< Optimization | Modules | CNN & LSTM >¶
PyTorch Modules¶
What is this notebook about?¶
In this notebook, we will learning about PyTorch modules and the great functionalities they provide. Later on, we'll create a small a multilayer perceptron to perform image classification on MNIST.
Google Colab only!¶
# execute only if you're using Google Colab
!wget -q https://raw.githubusercontent.com/ahug/amld-pytorch-workshop/master/binder/requirements.txt -O requirements.txt
!pip install -qr requirements.txt
import torch
import torch.nn as nn
print("Torch version:", torch.__version__)
import matplotlib.pyplot as plt
In PyTorch, there are many predefined layer like Convolutions, RNN, Pooling, Linear, etc.
These functions are wrapped in modules and inherit from the torch.nn.Module base class.
When designing a custom model in PyTorch, you should follow this strategy and derive your class from torch.nn.Module.
Modules¶
print(torch.nn.Module.__doc__)
Modules are doing a lot of "magic" under the hood.¶
- It registers all the parameters of your model.
- It simplifies the saving/loading of your model.
- It provides helper functions to reset/freeze/update the gradients.
- It provides helper functions to put all parameters on a device (GPU).
What is a torch.nn.Parameter?¶
A Parameter is a Tensor with requires_grad to True by default, and which is automatically added to the list of parameters when used within a model.
Let's have a look at the documentation (torch.nn.Paramter)
print(torch.nn.Parameter.__doc__)
mod = nn.Conv1d(10, 2, 3)
print(mod.weight)
Very simple example of a module¶
A module has to implement two functions:
- the
__init__function, where you define all the layers that have learnable parameters. In the__init__function, you are just specifying each layer and not how it is connected to others, so it does not need to be in order of execution. Since your model's submodules and parameters are instantiated in the__init__function, PyTorch knows that they exist and registers them.
Also, don't forget to always call the super() method.
- the
forwardfunction, which is the method that defines what has to be executed during the forward pass and especially how the layers are connected. This is where you call the layers that you defined inside the__init__function.
# A simple module
class MySuperSimpleModule(nn.Module):
def __init__(self, input_size, num_classes):
super(MySuperSimpleModule, self).__init__() # Mandatory call to super
self.linear = nn.Linear(input_size, num_classes) # Define one Linear layer
def forward(self, x):
out = self.linear(x)
return out
You can use the print function to list a model's submodules and parameters defined inside init:
model = MySuperSimpleModule(input_size=20, num_classes=5)
print(model)
You can use model.parameters() to get the list of parameters of your model automatically inferred by PyTorch.
for name, p in model.named_parameters(): # Here we use a sligtly different version of the parameters() function
print(name, ":\n", p) # which also returns the parameter name
Simple network for image classification¶

Your turn!¶
Let's create a more complicated model.¶
Implement a simple multilayer perceptron with two hidden layers and the following structure:
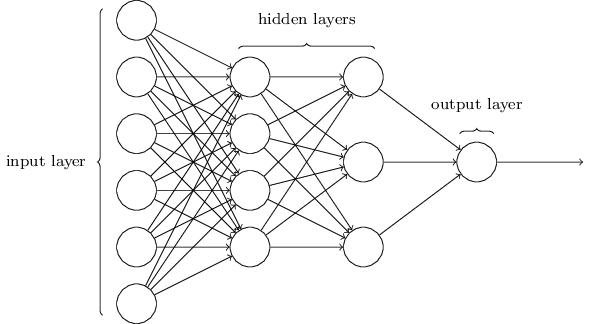
- Input-size: input_size
- 1st hidden layer: 75
- 2nd hidden layer: 50
- Output layer: num_classes
Additionally, we use ReLUs as activation functions.
You will need some PyTorch NN modules - Find them in the PyTorch doc (especially nn.Linear)!
from torch.nn import Parameter
import torch.nn.functional as F # provides some helper functions like Relu's, Sigmoids, Tanh, etc.
class MyMultilayerPerceptron(nn.Module):
def __init__(self, input_size, num_classes):
super(MyMultilayerPerceptron, self).__init__()
self.input_size = input_size
self.num_classes = num_classes
self.linear_1 = nn.Linear(input_size, 75)
self.linear_2 = # <YOUR CODE>
self.linear_3 = nn.Linear(50, num_classes)
def forward(self, x):
out = F.relu(self.linear_1(x))
out = # <YOUR CODE>
out = # <YOUR CODE>
return out
Print your network's parameters¶
model = MyMultilayerPerceptron(784, 10)
print(model)
Feed an input to your network¶
x = torch.rand(16, 784) # the first dimension is reserved for the 'batch_size'
out = model(x) # equivalent to model.forward(x)
out[0, :]
Training a model¶
Most of the functions to train a model follow a similar pattern in PyTorch. In most of the cases in consists of the following steps:
- Loop over data (in batches)
- Forward pass
- Zero gradients!
- Backward pass
- Parameter update (Optimizer)
def train(model, num_epochs, data_loader, device):
model = model.to(device)
# Define the Loss function and Optimizer that you want to use
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # NOTE: model.parameters()
# Outter training loop
for epoch in range(num_epochs):
# Inner training loop
cum_loss = 0
for (inputs, labels) in data_loader:
# Prepare inputs and labels for processing by the model (e.g. reshape, move to device, ...)
inputs = inputs.to(device)
labels = labels.to(device)
# original shape is [batch_size, 28, 28] because it's an image of size 28x28
inputs = inputs.view(-1, 28*28)
# Do Forward -> Loss Computation -> Backward -> Optimization
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
cum_loss += loss.item()
print("Epoch %d, Loss=%.4f" % (epoch+1, cum_loss/len(train_loader)))
Note:
- we can use the
.tofunction on the model directly. Indeed, since PyTorch knows all the model parameters, it can put all the parameters on the correct device. - we use
model.parameters()to get all the parameters of the model and we can instantiate an optimizer that will optimize these parameterstorch.optim.SGD(model.parameters()). - to apply the forward function of the module, we write
model(input). In most cases,model.forward(inputs)would also work, but there is a slight difference : PyTorch allows you to register hook functions for a model that are automatically called when you do a forward pass on your model. Usingmodel(input)will call these hooks and then call the forward function, while usingmodel.forward(inputs)will just silently ignore them.
Do you feel the power of Modules ?
Loss functions¶
PyTorch comes with a lot of predefined loss functions :
- L1Loss
- MSELoss
- CrossEntropyLoss
- NLLLoss
- PoissonNLLLoss
- KLDivLoss
- BCELoss
- MarginRankingLoss
- HingeEmbeddingLoss
- MultiLabelMarginLoss
- CosineEmbeddingLoss
- TripletMarginLoss
- ...
Check out the PyTorch Documentation.
Let's train our model on the MNIST digit classification task¶

First, we have to load the training and test images. MNIST is a widely used dataset, therefore the torchvision package provides simple functionalities to load images from it.
import torchvision.datasets as datasets
import torchvision.transforms as transforms
batch_size = 64
# MNIST Dataset (Images and Labels)
train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
# Dataset Loader (Input Batcher)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
In PyTorch, Dataset and Dataloaders are classes that can help to quickly define how to access and iterate over your data. This is specially interesting when your data is distributed over several files (for instance, if you have several images in some directory structure).
Call the actual training function¶
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MyMultilayerPerceptron(input_size=784, num_classes=10)
num_epochs = 5
train(model, num_epochs, train_loader, device)
How can we now assess the model's performance?¶
This function loops over another data_loader (usually containing test/validation data) and computes the model's accuracy on it.
def accuracy(model, data_loader, device):
with torch.no_grad(): # during model evaluation, we don't need the autograd mechanism (speeds things up)
correct = 0
total = 0
for inputs, labels in data_loader:
inputs = inputs.to(device)
inputs = inputs.view(-1, 28*28)
outputs = model(inputs)
_, predicted = outputs.max(1)
correct += (predicted.cpu() == labels).sum().item()
total += labels.size(0)
acc = correct / total
return acc
accuracy(model, test_loader, device) # look at: accuracy(model, train_loader, device)
We get an accuracy of ~97.9%, can we do better?¶
How can we now store our trained model?¶
torch.save(model, "my_model.pt")
my_model_loaded = torch.load("my_model.pt")
model.linear_3.bias, my_model_loaded.linear_3.bias
This intro to modules used this medium post as a resource.
Don't forget to download the notebook, otherwise your changes may be lost!¶
