Regression¶
Preliminaries¶
- Goal
- Introduction to Bayesian (Linear) Regression
- Materials
- Mandatory
- These lecture notes
- Optional
- Bishop pp. 152-158
- In this and forthcoming lectures, we will make use of some elementary matrix calculus. The most important formulas are summarized at the bottom of this notebook in an OPTIONAL SLIDE on matrix calculus.
- Mandatory
Regression - Illustration¶

Given a set of (noisy) data measurements, find the 'best' relation between an input variable $x \in \mathbb{R}^D$ and input-dependent outcomes $y \in \mathbb{R}$
Regression vs Density Estimation¶
- Observe $N$ IID data pairs $D=\{(x_1,y_1),\dotsc,(x_N,y_N)\}$ with $x_n \in \mathbb{R}^M$ and $y_n \in \mathbb{R}$.
- Assume that we are interested in (a model for) the responses $y_n$ for given inputs $x_n$?, I.o.w. we are interested in building a model for the conditional distribution $p(y|x)$.
- Note that, since $p(x,y)=p(y|x)\, p(x)$, building a model $p(y|x)$ is similar to density estimation with the assumption that $x$ is drawn from a uniform distribution.
Bayesian Linear Regression¶
- Next, we discuss (1) model specification, (2) Inference and (3) a prediction application for a Bayesian linear regression problem.
1. Model Specification¶
In a regression model, we try to 'explain the data' by a purely deterministic term $f(x_n,w)$, plus a purely random term $\epsilon_n$ for 'unexplained noise',
$$ y_n = f(x_n,w) + \epsilon_n $$
- In a linear regression model, i.e., linear w.r.t. the parameters $w$, we assume that
where $\phi_j(x)$ are called basis functions.
- For notational simplicity, from now on we will assume $f(x_n,w) = w^T x_n$, with $x_n \in \mathbb{R}^M$.
- In ordinary linear regression , the noise process $\epsilon_n$ is zero-mean Gaussian with constant variance, i.e.
- Hence, given a data set $D=\{(x_1,y_1),\dotsc,(x_N,y_N)\}$, the likelihood for an ordinary linear regression model is
where $w = \left(\begin{matrix} w_1 \\ w_2 \\ \vdots \\ w_{M} \end{matrix} \right)$, the $(N\times M)$-dim matrix $\mathbf{X} = \left(\begin{matrix}x_1^T \\ x_2^T \\ \vdots \\ x_N^T \end{matrix} \right) = \left(\begin{matrix}x_{11},x_{12},\dots,x_{1M}\\ x_{21},x_{22},\dots,x_{2M} \\ \vdots \\ x_{N1},x_{N2},\dots,x_{NM} \end{matrix} \right) $ and $y = \left(\begin{matrix} y_1 \\ y_2 \\ \vdots \\ y_N \end{matrix} \right)$.
- For full Bayesian learning we should also choose a prior $p(w)$:
- For simplicity, we will assume that $\alpha$ and $\beta$ are known.
2. Inference¶
- We'll do Bayesian inference for the parameters $w$.
with natural parameters (see the natural parameterization of Gaussian):
$$\begin{align*} \eta_N &= \beta\mathbf{X}^Ty \\ \Lambda_N &= \beta \mathbf{X}^T\mathbf{X} + \alpha \mathbf{I} \end{align*}$$- Or equivalently (in the moment parameterization of the Gaussian):
- Note that B-3.53 and B-3.54 combine to
- (Bishop Fig.3.7) Illustration of sequential Bayesian learning for a simple linear model of the form $y(x, w) =
w_0 + w_1 x$. (Bishop Fig.3.7, detailed description at Bishop, pg.154.)

3. Application: predictive distribution¶
- Assume we are interested in the distribution $p(y_\bullet \,|\, x_\bullet, D)$ for a new input $x_\bullet$. This can be worked out as (exercise B-3.10)
with $$\begin{align*} \sigma_N^2(x_\bullet) = \beta^{-1} + x^T_\bullet S_N x_\bullet \tag{B-3.59} \end{align*}$$
- So, the uncertainty $\sigma_N^2(x_\bullet)$ about the output contains comprises both uncertainty about the process ($\beta^{-1}$) and about the model parameters ($x^T_\bullet S_N x_\bullet$).
Example Predictive Distribution¶
- As an example, let's do Bayesian Linear Regression for a synthetic sinusoidal data set and a model with 9 Gaussian basis functions

