骤:
$$\begin{align}\frac{\partial}{\partial\theta_j}J(\theta)&=\frac{\partial}{\partial\theta_j}\frac{1}{2}\left(h_\theta(x)-y\right)^2\\&=2\cdot\frac{1}{2}\left(h_\theta(x)-y\right)\cdot\frac{\partial}{\partial\theta_j}\left(h_\theta(x)-y\right)\\&=\left(h_\theta(x)-y\right)\cdot\frac{\partial}{\partial\theta_j}\left(\sum_{i=0}^n\theta_ix_i-y\right)\\&=\left(h_\theta(x)-y\right)x_j\end{align}$$训练集仅有一条数据的情况给了我们更新规则:$\theta_j:=\theta_j+\alpha\left(y^{(i)}-h_\theta(x^{(i)})\right)x_j^{(i)}$。
这条规则称为最小均方(LMS: Least mean squares)更新规则,也被称作Widrow-Hoff学习规则。这条规则一些看上去很直观、自然的特征,比如更新的幅度与误差项$\left(y^{(i)}-h_\theta(x^{(i)})\right)$的大小呈正比。因此,如果我们拿到一条训练向量,其目标量$y^{(i)}$与我们函数的预测值$h_\theta(x^{(i)}$非常接近,则在这条规则作用下,函数的参数$\theta_j$只需要很小的调整;相反的,如果预测值与目标量误差较大,则会得到一个较大的参数调整。
上面,我们使用仅含有一条训练样例的训练集推导出了LMS规则,我们需要将规则推广以适用于正常的训练集,介绍两种方法:
一种方法是:
Repeat until convergence {$\qquad\quad\quad\theta_j:=\theta_j+\alpha\underbrace{\displaystyle\sum_{i=1}^m\left(y^{(i)}-h_\theta(x^{(i)})\right)x_j^{(i)}}\qquad\quad(for\ every\ j)$
}
对于所有的$j$,重复迭代$\theta_j:=\theta_j+\alpha\displaystyle\sum_{i=1}^m\left(y^{(i)}-h_\theta(x^{(i)})\right)x_j^{(i)}$直到$\theta_j$收敛。
从这个式子里容易看出,大括号中的求和过程就是$\frac{\partial J(\theta)}{\partial\theta_j}$(在有$m$个训练样本时,观察$(J)$式)。所以,这个方法其实就是对$J(\theta)$原始的成本函数做了简单的梯度下降。该方法在每一步搜索“最陡方向”时都会遍历整个训练集,所以也被称作批量梯度下降(batch gradient descent)。值得注意的是,梯度下降可以容易的达到局部最小值,而且我们此处的优化问题也只有一个全局最优解(没有局部最小值)。因此,在本例中,梯度下降总是收敛于全局最小值(当然学习速率$\alpha$不能过大)。况且成本函数$J$确实是一个凸二次函数(仅有一个全局最小值)。
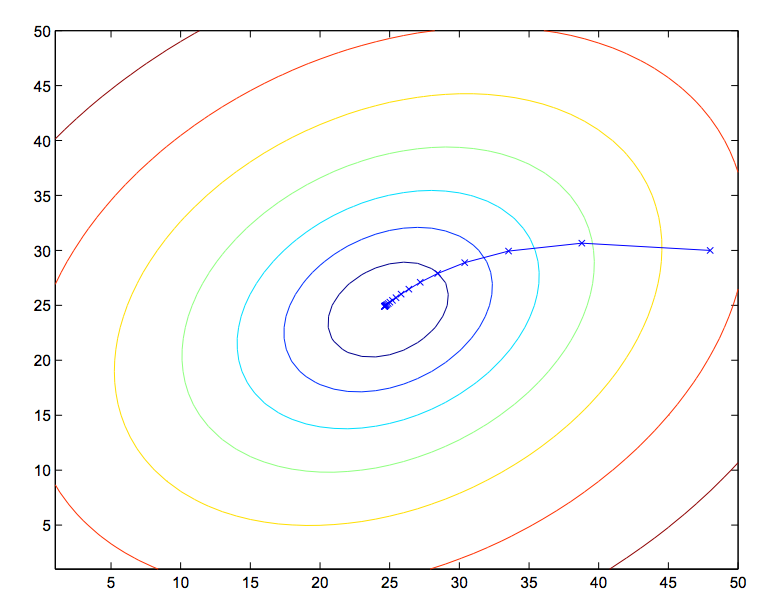
图中的椭圆为某二次函数的等高线,同时也显示了梯度下降法从初始值$(48,\ 30)$到最小值中间的轨迹。图中的“×”标记了梯度下降过程中经过的一系列$\theta$值。
关于收敛,我们可以查看两侧迭代是否相差很多,如果相差无几则可以判断收敛;更常用的方法是检查$J(\theta)$,如果这个值不再发生较大变化时,也可以判断收敛。关于找如何“找”最陡下山路径,其实求偏导本身就已经给出了最陡路径。
我们运行批量梯度下降算法用$\theta$拟合“公寓租金”训练集,以求得根据面积预测价格的函数,最终得到$\theta_0=71.27,\ \theta_1=0.1345$。当我们在最开始的“面积-价格”图中画出关于面积$x$的函数$h_\theta(x)$时,有:

