In [70]:
import transformers
import pandas as pd
import tensorflow as tf
from huggingface_hub import notebook_login
import os
transformers.logging.set_verbosity_error()
In [71]:
notebook_login()
VBox(children=(HTML(value='<center> <img\nsrc=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
A Whirlwind Tour of the 🤗 Hugging Face Ecosystem
Christopher Akiki
Figures in these slides reproduced under the Apache License from Natural Language Processing with Transformers published by O'Reilly Media, Inc.
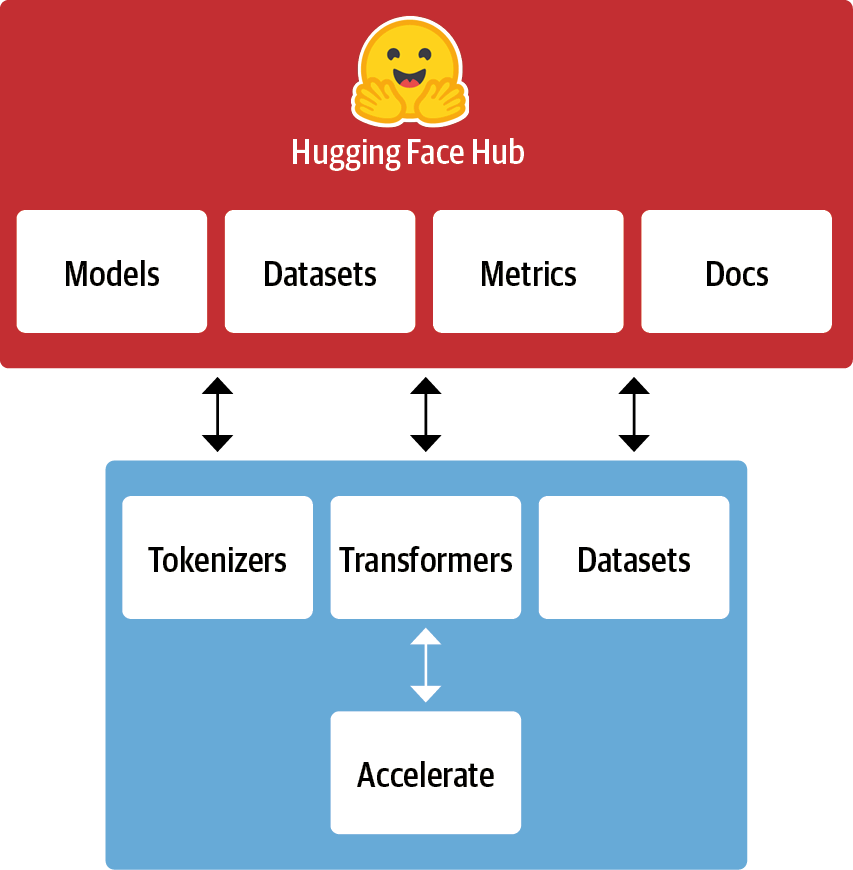

🤗 Pipelines
In [1]:
from transformers import pipeline
from transformers.pipelines import get_supported_tasks
/usr/lib/python3/dist-packages/requests/__init__.py:89: RequestsDependencyWarning: urllib3 (1.26.9) or chardet (3.0.4) doesn't match a supported version!
warnings.warn("urllib3 ({}) or chardet ({}) doesn't match a supported "
In [5]:
print(get_supported_tasks())
['audio-classification', 'automatic-speech-recognition', 'conversational', 'feature-extraction', 'fill-mask', 'image-classification', 'image-segmentation', 'ner', 'object-detection', 'question-answering', 'sentiment-analysis', 'summarization', 'table-question-answering', 'text-classification', 'text-generation', 'text2text-generation', 'token-classification', 'translation', 'zero-shot-classification', 'zero-shot-image-classification']
In [7]:
text = """One of the best orchestra in the world. I came to Leipzig\
mainly to have one experience with Gewanhaus Leipzig Orchestra.
Under the baton of Maestro Andris Nelsons, Bruckner symphony #8 was so affection.
The acustic and layout of the concert hall is nice."""