- The predictive distributions for $y$ are shown in the following plots (Bishop, Fig.3.8)
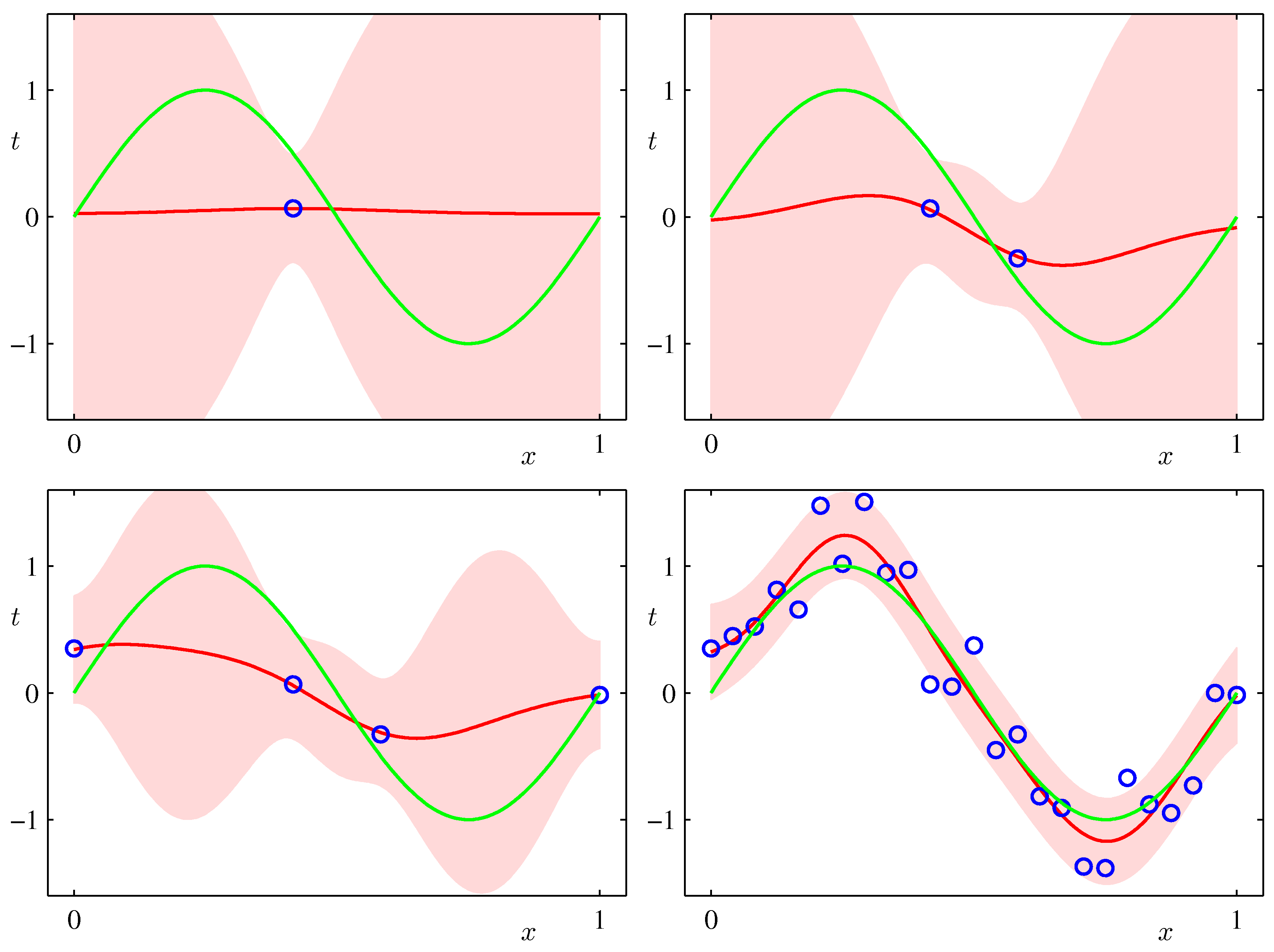
- And some plots of draws of posteriors for the functions $w^T \phi(x)$ (Bishop, Fig.3.9)

