Parsing¶
- Syntactic constituency
- Syntactic dependencies
- Parsing algorithms
- Evaluation
Syntactic constituency¶
Reminder: parts of speech (POS)¶
Parts of speech categorise the syntactic function of words.
| Tag | Example | |
|---|---|---|
| CC | Coordinating conjunction | and |
| CD | Cardinal number | 1 |
| DT | Determiner | the |
| EX | Existential there | there |
| FW | Foreign word | שלום |
| IN | Preposition or subordinating conjunction | in |
| JJ | Adjective | high |
| JJR | Adjective, comparative | higher |
| JJS | Adjective, superlative | highest |
| LS | List item marker | , |
| MD | Modal | can |
| NN | Noun, singular or mass | desk |
| NNS | Noun, plural | desks |
| NNP | Proper noun, singular | Denmark |
| NNPS | Proper noun, plural | Danes |
| PDT | Predeterminer | both |
| POS | Possessive ending | 's |
| PRP | Personal pronoun | you |
| PRP$ | Possessive pronoun | your |
| RB | Adverb | well |
| RBR | Adverb, comparative | better |
| RBS | Adverb, superlative | best |
| RP | Particle | |
| SYM | Symbol | |
| TO | to | |
| UH | Interjection | |
| VB | Verb, base form | see |
| VBD | Verb, past tense | saw |
| VBG | Verb, gerund or present participle | seeing |
| VBN | Verb, past participle | seen |
| VBP | Verb, non-3rd person singular present | see |
| VBZ | Verb, 3rd person singular present | sees |
| WDT | Wh-determiner | |
| WP | Wh-pronoun | |
| WP$ | Possessive wh-pronoun | |
| WRB | Wh-adverb |
Syntactic constituents¶
Phrases also have a grammatical function when they are syntactic constituents.
Penn Treebank constituent tagset:
| Phrase Level | Example | |
|---|---|---|
| ADJP | Adjective Phrase | really high |
| ADVP | Adverb Phrase | very well |
| CONJP | Conjunction Phrase | as well as |
| FRAG | Fragment | |
| INTJ | Interjection | |
| LST | List marker | |
| NP | Noun Phrase | high desk |
| PP | Prepositional Phrase | at home |
| PRN | Parenthetical | |
| PRT | Particle. Category for words that should be tagged RP | |
| QP | Quantifier Phrase (i.e. complex measure/amount phrase); used within NP | |
| RRC | Reduced Relative Clause | |
| VP | Verb Phrase | see the desk |
| WHADJP | Wh-adjective Phrase. Adjectival phrase containing a wh-adverb | how hot |
| WHAVP | Wh-adverb Phrase, containing a wh-adverb | how well |
| WHNP | Wh-noun Phrase, containing some wh-word | which book |
| WHPP | Wh-prepositional Phrase, containing a wh-noun phrase | of which |
| X | Unknown, uncertain, or unbracketable. |
| Clause Level | ||
|---|---|---|
| S | simple declarative clause, i.e. one that is not introduced by a (possible empty) subordinating conjunction or a wh-word and that does not exhibit subject-verb inversion. | |
| SBAR | Clause introduced by a (possibly empty) subordinating conjunction. | |
| SBARQ | Direct question introduced by a wh-word or a wh-phrase. Indirect questions and relative clauses should be bracketed as SBAR, not SBARQ. | |
| SINV | Inverted declarative sentence, i.e. one in which the subject follows the tensed verb or modal. | |
| SQ | Inverted yes/no question, or main clause of a wh-question, following the wh-phrase in SBARQ. |
Trees¶
A tree is a connected acyclic undirected graph.
Graphs consist of nodes and edges between them.

Syntactic constituency trees (phrase structure trees)¶
- Nodes: syntactic constituents, labeled by type (including individual words, labeled by POS).
- Edges: connecting phrases to their constituents, unlabeled.

 |
 |
Another example of a PP attachment problem: does the PP (prepositional phrase) attach to the VP (verbal phrase) or the NP (noun phrase)?

Treebanks¶
A dataset that consists of a text corpus with annotated (syntactic) trees.
Some commonly used treebanks:
- English: Penn Treebank (4.8 million words)
- Mandarin Chinese: Chinese Treebank (1.5 million words)
- German: TIGER (0.9 million words), TüBa-D/Z (1.6 million words)
- Czech: Prague Dependency Treebank (2 million words)
- Danish: Arboretum (0.2 million words)
- ...
- Multilingual: Universal Dependencies (more in a few slides)
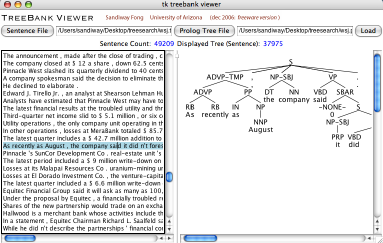
Constituency parsers¶
Structured prediction: trained on treebanks to build constituency trees from text.
See more in the chapter from this book about constituency parsing (slides).