Sentiment Analysis¶
In [11]:
p = pipeline("text-classification",
model='distilbert-base-uncased-finetuned-sst-2-english', device=-1)
In [9]:
outputs = p(text)
outputs[0]
Out[9]:
{'label': 'POSITIVE', 'score': 0.9998534917831421}
Named-Entity Recognition¶
In [12]:
p = pipeline("ner", aggregation_strategy="simple", model="dbmdz/bert-large-cased-finetuned-conll03-english", device=-1)
In [13]:
outputs = p(text)
pd.DataFrame(outputs)
Out[13]:
| entity_group | score | word | start | end | |
|---|---|---|---|---|---|
| 0 | LOC | 0.999257 | Leipzig | 50 | 57 |
| 1 | ORG | 0.990783 | Gewanhaus Leipzig Orchestra | 104 | 131 |
| 2 | PER | 0.996171 | Andris Nelsons | 173 | 187 |
| 3 | MISC | 0.564721 | B | 189 | 190 |
| 4 | ORG | 0.268703 | ##ck | 192 | 194 |
| 5 | MISC | 0.364942 | ##ner | 194 | 197 |
Question Answering¶
In [23]:
p = pipeline("question-answering", model="distilbert-base-cased-distilled-squad", device=-1)
In [34]:
questions = ['What city did I visit?',
'Why did I visit Leipzig?',
'What music did the orchestra play?',
'Who lead the orchestra?']
In [42]:
outputs = p(question=questions, context=text)
with pd.option_context('display.max_colwidth', -1):
display(pd.DataFrame(zip(questions, [o['answer'] for o in outputs]), columns=['Question', 'Answer']))
| Question | Answer | |
|---|---|---|
| 0 | What city did I visit? | Leipzig |
| 1 | Why did I visit Leipzig? | to have one experience with Gewanhaus Leipzig Orchestra |
| 2 | What music did the orchestra play? | Bruckner symphony #8 |
| 3 | Who lead the orchestra? | Maestro Andris Nelsons |
Translation¶
In [20]:
p = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de", device=-1)
In [21]:
outputs = p(text, clean_up_tokenization_spaces=True)
print(outputs[0]['translation_text'])
Ich bin vor allem nach Leipzig gekommen, um eine Erfahrung mit dem Gewanhaus Leipzig Orchestra zu machen. Unter der Leitung von Maestro Andris Nelsons war die Bruckner Sinfonie #8 so liebevoll, dass die Akustik und Gestaltung des Konzertsaales schön ist.
🤗 Tokenizers

In [43]:
import nltk
nltk.download('gutenberg')
[nltk_data] Downloading package gutenberg to /root/nltk_data... [nltk_data] Unzipping corpora/gutenberg.zip.
Out[43]:
True
In [44]:
print(nltk.corpus.gutenberg.fileids())
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
In [45]:
moby_dick_raw = nltk.corpus.gutenberg.raw('melville-moby_dick.txt')
In [46]:
size = len(moby_dick_raw.encode())
print(f"{size/1024**2:.2f} MiB")
1.19 MiB
In [47]:
from tokenizers import Tokenizer, normalizers, pre_tokenizers, processors
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
In [48]:
unk_token = "[UNK]"
pad_token = "[PAD]"
cls_token = "[CLS]"
sep_token = "[SEP]"
mask_token = "[MASK]"
special_tokens = [unk_token, pad_token, cls_token, sep_token, mask_token]
vocab_size = 6_000
WordPiece Tokenizer¶
In [49]:
custom_tokenizer = Tokenizer(WordPiece(unk_token=unk_token))
Sequence of Normalizers¶
In [50]:
custom_normalizer = normalizers.Sequence(
[normalizers.NFKD(), normalizers.Lowercase(), normalizers.StripAccents()]
)
Sequence of Pretokenizers¶
In [51]:
custom_pre_tokenizer = pre_tokenizers.Sequence(
[pre_tokenizers.WhitespaceSplit(), pre_tokenizers.Punctuation()]
)
WordPiece Trainer¶
In [52]:
custom_trainer = WordPieceTrainer(vocab_size=vocab_size, special_tokens=special_tokens, show_progress=False)
In [53]:
custom_tokenizer.normalizer = custom_normalizer
custom_tokenizer.pre_tokenizer = custom_pre_tokenizer
In [54]:
%%time
custom_tokenizer.train_from_iterator([moby_dick_raw], trainer=custom_trainer)
CPU times: user 8.61 s, sys: 2.04 s, total: 10.7 s Wall time: 1.05 s
In [55]:
custom_tokenizer.get_vocab_size()
Out[55]:
6000
In [56]:
encoding = custom_tokenizer.encode("Let us test this tokenizer")
print(encoding.tokens)
['let', 'us', 'test', 'this', 'token', '##ize', '##r']
In [58]:
cls_token_id = custom_tokenizer.token_to_id(cls_token)
sep_token_id = custom_tokenizer.token_to_id(sep_token)
custom_post_processor = processors.TemplateProcessing(
single=f"{cls_token}:0 $A:0 {sep_token}:0",
pair=f"{cls_token}:0 $A:0 {sep_token}:0 $B:1 {sep_token}:1",
special_tokens=[(cls_token, cls_token_id), (sep_token, sep_token_id)],
)
custom_tokenizer.post_processor = custom_post_processor
In [59]:
encoding = custom_tokenizer.encode("Let us test this tokenizer")
print(encoding.tokens)
['[CLS]', 'let', 'us', 'test', 'this', 'token', '##ize', '##r', '[SEP]']
In [60]:
encoding = custom_tokenizer.encode("This is the first sentence", "This is sentence number 2")
print(encoding.tokens)
print(encoding.ids)
print(encoding.type_ids)
['[CLS]', 'this', 'is', 'the', 'first', 'sent', '##ence', '[SEP]', 'this', 'is', 'sent', '##ence', 'number', '2', '[SEP]'] [2, 175, 156, 95, 514, 2071, 470, 3, 175, 156, 2071, 470, 2117, 18, 3] [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
Using our custom tokenizer with a model¶
In [61]:
from transformers import PreTrainedTokenizerFast
model_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=custom_tokenizer,
unk_token=unk_token,
pad_token=pad_token,
cls_token=cls_token,
sep_token=sep_token,
mask_token=mask_token,
)
In [62]:
text_batch = ["To be or not to be.", "It was the best of times.", "Call me Ishmael."]
In [63]:
model_tokenizer(text_batch, padding=True, return_tensors="tf")
Out[63]:
{'input_ids': <tf.Tensor: shape=(3, 9), dtype=int32, numpy=
array([[ 2, 115, 124, 222, 185, 115, 124, 15, 3],
[ 2, 128, 160, 95, 996, 105, 823, 15, 3],
[ 2, 557, 207, 2841, 15, 3, 1, 1, 1]],
dtype=int32)>, 'token_type_ids': <tf.Tensor: shape=(3, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>, 'attention_mask': <tf.Tensor: shape=(3, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 0, 0]], dtype=int32)>}
🤗 Datasets
Apache Arrow backend ➡️ Low RAM use¶
import os; import psutil; import timeit
from datasets import load_dataset
mem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
wiki = load_dataset("wikipedia", "20220301.en", split="train")
mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
print(f"RAM memory used: {(mem_after - mem_before)} MB")
*****RAM memory used: 50 MB*****
Apache Arrow Backend ➡️ Fast Iteration¶
s = """batch_size = 1000
for i in range(0, len(wiki), batch_size):
batch = wiki[i:i + batch_size]
"""
time = timeit.timeit(stmt=s, number=1, globals=globals())
print(f"Time to iterate over the {wiki.dataset_size >> 30}GB dataset: {time:.1f} sec, "
f"ie. {float(wiki.dataset_size >> 27)/time:.1f} Gb/s")
*****Time to iterate over the 18 GB dataset: 70.5 sec, ie. 2.1 Gb/s*****
In [12]:
from datasets import list_datasets, load_dataset
In [13]:
all_datasets = list_datasets()
In [14]:
len(all_datasets)
Out[14]:
4419
In [15]:
[d for d in all_datasets if "emotion" in d]
Out[15]:
['emotion', 'go_emotions', 'Mansooreh/sharif-emotional-speech-dataset', 'Pyjay/emotion_nl', 'SetFit/go_emotions', 'SetFit/emotion', 'jakeazcona/short-text-labeled-emotion-classification', 'jakeazcona/short-text-multi-labeled-emotion-classification', 'mrm8488/goemotions', 'pariajm/sharif_emotional_speech_dataset', 'rubrix/go_emotions_training', 'rubrix/go_emotions_multi-label', 'lewtun/autoevaluate__emotion', 'stepp1/tweet_emotion_intensity', 'lewtun/autoevaluate__go_emotions']
In [21]:
emotions = load_dataset("emotion")
emotions
Using custom data configuration default Reusing dataset emotion (/tf/cache/HF/datasets/emotion/default/0.0.0/348f63ca8e27b3713b6c04d723efe6d824a56fb3d1449794716c0f0296072705)
0%| | 0/3 [00:00<?, ?it/s]
Out[21]:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})
In [32]:
print(emotions['train'].info.description)
print(125*"*")
print(emotions['train'].citation)
Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. For more detailed information please refer to the paper.