如果将卧室数量也纳入输入特征,则会得到$\theta_0=89.60,\ \theta_1=0.1392,\ \theta_2=-8.738$。这个结果也是通过批量梯度下降求得。
我们接下来介绍第二种方法:
Loop { for i=1 to m, {$\qquad\qquad\quad\quad\theta_j:=\theta_j+\alpha\left(y^{(i)}-h_\theta(x^{(i)})\right)x_j^{(i)}\qquad\qquad\quad(for\ every\ j)$
} }
在这个方法中,我们每次仅使用一个训练样本,根据由这个样本得到的误差梯度来更新参数$\theta$。整个算法运行完毕时,对每一套$\theta$参数,每个样本只使用了一次。这就是随机梯度下降(stochastic gradient descent),也称作增量梯度下降(incremental gradient descent)。相对于批量梯度下降每走一步都需要遍历整个训练集(如果训练集样本很多,即$m$很大时,就是非常繁重的计算),随机梯度下降每一步就轻松很多,之后就是不断地根据遇到的每一个样本调整参数。通常情况下,随机梯度下降能够比批量梯度下降更快的使$\theta$接近最优解。(然而,值得注意的是,随机梯度下降可能永远都不会收敛于最小值点,参数$\theta$将在$J(\theta)$最小值附近持续摆动。不过,在实践中,最小值附近的解通常都足够接近最小值。另外,在随机梯度下降的实际操作中,随着迭代步骤的进行,我们会慢慢减小$\alpha$的值至$0$,这样也可以保证参数收敛于全局最小值,而不是在其附近持续摆动)。也是因为效率原因,在遇到训练集中包含大量样本的情况下,我们通常会选用随机梯度下降法。
2. 正规方程组(The normal equations)¶
梯度下降给了我们一种最小化$J$的途径,下面我们看另一种方法。这次我们直接通过计算实现最小化,不再依靠类似梯度下降中使用的分步迭代算法。此方法会直接对$J$求$\theta$的偏导,并使偏导为零,以求$J$的极值点。正规方程组会涉及较多的线性代数,为了避免大篇幅的矩阵求导等运算,我们引入一些新的记号。
2.1 矩阵求导¶
定义函数$f:\ \mathbb{R}^{m\times n}\to\mathbb{R}$,这是一个从$m\times n$阶矩阵到实数的映射,我们定义对“$f$关于$A$的函数”求关于$A$的导数:
$$\nabla_Af(A)=\begin{bmatrix}\frac{\partial f}{\partial A_{11}}&\cdots&\frac{\partial f}{\partial A_{1n}}\\\vdots&\ddots&\vdots\\\frac{\partial f}{\partial A_{m1}}&\cdots&\frac{\partial f}{\partial A_{mn}}\end{bmatrix}$$可以发现,$\nabla_Af(A)$的梯度是一个$m\times n$阶矩阵,它的第$(i,\ j)$个元素为$\frac{\partial f}{\partial A_{ij}}$。举个例子,矩阵$A=\begin{bmatrix}A_{11}&A_{12}\\A_{21}&A_{22}\end{bmatrix}$是一个二阶方阵,定义函数$f:\ \mathbb{R}^{2\times 2}\to \mathbb{R}$,有$f(A)=\frac{3}{2}A_{11}+5A_{12}^2+A_{21}A_{22}$,于是有$\nabla_Af(A)=\begin{bmatrix}\frac{3}{2}&10A_{12}\\A_{22}&A_{21}\end{bmatrix}$。
在引入$\mathrm{tr}$来表示矩阵的迹(trace)。对于一个$n$阶方阵$A$,定义$A$的迹为其对角线元素之和:
$$\mathrm{tr}A=\sum_{i=1}^nA_{ii}$$实数的迹就是它本身,$a\in\mathbb{R},\ \mathrm{tr}\ a=a$。(如果以前没遇到过这种“操作符记号”,可以把$A$的迹看做作用在$A$上的"迹"函数$\mathrm{tr}(A)$,而对于迹,我们通常不写括号)。
矩阵的迹符合“按次序”的交换律:
$$\mathrm{tr}AB=\mathrm{tr}BA,\quad \mathrm{tr}ABC=\mathrm{tr}CAB=\mathrm{tr}BCA,\quad \mathrm{tr}ABCD=\mathrm{tr}DABC=\mathrm{tr}CDAB=\mathrm{tr}BCDA$$下面的推论中$A,\ B$皆为方阵:
$$\begin{align}\mathrm{tr}A&=\mathrm{tr}A^T\\\mathrm{tr}(A+B)&=\mathrm{tr}A+\mathrm{tr}B\\\mathrm{tr}\ aA&=a\mathrm{tr}A\end{align}$$我们就不证明上面这些推论了(有些性质我们会在后面的章节使用)。接下来是关于迹和导数的推论:
$$\begin{align}\nabla_A\mathrm{tr}AB&=B^T\tag{1}\\\nabla_{A^T}f(A)&=\left(\nabla_Af(A)\right)^T\tag{2}\\\nabla_A\mathrm{tr}ABA^TC&=CAB+C^TAB^T\tag{3}\\\nabla_A\lvert A\rvert&=\lvert A\rvert\left(A^{-1}\right)^T\tag{4}\end{align}$$结合推论$(2),\ (3)$有:
$$\nabla_{A^T}\ \mathrm{tr}ABA^TC=B^TA^TC^T+BA^TC\tag{5}$$推论$(4)$只用于非奇异方阵,$\lvert A\rvert$表示矩阵的行列式。
为了使这些推论更形象,我们详细解释一下等式$(1)$为何成立。设有矩阵$B\in\mathbb{R}^{n\times m}$,我们可以以$f(A)=\mathrm{tr}AB$为原型定义函数$f:\ \mathbb{R}^{m\times n}\to\mathbb{R}$。因为$A\in\mathbb{R}^{m\times n}$,所以$AB\in\mathbb{R}^{m\times m}$为方阵,所以我们对其求迹是可行的。因此函数$f$的确做了$\mathbb{R}^{m\times n}$到$\mathbb{R}$的映射。然后我们再对其应用一开始定义的矩阵求导,计算$\nabla_Af(A)$,根据定义可知,结果仍是一个$m\times n$的矩阵。根据矩阵求导定义,$\mathrm{tr}AB$对$A$求导后,结果矩阵中第$(i,\ j)$个元素应为$B_{ji}$,也就是$B^T$的第$(i,\ j)$个元素。
推论$(1)-(3)$都较为简单,而推论$(4)$可以从逆的伴随矩阵表示法得出:定义$A'$是方阵$A$的代数余子式(其第$(i,\ j)$元素为$(-1)^{i+j}$乘以“从$A$中删掉第$i$行和第$j$列所得到的方阵”的行列式)于是可以证明$A^{-1}=\frac{\left(A'\right)^T}{\lvert A\rvert}$(可以找一个二阶方阵来验证,如果想要看完整证明可以参考中高阶线代课本,如Charles Curtis, 1991, Linear Algebra, Springer。也可以参考MIT线性代数第二十讲笔记)这个结论表明$A'=\lvert A\rvert\left(A^{-1}\right)^T$,同时,行列式可以表示为$\lvert A\rvert=\sum_jA_{ij}A'_{ij}$(按第$j$列做代数余子式列展开),注意到$\left(A'\right)_{ij}$并不依赖元素$A_{ij}$(从代数余子式的定义得到),这说明$\frac{\partial\lvert A\rvert}{A_{ij}}=A'_{ij}$,综上得$(4)$。
2.2 再看最小二乘¶
有了矩阵求导,我们再来看如何形式化“使$J(\theta)$能够取到最小值”的$\theta$。我们将$J$重新按照矩阵及向量的标记法表示。
对于已知训练集,定义设计矩阵(design matrix)$X$,这是一个$m\times n$矩阵(如果算上截距项,则应是$m\times (n+1)$矩阵,第一项为$\theta_0x_0,\ x_0=1$),矩阵以各训练样本作为行向量:$X=\begin{bmatrix}—\left(x^{(1)}\right)^T—\\—\left(x^{(2)}\right)^T—\\\vdots\\—\left(x^{(m)}\right)^T—\end{bmatrix}$。