Syntactic dependencies¶
Motivation: information extraction¶
In relation extraction, it helps to define linguistic patterns such as <subject> <verb> <object> instead of purely text-based patterns.
Dechra Pharmaceuticals, which has just made its second acquisition, had previously purchased Genitrix.
Trinity Mirror plc, the largest British newspaper, purchased Local World, its rival.
Kraft, owner of Milka, purchased Cadbury Dairy Milk and is now gearing up for a roll-out of its new brand.
Syntactic dependencies are a useful representation for this purpose.

Motivation: machine translation¶
Reordering rules can be stated in terms of syntactic dependencies:

Syntactic dependency trees¶
- Nodes: individual words, and a special
ROOTnode. - Edges (arcs): labeled syntactic relations between words: from head to dependent.
Must be a tree: every word has exactly one head, and ROOT has no head.
conllu = """
# ID FORM LEMMA UPOS XPOS FEATS HEAD DEPREL DEPS MISC
1 I _ _ _ _ 2 nsubj _ _
2 saw _ _ _ _ 0 root _ _
3 the _ _ _ _ 4 det _ _
4 star _ _ _ _ 2 dobj _ _
5 with _ _ _ _ 7 case _ _
6 the _ _ _ _ 7 det _ _
7 telescope _ _ _ _ 2 obl _ _
"""
arcs, tokens = to_displacy_graph(*load_arcs_tokens(conllu))
render_displacy(arcs, tokens,"2400px")
Syntactic ambiguity¶
conllu = """
# ID FORM LEMMA UPOS XPOS FEATS HEAD DEPREL DEPS MISC
1 I _ _ _ _ 2 nsubj _ _
2 saw _ _ _ _ 0 root _ _
3 the _ _ _ _ 4 det _ _
4 star _ _ _ _ 2 dobj _ _
5 with _ _ _ _ 7 case _ _
6 the _ _ _ _ 7 det _ _
7 telescope _ _ _ _ 2 obl _ _
"""
arcs, tokens = to_displacy_graph(*load_arcs_tokens(conllu))
render_displacy(arcs, tokens,"2400px")
conllu = """
# ID FORM LEMMA UPOS XPOS FEATS HEAD DEPREL DEPS MISC
1 I _ _ _ _ 2 nsubj _ _
2 saw _ _ _ _ 0 root _ _
3 the _ _ _ _ 4 det _ _
4 star _ _ _ _ 2 dobj _ _
5 with _ _ _ _ 7 case _ _
6 the _ _ _ _ 7 det _ _
7 telescope _ _ _ _ 4 nmod _ _
"""
arcs, tokens = to_displacy_graph(*load_arcs_tokens(conllu))
render_displacy(arcs, tokens,"2400px")
 |
 |
CoNLL-U format¶
Tabular format with 10 columns indicating various morphosyntactic attributes.
Shown here: ID, surface form, dependency head and dependency relation.
(The others are shown as _ but normally they would be filled in too.)
display(HTML(pd.read_csv(StringIO(conllu), sep="\t").to_html(index=False)))
render_displacy(arcs, tokens,"2400px")
| # ID | FORM | LEMMA | UPOS | XPOS | FEATS | HEAD | DEPREL | DEPS | MISC |
|---|---|---|---|---|---|---|---|---|---|
| 1 | I | _ | _ | _ | _ | 2 | nsubj | _ | _ |
| 2 | saw | _ | _ | _ | _ | 0 | root | _ | _ |
| 3 | the | _ | _ | _ | _ | 4 | det | _ | _ |
| 4 | star | _ | _ | _ | _ | 2 | dobj | _ | _ |
| 5 | with | _ | _ | _ | _ | 7 | case | _ | _ |
| 6 | the | _ | _ | _ | _ | 7 | det | _ | _ |
| 7 | telescope | _ | _ | _ | _ | 4 | nmod | _ | _ |
Need for universal syntactic annotation¶
How to define the relation labels? There are different linguistic traditions in different languages...

Universal Dependencies¶
- Annotation framework featuring 37 syntactic relations
- Treebanks in over 130 languages
- Large project with over 500 contributors
- Cross-linguistically consistent annotation of typologically diverse languages (de Marneffe et al., 2021)

UD dependency relations¶
| Nominals | Clauses | Modifier words | Function Words | |
| Core arguments |
nsubj obj iobj |
csubj ccomp xcomp |
||
| Non-core dependents |
obl vocative expl dislocated |
advcl |
advmod discourse |
aux cop mark |
| Nominal dependents |
nmod appos nummod |
acl | amod |
det clf case |
| Coordination | MWE | Loose | Special | Other |
|
conj cc |
fixed flat compound |
list parataxis |
orphan goeswith reparandum |
punct root dep |
Beyond dependency trees¶
UD also includes other morphosyntactic annotation:
- Tokenisation and word segmentation
- Morphological features (e.g., lemmas, case, gender)
- Universal part of speech tags (UPOS): coarse abstraction over language-specific POS tags (XPOS).
| Open class words | Closed class words | Other |
|---|---|---|
| ADJ | ADP | PUNCT |
| ADV | AUX | SYM |
| INTJ | CCONJ | X |
| NOUN | DET | |
| PROPN | NUM | |
| VERB | PART | |
| PRON | ||
| SCONJ |
Danish UD example¶
the big fish ate the small fish
conllu = """
# ID FORM LEMMA UPOS XPOS FEATS HEAD DEPREL DEPS MISC
1 Den _ _ _ _ 3 det _ _
2 store _ _ _ _ 3 amod _ _
3 fisk _ _ _ _ 4 nsubj _ _
4 spiste _ _ _ _ 0 root _ _
5 den _ _ _ _ 7 det _ _
6 lille _ _ _ _ 7 amod _ _
7 fisk _ _ _ _ 4 obj _ _
"""
arcs, tokens = to_displacy_graph(*load_arcs_tokens(conllu))
render_displacy(arcs, tokens,"1400px")
Korean UD example¶
big fish small fish ate
conllu = """
# ID FORM LEMMA UPOS XPOS FEATS HEAD DEPREL DEPS MISC
1 큰 _ _ _ _ 2 amod _ _
2 물고기가 _ _ _ _ 5 nsubj _ _
3 작은 _ _ _ _ 4 amod _ _
4 물고기를 _ _ _ _ 5 obj _ _
5 먹었다 _ _ _ _ 0 root _ _
"""
arcs, tokens = to_displacy_graph(*load_arcs_tokens(conllu))
render_displacy(arcs, tokens,"1400px")

Dependency parsing¶
Task:
- Predict head and relation for each word.
- Classification? Sequence tagging? Sequence-to-sequence? Span selection? Or something else?
conllu = """
# ID FORM LEMMA UPOS XPOS FEATS HEAD DEPREL DEPS MISC
1 Alice _ _ _ _ 2 nsubj _ _
2 saw _ _ _ _ 0 root _ _
3 Bob _ _ _ _ 2 dobj _ _
"""
display(HTML(pd.read_csv(StringIO(conllu), sep="\t").to_html(index=False)))
| # ID | FORM | LEMMA | UPOS | XPOS | FEATS | HEAD | DEPREL | DEPS | MISC |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Alice | _ | _ | _ | _ | 2 | nsubj | _ | _ |
| 2 | saw | _ | _ | _ | _ | 0 | root | _ | _ |
| 3 | Bob | _ | _ | _ | _ | 2 | dobj | _ | _ |
Dependency parsing approaches¶
- Graph-based: score all possible word pairs, find best combination (often a maximum spanning tree). Examples:
- Transition-based: incrementally build the tree, one arc at a time, by applying a sequence of actions. Examples:

Dependency parsing evaluation¶
- Unlabeled Attachment Score (UAS): % of words with correct head
- Labeled Attachment Score (LAS): % of words with correct head and label
Always 0 $\leq$ LAS $\leq$ UAS $\leq$ 100%.

Transition-based parsers¶
Consist of a buffer and stack, incrementally build the parse by applying actions (transitions).

Configuration¶
- Stack $S$: a last-in, first-out memory to keep track of words to process
- Buffer $B$: words remaining to be processed
- Arcs $A$: the dependency arcs created so far in the parse tree
What are the possible actions? Depends which transition system we are using!
Common transition systems:
- arc-standard (Nivre, 2003)
- arc-eager (Nivre, 2004)
- arc-hybrid (Kuhlmann et al., 2011)
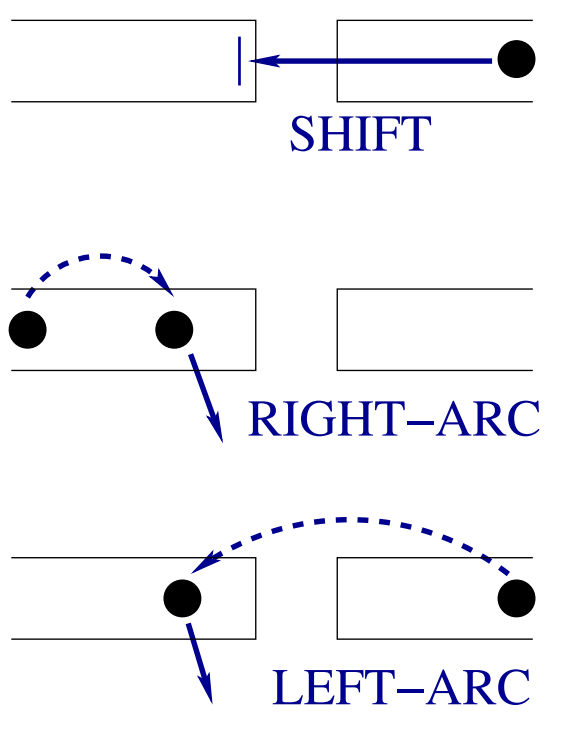
arc-standard¶
Possible actions at each step:
- SHIFT: move the buffer top item to the stack.
- For each relation $r$,
- RIGHT-ARC-$r$: create $r$ arc from second stack item to stack top. Then pop stack top.
- LEFT-ARC-$r$: create $r$ arc from stack top to second stack item. Then pop second stack item.
Two special configurations:
- initial: buffer contains the words, stack contains root, and arcs are empty.
- terminal: buffer is empty, stack contains only root.
arc-standard example¶
render_transitions_displacy(transitions, tokenized_sentence)
| stack | buffer | parse | action |
| ROOT | Alice saw Bob | ||
| ROOT Alice | saw Bob | shift | |
| ROOT Alice saw | Bob | shift | |
| ROOT saw | Bob | leftArc-nsubj | |
| ROOT saw Bob | shift | ||
| ROOT saw | rightArc-dobj | ||
| ROOT | rightArc-root | ||
| ROOT |
Transition-based parsing as structured prediction¶
Model $p(a|c)$: how likely is action $a$ to be next, given that the current configuration is $c$? $$p(a|c) \approx s_\params(a,c)$$
Training: learn $\params$ with an annotated training set $$ \argmax_\params \prod_{x \in \train} \prod_{i=1}^{|x|} s_\params(a_i,c_i) $$
Decoding: try to find the most likely action sequence $$\argmax_{a_1,\ldots,a_{|x|}} \prod_{i=1}^{|x|} s_\params(a_i,c_i)$$

Sequence-to-sequence, but with control structure:

Example neural transition classifiers¶
- Each step is a new classification instance, with word embedding features (Chen and Manning, 2014)
- Stack-LSTM: recurrent state updated across steps (Dyer et al., 2015)
- Each step is a new classification instance, with BiLSTM features (Kiperwasser and Goldberg, 2016)
- Stack-pointer: global attention to select attachment (Ma et al., 2018)
- Stack-transformer: self-attention for state representation (Fernandez Astudillo et al., 2020)

Training¶
- Loss function: often negative log-likelihood or max-margin
- Teacher forcing: always choose the ground truth action.
Alternative: (see also MT slides)
- Scheduled sampling: with a certain probability, use model predictions instead.
But what is the ground truth? Treebanks contain trees, not action sequences!
Oracle: rules to select the right action given the configuration and the correct tree.

Decoding¶
- Greedy decoding:
- Always pick the most likely action (according to the classifier)
- Continue applying more actions until a terminal configuration is reached
- Beam search:
- Maintains a list of top-$k$ action+configuration sequences in a beam
arc-hybrid¶
- SHIFT: move the buffer top item to the stack.
- RIGHT-ARC-$r$: create $r$ arc from second stack item to stack top. Then pop stack top.
- LEFT-ARC-$r$: create $r$ arc from buffer top to stack top. Then pop stack top.
- initial: buffer contains the words followed by root, stack is empty, and arcs are empty.
- terminal: buffer contains only root, stack is empty.
arc-hybrid example¶
Unlabeled parsing (without relation labels), just for simplicity.
Summary: arc-hybrid vs arc-standard¶
| LEFT-ARC | initial configuration | terminal configuration | |
|---|---|---|---|
| arc-standard | create arc from stack top to second stack item, pop second stack item |
stack contains root, buffer contains words |
stack contains root, buffer is empty |
| arc-hybrid | create arc from buffer top to stack top, pop stack top |
stack is empty, buffer contains words and root |
stack is empty, buffer contains root |
(arc-hybrid)Summary¶
- Dependency parsing predicts word-to-word dependencies
- Treebanks in many languages, thanks to UD
- Fast and accurate parsing, e.g. transition-based