*****************************************************************************************************************************
@inproceedings{saravia-etal-2018-carer,
title = "{CARER}: Contextualized Affect Representations for Emotion Recognition",
author = "Saravia, Elvis and
Liu, Hsien-Chi Toby and
Huang, Yen-Hao and
Wu, Junlin and
Chen, Yi-Shin",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
month = oct # "-" # nov,
year = "2018",
address = "Brussels, Belgium",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D18-1404",
doi = "10.18653/v1/D18-1404",
pages = "3687--3697",
abstract = "Emotions are expressed in nuanced ways, which varies by collective or individual experiences, knowledge, and beliefs. Therefore, to understand emotion, as conveyed through text, a robust mechanism capable of capturing and modeling different linguistic nuances and phenomena is needed. We propose a semi-supervised, graph-based algorithm to produce rich structural descriptors which serve as the building blocks for constructing contextualized affect representations from text. The pattern-based representations are further enriched with word embeddings and evaluated through several emotion recognition tasks. Our experimental results demonstrate that the proposed method outperforms state-of-the-art techniques on emotion recognition tasks.",
}
In [33]:
train_ds = emotions["train"]
train_ds
Out[33]:
Dataset({
features: ['text', 'label'],
num_rows: 16000
})
In [38]:
train_ds.features['label']
Out[38]:
ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], id=None)
In [40]:
train_ds.features['label'].int2str(5)
Out[40]:
'surprise'
In [41]:
len(train_ds)
Out[41]:
16000
In [44]:
train_ds[11]
Out[44]:
{'text': 'i do feel that running is a divine experience and that i can expect to have some type of spiritual encounter',
'label': 1}
In [45]:
train_ds[:10]
Out[45]:
{'text': ['i didnt feel humiliated',
'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake',
'im grabbing a minute to post i feel greedy wrong',
'i am ever feeling nostalgic about the fireplace i will know that it is still on the property',
'i am feeling grouchy',
'ive been feeling a little burdened lately wasnt sure why that was',
'ive been taking or milligrams or times recommended amount and ive fallen asleep a lot faster but i also feel like so funny',
'i feel as confused about life as a teenager or as jaded as a year old man',