同样的,将训练集中的所有目标值放入$m$维列向量$\vec y=\begin{bmatrix}y^{(1)}\\y^{(2)}\\\vdots\\y^{(m)}\end{bmatrix}$。
再将$h_\theta\left(x^{(i)}\right)=\left(x^{(i)}\right)^T\theta$表示为向量形式有$X\theta-\vec y=\begin{bmatrix}\left(x^{(1)}\right)^T\theta\\\left(x^{(2)}\right)^T\theta\\\vdots\\\left(x^{(m)}\right)^T\theta\end{bmatrix}-\begin{bmatrix}y^{(1)}\\y^{(2)}\\\vdots\\y^{(m)}\end{bmatrix}=\begin{bmatrix}h_\theta\left(x^{(1)}\right)-y^{(1)}\\h_\theta\left(x^{(2)}\right)-y^{(2)}\\\vdots\\h_\theta\left(x^{(m)}\right)-y^{(m)}\end{bmatrix}$。
在线性代数中我们知道,向量与自身做内积得到向量长度的平方,即$z^Tz=\sum_iz_i^2$,则有:
$$\begin{align}\frac{1}{2}\left(X\theta-\vec y\right)^T\left(X\theta-\vec y\right)&=\frac{1}{2}\sum_{i=1}^m\left(h_\theta\left(x^{(i)}\right)-y^{(i)}\right)^2\\&=J(\theta)\end{align}$$最后,为了最小化$J$,我们来求$J$关于$\theta$的导数,于是有:
$$\begin{align}\nabla_\theta J(\theta)&=\nabla_\theta\frac{1}{2}\left(X\theta-\vec y\right)^T\left(X\theta-\vec y\right)\\&=\frac{1}{2}\nabla_\theta\left(\theta^TX^TX\theta-\theta^TX^T\vec y-\vec{y}^TX\theta+\vec{y}^T\vec y\right)\\&=\frac{1}{2}\nabla_\theta\mathrm{tr}\left(\theta^TX^TX\theta-\theta^TX^T\vec y-\vec{y}^TX\theta+\vec{y}^T\vec y\right)\\&=\frac{1}{2}\nabla_\theta\left(\mathrm{tr}\theta^TX^TX\theta-2\mathrm{tr}\ \vec{y}^TX\theta\right)\\&=\frac{1}{2}\left(X^TX\theta+X^TX\theta-2X^T\vec y\right)\\&=X^TX\theta-X^T\vec y\end{align}$$- 第二步括号内的运算其实是一个数($\left(X\theta-\vec y\right)$长度的平方),所以可以在第三步中使用性质“实数的迹就是它本身”;
- 第三步到第四部使用了推论$\mathrm{tr}A=\mathrm{tr}A^T$合并项;
- 第四步到第五步使用推论$(5):\ \nabla_{A^T}\ \mathrm{tr}ABA^TC=B^TA^TC^T+BA^TC$,其中$A^T=\theta,\ B=B^T=X^TX,\ C=I$;以及推论$(1):\ \nabla_A\mathrm{tr}AB=B^T$
最终得到正规方程组(normal equations):
$$\bbox[30px,border:2px solid red]{X^TX\theta=X^T\vec y}$$因此,我们得到形式化的使得“使$J(\theta)$能够取到最小值”的 $\theta=\left(X^TX\right)^{-1}X^T\vec y$。
另外,在MIT线性代数第二十讲笔记有关于正规方程组几何意义(向量空间投影)的推导。