Base de données relationnelles :¶
Introduction :¶
Le développement des traitements informatiques nécessite la manipulation de données de plus en plus nombreuses.
Pour que ce traitement soit efficace, il est nécessaire que les données soient structurées.
Jusqu'à présent, nous avons essentiellement utilisé des structures de données comme des tableaux, des dictionnaires, qui supposent l'existence d'un ordre permettant le classement de l'information.
Un tel classement présente des limites car d'autres critères peuvent être pertinents et ranger ces données dans un tableau exige d'en privilégier certains au détriments d'autres.
Les bases de données relationnelles (BDR) permettent d’organiser, de stocker, de mettre à jour et d’interroger des données structurées volumineuses utilisées simultanément par différents programmes ou différents utilisateurs.
Les bases de données relationnelles (BDR) qui offrent un moyen d'organiser efficacement les données et de les manipuler grâce à des requêtes.
Schématiquement, une base de données est un ensemble de tables contenant des données reliées entre elles par des relations ; on y extrait de l'information par le biais de requêtes exprimées dans un langage spécifique. Les traitements peuvent conjuguer le recours au langage SQL et à un langage de programmation.
Des systèmes de gestion de bases de données (SGBD) de très grande taille (de l’ordre du pétaoctet) sont au centre de nombreux dispositifs de collecte, de stockage et de production d’informations.

Parmi les SGBDR, la situation de SQLite est un peu particulière. En effet, celui-ci repose sur un accès fichier (et non réseau). Il est destiné à gérer de petites bases de données non administrées, à usage individuel. Et puisque son code source a été placé dans le domaine public, il peut s'intégrer facilement à d'autres logiciels. Ceci en fait l'un des SGBDR les plus utilisés dans le monde, puisque à ce jour on peut dénombrer plus d'un milliard de copies et plus de 1000 milliards de bases de données SQLite.
Modèle relationnel :¶
Le fonctionnement des SGBDR s'appuie sur le modèle relationnel créé par E.F. Codd en 1970, qui est une formalisation mathématique des données en table, similaires à celles rencontrées avec le format CSV (Comma-separated values).
Voici un exemple de table présentant des ouvrages en bibliothèque.
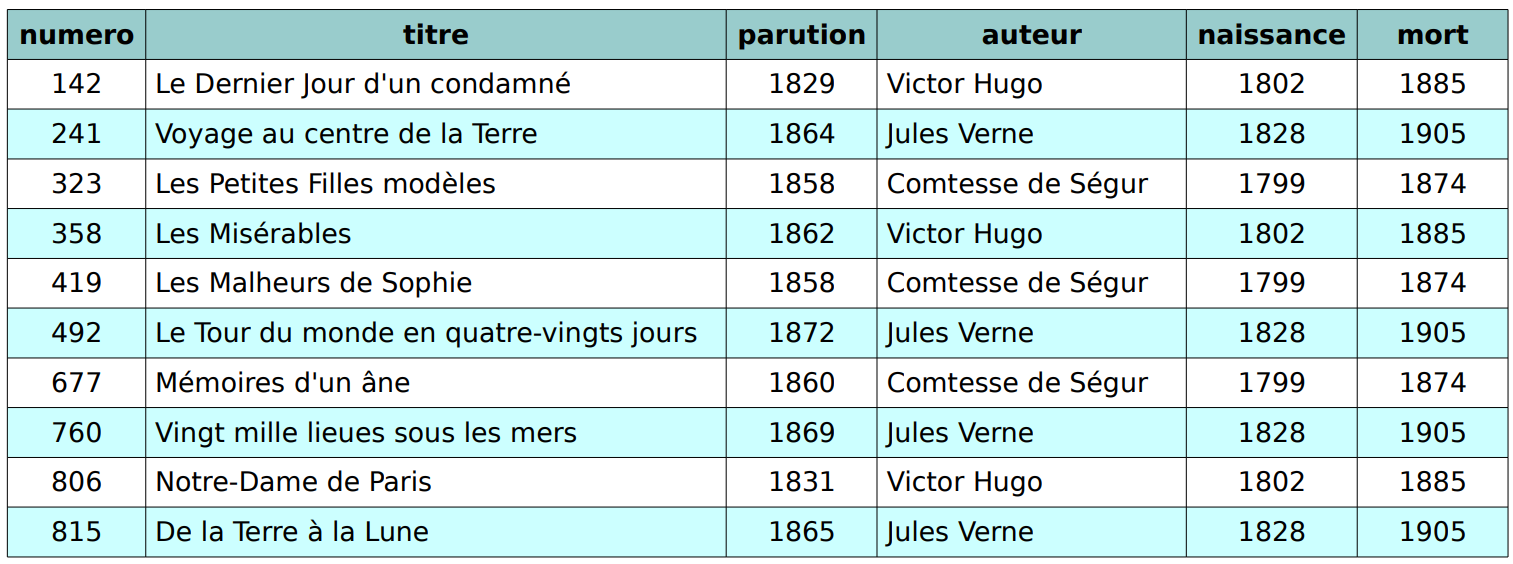
Cette table est la représentation de la relation Ouvrage composée :
d'une en-tête comptant 6 attributs (noms de colonnes) : numero, titre, date, auteur, naissance et mort, qui possèdent chacun un domaine de valeurs spécifique :
- numero est un entier ;
- titre est un texte (une chaîne de caractères plus ou moins longue) ;
- parution est une année ;
- auteur est une chaîne de caractères (de taille limitée par exemple à 128) ;
- naissance est une année ;
- mort est une année ;
Ces informations sont condensées dans ce qu'on appelle le schéma relationnel de la relation Ouvrage afin d'en donner la structure :
pseudo
Ouvrage(numero:entier, titre:texte, parution:année, auteur:caractères[128], naissance:année, mort:année)
- les lignes de cette table, qu'on appelle aussi des enregistrements, sont des tuples (t_uplet, ici 6-uplet, sextuplet) tel que celui-ci :
pseudo
(142, "Le Dernier Jour d'un condamné", 1829, "Victor Hugo", 1802, 1885)
Ainsi, la relation est un ensemble de tuples, et la base de données, un ensemble de relations.
Remarque :
Comme ce modèle se fonde sur la théorie des ensembles, il ne peut y avoir deux tuples identiques dans une relation, et donc deux lignes identiques dans une table. Pas plus que d'ordre entre ces lignes.
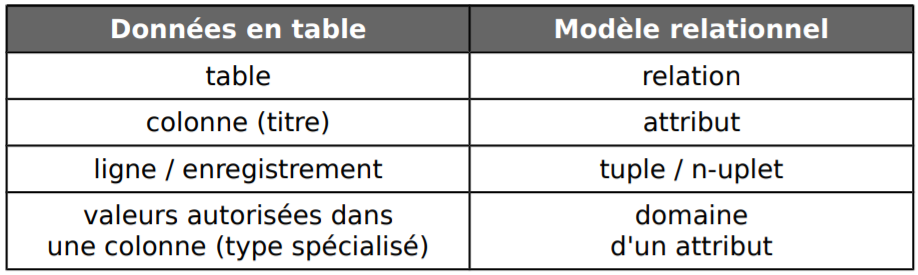
Pour résumer, le modèle relationnel apporte une vision théorique de la table :
Conception d'une base de donnée :¶
À y regarder de plus près, la table Ouvrage n'est pas très satisfaisante :
- On y retrouve le nom des auteurs dupliqué plusieurs fois.
- Cette redondance d'informations occupe inutilement de la place en mémoire, et toute correction du nom doit être effectuée partout où celui-ci apparaît.
- Par ailleurs il y a un risque d'inconsistance lors de la copie des années de naissance et de mort à l'insertion d'un nouvel ouvrage pour un auteur existant.
- Enfin, il n'est pas possible de conserver les informations sur un auteur dans le cas où l'on supprime tous ses ouvrages.
Cette organisation en une seule table pose donc problèmes. Compte tenu de l'analyse précédente il convient de concevoir autrement cette base de données en dissociant ouvrage et auteur, tout en maintenant le lien entre les deux.
Voici les tables obtenues en séparant les données :
- On rassemble les informations sur les auteurs en créant une table dédiée dans laquelle chaque auteur est identifié par un nombre entier
id_auteurappelé clé primaire.
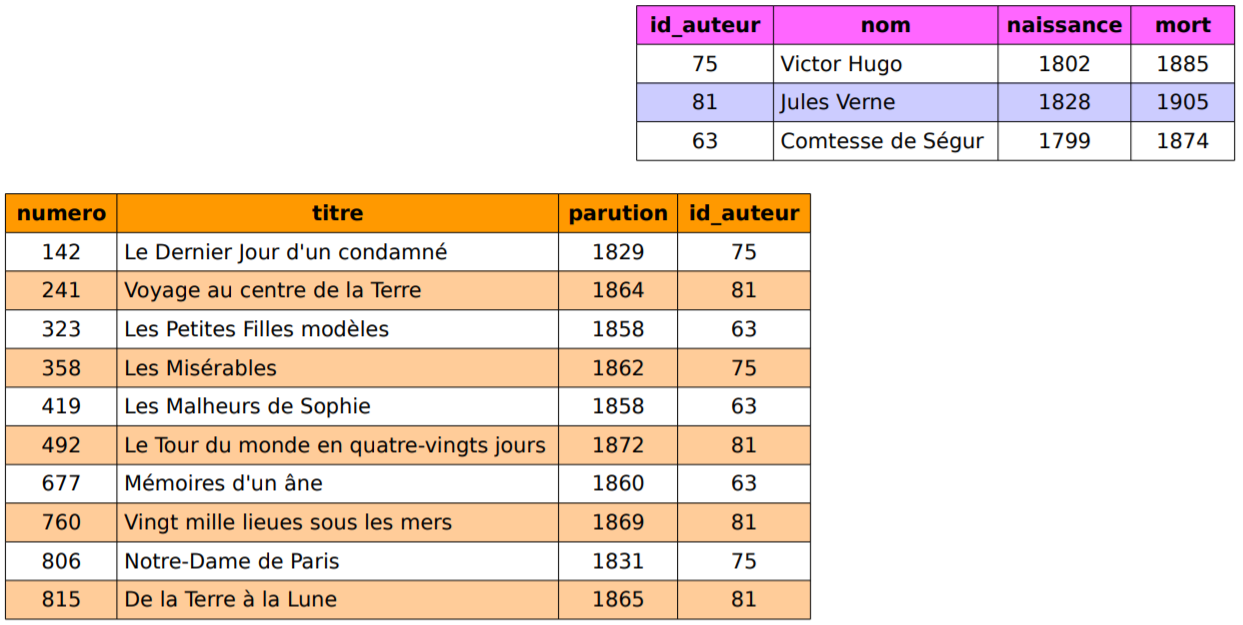
- Dans la table des ouvrages on remplace les triplets (auteur, naissance, mort) par la clé d'identification de l'auteur définie dans la table des auteurs. La clé
id_auteurest qualifiée de clé étrangère car elle se réfère à la clé primaireid_auteurde la table des auteurs.
La relation Auteur est composée de 3 tuples comportant 4 attributs :
id_auteurqui tient le rôle de clé primaire en permettant d'identifier un auteur ;nomqui est le nom de l'auteur ;naissancequi correspond à l'année de naissance de l'auteur ;mortqui correspond à l'année de la mort de l'auteur.
Son schéma relationnel est :
pseudo
Auteur(id_auteur:entier, nom:caractères[128], naissance:année, mort:année)
La relation Ouvrage est toujours composée de 10 tuples, mais on ne trouve plus que 4 attributs :
numeroqui est la clé primaire identifiant de manière unique chaque ouvragetitrequi est le titre de l'ouvrageparutionqui est l'année de publication de l'ouvrageid_auteurqui est la clé étrangère faisant référence à l'auteur de l'ouvrage
Son schéma relationnel est :
pseudo
Ouvrage(numero:entier, titre:texte, parution:année, #id_auteur:entier)
Ces deux schémas relationnels forment le schéma relationnel de la base de données.
Le diagramme UML suivant illustre ce schéma relationnel et l'association entre les deux relations :

Ce diagramme rassemble les différents attributs ainsi que les clés primaire (souligné ou préfixé par PK pour primary key) et étrangère (préfixé par # ou par FK pour foreign key) de chaque relation.
Il précise en outre l'association Écrire qui lie Auteur et Ouvrage.
la présence des valeurs 1 et 0.., qu'on appelle des multiplicités dans un diagramme UML, informe qu'un auteur a écrit entre 0 et un nombre quelconque d'ouvrages ( représentant un entier naturel quelconque), tandis qu'un ouvrage a été écrit par 1 auteur.
Les contraintes d'intégrité :¶
Afin de maintenir des données valides et cohérentes tout au long de la vie de la base de données, il faut s'assurer en permanence du respect des contraintes d'intégrité suivantes qui sont fixées à la création de la base données :
- L'intégrité de domaine : les valeurs doivent appartenir au domaine fixé pour chaque attribut ;
- L'intégrité de relation : chaque tuple est unique et doit être identifié par une clé primaire qui ne peut être nulle ;
- L'intégrité de référence entre deux relations : toute clé étrangère doit correspondre à une clé primaire existante.
Ce qu'il faut retenir :¶
- En apportant une vision plus abstraite de la table avec la notion de relation, le modèle relationnel permet de s'affranchir de la façon dont les données sont organisées et stockées en mémoire ;
- Une base de données se compose de plusieurs relations afin de supprimer les redondances, faciliter les mises à jour et permettre les ajouts partiels ;
- La structure d'une relation est donnée par son schéma relationnel qui précise le nom des attributs et leur domaine de valeurs ;
- L'ensemble des tuples forme le corps de la relation ;
- Dans chaque relation, l'un des attributs (parfois un groupe) dont la valeur permet d'identifier de manière unique un tuple, est appelé clé primaire ;
- Certaines relations possèdent un attribut qui se réfère à la clé primaire d'une autre relation à laquelle elle est ainsi liée ; un tel attribut est appelé clé étrangère ;
- Les contraintes d'intégrité de domaine, de relation et de référence doivent être constamment maintenues afin d'assurer la cohérence des données.
Outils pour dessiner des schémas relationnels :¶
Références aux programmes :¶
Bases de données :¶
| Contenus | Capacités attendues | Commentaires |
|---|---|---|
| Modèle relationnel : relation, attribut, domaine, clef primaire, clef étrangère, schéma relationnel. | Identifier les concepts définissant le modèle relationnel. | Ces concepts permettent d’exprimer les contraintes d’intégrité (domaine, relation et référence). |
| Base de données relationnelle. | Savoir distinguer la structure d’une base de données de son contenu. Repérer des anomalies dans le schéma d’une base de données. |
La structure est un ensemble de schémas relationnels qui respecte les contraintes du modèle relationnel. Les anomalies peuvent être des redondances de données ou des anomalies d’insertion, de suppression, de mise à jour. On privilégie la manipulation de données nombreuses et réalistes. |

Ce document, basé sur les travaux de Jean DIRAISON et d'autres enseignants de la liste NSI, est mis à disposition selon les termes de la Licence Creative Commons Attribution - Partage dans les Mêmes Conditions 4.0 International.
Pour toute question, suggestion ou commentaire : eric.madec@ecmorlaix.fr