'i have been with petronas for years i feel that petronas has performed well and made a huge profit',
'i feel romantic too'],
'label': [0, 0, 3, 2, 3, 0, 5, 4, 1, 2]}
In [46]:
train_ds[:10]['text']
Out[46]:
['i didnt feel humiliated', 'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake', 'im grabbing a minute to post i feel greedy wrong', 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property', 'i am feeling grouchy', 'ive been feeling a little burdened lately wasnt sure why that was', 'ive been taking or milligrams or times recommended amount and ive fallen asleep a lot faster but i also feel like so funny', 'i feel as confused about life as a teenager or as jaded as a year old man', 'i have been with petronas for years i feel that petronas has performed well and made a huge profit', 'i feel romantic too']
In [47]:
def compute_tweet_length(row):
return {"tweet_length": len(row['text'].split())}
In [48]:
train_ds = train_ds.map(compute_tweet_length, load_from_cache_file=False)
0%| | 0/16000 [00:00<?, ?ex/s]
In [ ]:
train_ds.push_to_hub('emotion-with-length')
In [49]:
train_ds.filter(lambda row: row['tweet_length'] < 25)
0%| | 0/16 [00:00<?, ?ba/s]
Out[49]:
Dataset({
features: ['text', 'label', 'tweet_length'],
num_rows: 11668
})
In [52]:
train_ds.sort("tweet_length")[:10]
Loading cached sorted indices for dataset at /tf/cache/HF/datasets/emotion/default/0.0.0/348f63ca8e27b3713b6c04d723efe6d824a56fb3d1449794716c0f0296072705/cache-fb279c5ae640310a.arrow
Out[52]:
{'text': ['no response',
'earth crake',
'one day',
'one night',
'at school',
'in sweden',
'no description',
'during lectures',
'i feeling distressed',
'i feel foolish'],
'label': [3, 4, 0, 1, 3, 4, 3, 1, 4, 0],
'tweet_length': [2, 2, 2, 2, 2, 2, 2, 2, 3, 3]}
In [54]:
def batched_compute_tweet_length(batch_of_rows):
return {"tweet_length": [len(text.split()) for text in batch_of_rows['text']]}
In [55]:
train_ds.map(batched_compute_tweet_length, batched=True, batch_size=2000, load_from_cache_file=False)
0%| | 0/8 [00:00<?, ?ba/s]
Out[55]:
Dataset({
features: ['text', 'label', 'tweet_length'],
num_rows: 16000
})
In [56]:
%time train_ds.map(compute_tweet_length, load_from_cache_file=False)
0%| | 0/16000 [00:00<?, ?ex/s]
CPU times: user 1.13 s, sys: 101 ms, total: 1.23 s Wall time: 1.08 s
Out[56]:
Dataset({
features: ['text', 'label', 'tweet_length'],
num_rows: 16000
})
In [57]:
%time train_ds.map(batched_compute_tweet_length, batched=True, batch_size=2000, load_from_cache_file=False, )