Maximum Likelihood Estimation for Linear Regression Model¶
- Recall the posterior mean for the weight vector
where $\alpha$ is the prior precision for the weights.
- The Maximum Likelihood solution for $w$ is obtained by letting $\alpha \rightarrow 0$, which leads to
- The matrix $\mathbf{X}^\dagger \equiv (\mathbf{X}^T \mathbf{X})^{-1}\mathbf{X}^T$ is also known as the Moore-Penrose pseudo-inverse (which is sort-of-an-inverse for non-square matrices).
- Note that if we have fewer training samples than input dimensions, i.e., if $N<M$, then $\mathbf{X}^T \mathbf{X}$ will not be invertible and maximum likelihood blows up. The Bayesian solution does not suffer from this problem.
Least-Squares Regression¶
- (You may say that) we don't need to work with probabilistic models. E.g., there's also the deterministic least-squares solution: minimize sum of squared errors,
- Setting the gradient
$ \frac{\partial \left( {y - \mathbf{X}w } \right)^T \left( {y - \mathbf{X}w } \right)}{\partial w} = -2 \mathbf{X}^T \left(y - \mathbf{X} w \right) $ to zero yields the so-called normal equations $\mathbf{X}^T\mathbf{X} \hat w_{\text{LS}} = \mathbf{X}^T y$ and consequently
$$ \hat w_{\text{LS}} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T y $$which is the same answer as we got for the maximum likelihood weights $\hat w_{\text{ML}}$.
- $\Rightarrow$ Least-squares regression ($\hat w_{\text{LS}}$) corresponds to the (probabilistic) maximum likelihood solution ($\hat w_{\text{ML}}$) if the probabilistic model includes the following assumptions:
- The observations are independently and identically distributed (IID) (this determines how errors are combined), and
- The noise signal $\epsilon_n \sim \mathcal{N}(0,\,\beta^{-1})$ is Gaussian distributed (determines the error metric)
- If you use the Least-Squares method, you cannot see (nor modify) these assumptions. The probabilistic method forces you to state all assumptions explicitly!
Not Identically Distributed Data¶
- Let's do an example regarding changing our assumptions. What if we assume that the variance of the measurement error varies with the sampling index, $\epsilon_n \sim \mathcal{N}(0,\beta_n^{-1})$?
- The likelihood is now (using $\Lambda \triangleq \mathrm{diag}(\beta_n)$ )
- Combining this likelihood with the prior $p(w) = \mathcal{N}(w\,|\,0,\alpha^{-1}\mathbf{I})$ leads to a posterior
with $$\begin{align*} m_N &= S_N \mathbf{X}^T \Lambda y \\ S_N &= \left(\alpha \mathbf{I} + \mathbf{X}^T \Lambda \mathbf{X}\right)^{-1} \end{align*}$$
- And maximum likelihood solution
- This maximum likelihood solution is also called the Weighted Least Squares (WLS) solution. (Note that we just stumbled upon it, the crucial aspect is appropriate model specification!)
- Note also that the dimension of $\Lambda$ grows with the number of data points. In general, models for which the number of parameters grow as the number of observations increase are called non-parametric models.
Code Example: Least Squares vs Weighted Least Squares¶
- We'll compare the Least Squares and Weighted Least Squares solutions for a simple linear regression model with input-dependent noise:
using Pkg;Pkg.activate("probprog/workspace/");Pkg.instantiate();
IJulia.clear_output();
using PyPlot, LinearAlgebra
# Model specification: y|x ~ 𝒩(f(x), v(x))
f(x) = 5*x .- 2
v(x) = 10*exp.(2*x.^2) .- 9.5 # input dependent noise variance
x_test = [0.0, 1.0]
plot(x_test, f(x_test), "k--") # plot f(x)
# Generate N samples (x,y), where x ~ Unif[0,1]
N = 50
x = rand(N)
y = f(x) + sqrt.(v(x)) .* randn(N)
plot(x, y, "kx"); xlabel("x"); ylabel("y") # Plot samples
# Add constant to input so we can estimate both the offset and the slope
_x = [x ones(N)]
_x_test = hcat(x_test, ones(2))
# LS regression
w_ls = pinv(_x) * y
plot(x_test, _x_test*w_ls, "b-") # plot LS solution
# Weighted LS regression
W = Diagonal(1 ./ v(x)) # weight matrix
w_wls = inv(_x'*W*_x) * _x' * W * y
plot(x_test, _x_test*w_wls, "r-") # plot WLS solution
ylim([-5,8]); legend(["f(x)", "D", "LS linear regr.", "WLS linear regr."],loc=2);

OPTIONAL SLIDES ¶
Some Useful Matrix Calculus¶
When doing derivatives with matrices, e.g. for maximum likelihood estimation, it will be helpful to be familiar with some matrix calculus. We shortly recapitulate used formulas here.
- We define the gradient of a scalar function $f(A)$ w.r.t. an $n \times k$ matrix $A$ as
- The following formulas are useful (see Bishop App.-C)
open("../../styles/aipstyle.html") do f
display("text/html", read(f, String))
end