0%| | 0/8 [00:00<?, ?ba/s]
CPU times: user 102 ms, sys: 5.46 ms, total: 107 ms Wall time: 102 ms
Out[57]:
Dataset({
features: ['text', 'label', 'tweet_length'],
num_rows: 16000
})
In [58]:
train_ds.column_names
Out[58]:
['text', 'label', 'tweet_length']
In [59]:
train_ds = train_ds.remove_columns('tweet_length')
train_ds
Out[59]:
Dataset({
features: ['text', 'label'],
num_rows: 16000
})
Loading your own files¶
| Data format | Loading script | Example |
|---|---|---|
| CSV & TSV | csv | load_dataset("csv", data_files="my_file.csv") |
| Text files | text | load_dataset("text", data_files="my_file.txt") |
| JSON & JSON Lines | json | load_dataset("json", data_files="my_file.jsonl") |
| Pickled DataFrames | pandas | load_dataset("pandas", data_files="my_dataframe.pkl") |
In [60]:
import pandas as pd
In [61]:
emotions.set_format(type="pandas")
emotions_df = emotions['train'][:]
In [62]:
emotions_df['label_name'] = emotions_df['label'].apply(lambda x: train_ds.features['label'].int2str(x))
In [68]:
emotions_df.head(10)
Out[68]:
| text | label | label_name | |
|---|---|---|---|
| 0 | i didnt feel humiliated | 0 | sadness |
| 1 | i can go from feeling so hopeless to so damned... | 0 | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 | anger |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 | love |
| 4 | i am feeling grouchy | 3 | anger |
| 5 | ive been feeling a little burdened lately wasn... | 0 | sadness |
| 6 | ive been taking or milligrams or times recomme... | 5 | surprise |
| 7 | i feel as confused about life as a teenager or... | 4 | fear |
| 8 | i have been with petronas for years i feel tha... | 1 | joy |
| 9 | i feel romantic too | 2 | love |
In [65]:
emotions_df['label_name'].value_counts()
Out[65]:
joy 5362 sadness 4666 anger 2159 fear 1937 love 1304 surprise 572 Name: label_name, dtype: int64
In [66]:
emotions_df['text'].str.split().apply(len).describe()
Out[66]:
count 16000.000000 mean 19.166313 std 10.986905 min 2.000000 25% 11.000000 50% 17.000000 75% 25.000000 max 66.000000 Name: text, dtype: float64
In [ ]:
emotions.reset_format()
In [ ]:
train_ds
🤗 Transformers
In [ ]:
from transformers import DistilBertTokenizer, TFDistilBertForSequenceClassification, DataCollatorWithPadding
model_checkpoint = "distilbert-base-uncased"
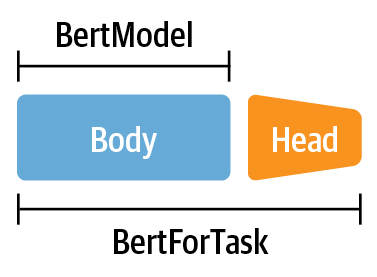
Transfer Learning via Feature Extraction (Homework)¶
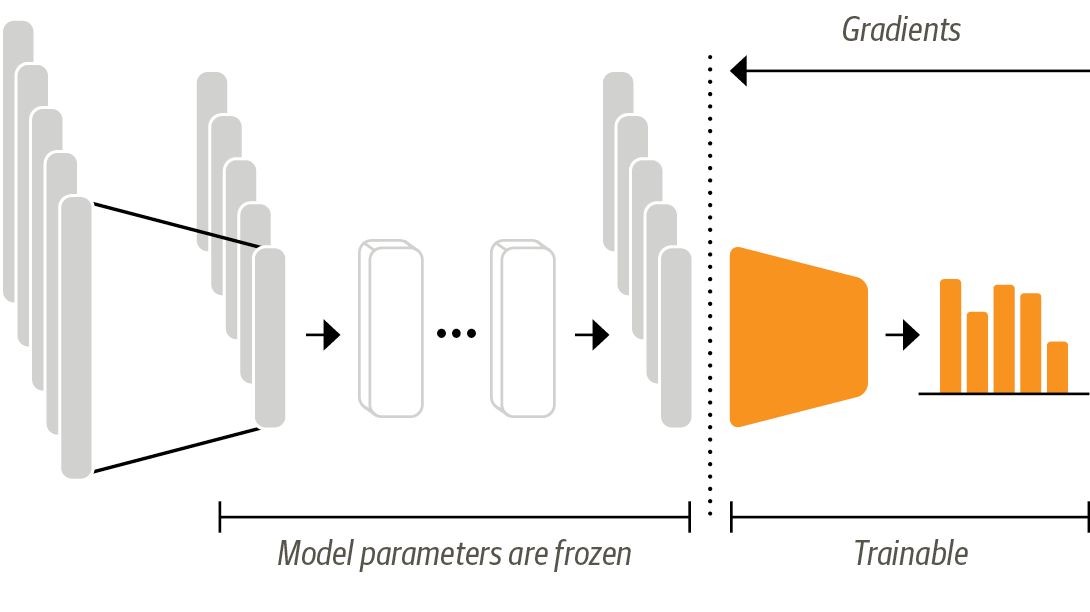
Transfer Learning via Finetuning¶
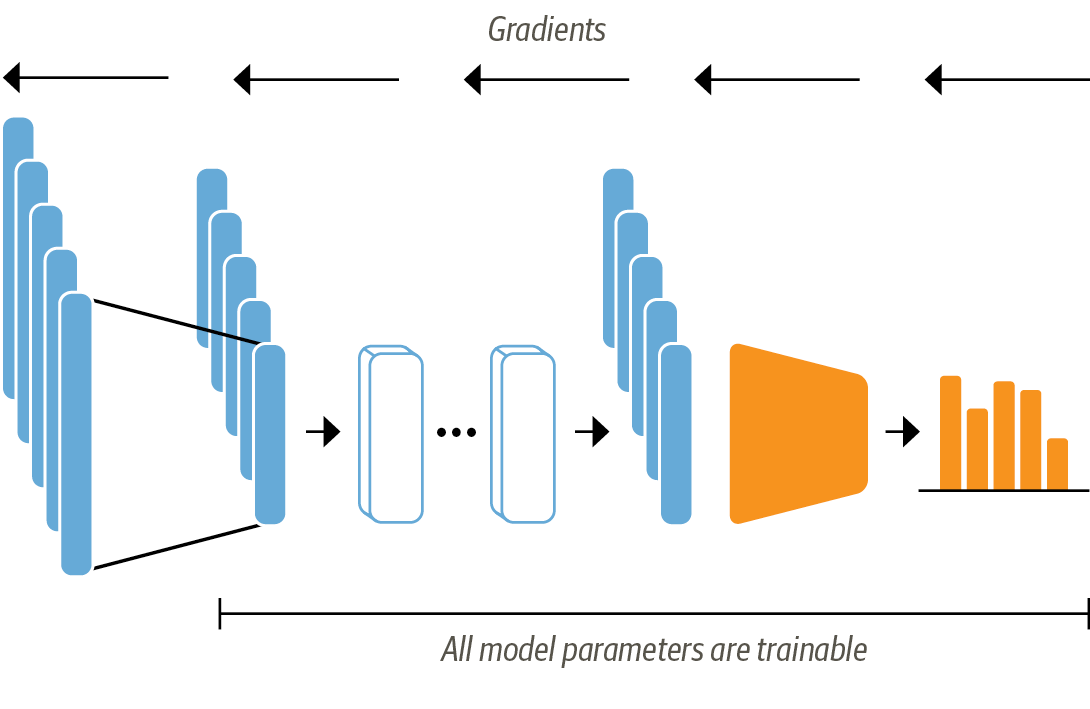
In [ ]:
tokenizer = DistilBertTokenizer.from_pretrained(model_checkpoint)
In [ ]:
tokenizer(["This is a test", "This is another test", "cat"], return_tensors="tf", padding=True, truncation=True)
In [ ]:
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
In [ ]:
tokenized_train_ds = train_ds.map(tokenize, batched=True, batch_size=None)
tokenized_val_ds = emotions['validation'].map(tokenize, batched=True, batch_size=None)
tokenizer_test_ds = emotions['test'].map(tokenize, batched=True, batch_size=None)
In [ ]:
BATCH_SIZE = 64
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_train_dataset = tokenized_train_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=True, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
tf_val_dataset = tokenized_val_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=False, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
tf_test_dataset = tokenizer_test_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=False, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
In [ ]:
for i in tf_train_dataset.take(1):
print(i)
In [ ]:
model = TFDistilBertForSequenceClassification.from_pretrained(model_checkpoint,
num_labels=train_ds.features['label'].num_classes)
In [64]:
%load_ext tensorboard
%tensorboard --logdir /tf/model/logs --host 0.0.0.0
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
In [ ]:
from transformers.keras_callbacks import PushToHubCallback
from tensorflow.keras.callbacks import TensorBoard
tensorboard_callback = TensorBoard(log_dir="./model/logs")
push_to_hub_callback = PushToHubCallback(
output_dir="./model",
tokenizer=tokenizer,
hub_model_id=f"{model_checkpoint}-finetuned-tweet-sentiment",
)
callbacks = [tensorboard_callback, push_to_hub_callback]
In [ ]:
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=tf.metrics.SparseCategoricalAccuracy()
)
In [ ]:
history = model.fit(tf_train_dataset, validation_data=tf_val_dataset, epochs=5, callbacks=callbacks)
In [ ]:
_, accuracy = model.evaluate(tf_test_dataset)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
In [ ]:
p = pipeline("text-classification", model='cakiki/distilbert-base-uncased-finetuned-tweet-sentiment', device=-1)
In [ ]:
p("I am terrified")
In [ ]:
emotions['train'].features
In [ ]:
import gradio as gr
gr.Interface.load("huggingface/cakiki/distilbert-base-uncased-finetuned-tweet-sentiment").launch(share=True);
(Re)sources

In [ ]: