The use of μονογενής (Nestle1904LFT)¶
Work in progress!
1.1 - Why is this relevant? ¶
Back to TOC¶
The Greek word "μονογενής" (monogenēs) is often used in the context of biblical texts, particularly in the New Testament, to describe Jesus Christ. Its precise meaning has been a subject of theological debate, as it can be translated in different ways, such as "only begotten" or "unique" or "one-of-a-kind."
Consider for example John 3:16:
Οὕτως γὰρ ἠγάπησεν ὁ Θεὸς τὸν κόσμον, ὥστε τὸν Υἱὸν τὸν μονογενῆ ἔδωκεν, ἵναπᾶς ὁπι στεύων εἰς αὐτὸν μὴ ἀπόληται ἀλλ’ ἔχῃ ζωὴν αἰώνιον.
The choice of translation can depend on the theological tradition and interpretation of the text. In some translations of the Bible, the word μονογενής in John 3:16 was translated as "only begotten" (e.g., in the King James Version), while others use "one and only" or "unique" to convey the idea of Jesus being unique and special.
See also the entry in Liddel-Scott-Jones Greek-English Lexicon for more lexical details.
1.2 - Translating into Text-Fabric queries ¶
Back to TOC
As the translation of μονογενής depends on the context of the word being used, we first need to search for all occurences of the lemma μονογενής.
2 - Load Text-Fabric app and data ¶
Back to TOC¶
%load_ext autoreload
%autoreload 2
# Loading the Text-Fabric code
# Note: it is assumed Text-Fabric is installed in your environment
from tf.fabric import Fabric
from tf.app import use
# load the N1904 app and data
N1904 = use ("tonyjurg/Nestle1904LFT", version="0.6", hoist=globals())
Locating corpus resources ...
The requested app is not available offline ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/app not found
The requested data is not available offline ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 not found
| 0.21s T otype from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 2.25s T oslots from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.61s T wordunacc from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.63s T unicode from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.48s T verse from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.56s T book from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.48s T chapter from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.49s T after from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.56s T wordtranslit from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.59s T word from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.59s T normalized from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | | 0.06s C __levels__ from otype, oslots, otext | | 1.78s C __order__ from otype, oslots, __levels__ | | 0.07s C __rank__ from otype, __order__ | | 3.31s C __levUp__ from otype, oslots, __rank__ | | 1.93s C __levDown__ from otype, __levUp__, __rank__ | | 0.21s C __characters__ from otext | | 0.94s C __boundary__ from otype, oslots, __rank__ | | 0.05s C __sections__ from otype, oslots, otext, __levUp__, __levels__, book, chapter, verse | | 0.24s C __structure__ from otype, oslots, otext, __rank__, __levUp__, book, chapter, verse | 0.44s T booknumber from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.56s T bookshort from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.48s T case from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.32s T clausetype from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.56s T containedclause from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.42s T degree from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.58s T gloss from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.48s T gn from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.03s T headverse from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.32s T junction from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.55s T lemma from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.50s T lex_dom from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.53s T ln from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.41s T markafter from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.40s T markbefore from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.40s T markorder from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.44s T monad from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.43s T mood from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.51s T morph from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.52s T nodeID from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.48s T nu from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.49s T number from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.43s T person from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.42s T punctuation from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.68s T ref from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.66s T reference from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.48s T roleclausedistance from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.46s T sentence from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.51s T sp from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.51s T sp_full from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.53s T strongs from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.44s T subj_ref from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.43s T tense from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.47s T type from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.44s T voice from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.38s T wgclass from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.34s T wglevel from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.36s T wgnum from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.36s T wgrole from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.34s T wgrolelong from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.40s T wgrule from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.34s T wgtype from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.50s T wordlevel from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.50s T wordrole from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6 | 0.50s T wordrolelong from ~/text-fabric-data/github/tonyjurg/Nestle1904LFT/tf/0.6
Data: tonyjurg - Nestle1904LFT 0.6, Character table, Feature docs
Node types
| Name | # of nodes | # slots / node | % coverage |
|---|---|---|---|
| book | 27 | 5102.93 | 100 |
| chapter | 260 | 529.92 | 100 |
| verse | 7943 | 17.35 | 100 |
| sentence | 8011 | 17.20 | 100 |
| wg | 105430 | 6.85 | 524 |
| word | 137779 | 1.00 | 100 |
Features:
Nestle 1904 (Low Fat Tree)
specified
- apiVersion:
3 - appName:
tonyjurg/Nestle1904LFT appPath:
C:/Users/tonyj/text-fabric-data/github/tonyjurg/Nestle1904LFT/app- commit: no value
- css:
'' dataDisplay:
excludedFeatures:
orig_orderversebookchapter
noneValues:
noneunknown- no value
NA''
- showVerseInTuple:
0 - textFormat:
text-orig-full
docs:
- docBase:
https://github.com/tonyjurg/Nestle1904LFT/blob/main/docs/ - docPage:
about - docRoot:
https://github.com/tonyjurg/Nestle1904LFT featureBase:
https://github.com/tonyjurg/Nestle1904LFT/blob/main/docs/features/<feature>.md
- docBase:
- interfaceDefaults: {fmt:
layout-orig-full} - isCompatible:
True - local: no value
localDir:
C:/Users/tonyj/text-fabric-data/github/tonyjurg/Nestle1904LFT/_tempprovenanceSpec:
- corpus:
Nestle 1904 (Low Fat Tree) - doi:
notyet - org:
tonyjurg - relative:
/tf - repo:
Nestle1904LFT - repro:
Nestle1904LFT - version:
0.6 - webBase:
https://learner.bible/text/show_text/nestle1904/ - webHint:
Show this on the Bible Online Learner website - webLang:
en webUrl:
https://learner.bible/text/show_text/nestle1904/<1>/<2>/<3>- webUrlLex:
{webBase}/word?version={version}&id=<lid>
- corpus:
- release: no value
typeDisplay:
book:
- condense:
True - hidden:
True - label:
{book} - style:
''
- condense:
chapter:
- condense:
True - hidden:
True - label:
{chapter} - style:
''
- condense:
sentence:
- hidden:
0 - label:
#{sentence} (start: {book} {chapter}:{headverse}) - style:
''
- hidden:
verse:
- condense:
True - excludedFeatures:
chapter verse - label:
{book} {chapter}:{verse} - style:
''
- condense:
wg:
- hidden:
0 label:
#{wgnum}: {wgtype} {wgclass} {clausetype} {wgrole} {wgrule} {junction}- style:
''
- hidden:
word:
- base:
True - features:
lemma - featuresBare:
gloss - surpress:
chapter verse
- base:
- writing:
grc
# The following will push the Text-Fabric stylesheet to this notebook (to facilitate proper display with notebook viewer)
N1904.dh(N1904.getCss())
# Set default view in a way to limit noise as much as possible.
N1904.displaySetup(condensed=True, multiFeatures=False, queryFeatures=False)
3 - Performing the queries ¶
Back to TOC¶
3.1 - Rendering of the word μονογενής ¶
Back to TOC¶
The following script gathers all occurrences of the lemma 'μονογενής' and displays its English gloss stored in the TF database. This confirms that the word is interpreted (and translated) differently in different contexts.
count=0
print ('count\t location\t translation')
for node in F.otype.s('word'):
lemma=F.lemma.v(node)
if lemma == 'μονογενής':
count+=1
book=F.book.v(node)
chapter=F.chapter.v(node)
verse=F.verse.v(node)
word=F.word.v(node)
gloss=F.gloss.v(node)
print (count,'\t',book,chapter,':',verse,'\t', gloss)
count location translation 1 Luke 7 : 12 only begotten 2 Luke 8 : 42 an only 3 Luke 9 : 38 an only child 4 John 1 : 14 of an only begotten 5 John 1 : 18 [the] only begotten 6 John 3 : 16 only begotten 7 John 3 : 18 only begotten 8 Hebrews 11 : 17 only begotten son 9 I_John 4 : 9 one and only
3.1.1 - Note 1: The impact of accented Greek Text ¶
Back to TOC¶
If the search was based upon occurances of the occurance of the #surface text word# μονογενής, a different set of results are found. In the example below, the compare is performed on the unaccented word. The importance of this can be seen from the results (i.e. Luke 8 : 42 has μονογενὴς and Luke 9 : 38 μονογενής).
count=0
print ('count\t location\tword \t translation')
for node in F.otype.s('word'):
wordunacc=F.wordunacc.v(node)
if wordunacc == 'μονογενης':
count+=1
book=F.book.v(node)
chapter=F.chapter.v(node)
verse=F.verse.v(node)
word=F.word.v(node)
gloss=F.gloss.v(node)
print (count,'\t',book,chapter,':',verse,'\t', word,'\t', gloss)
count location word translation 1 Luke 7 : 12 μονογενὴς only begotten 2 Luke 8 : 42 μονογενὴς an only 3 Luke 9 : 38 μονογενής an only child 4 John 1 : 18 μονογενὴς [the] only begotten
3.1.2 - Note 2: Alternative method to identify verses ¶
Back to TOC¶
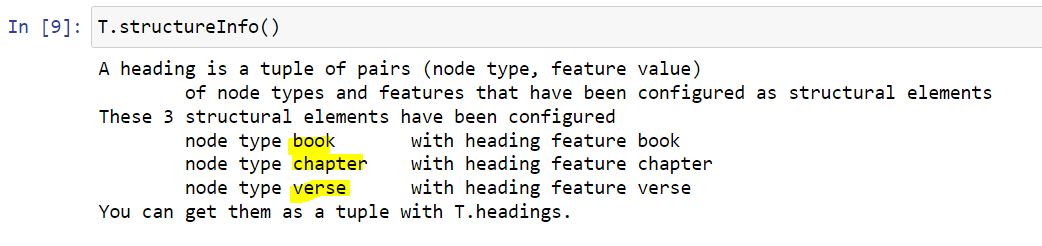
An alternative method to identify the verse where μονογενής is pressent, is to use T.sectionFromNode(node). The resultant tuple structure can be determined from the output of T.structureInfo(). See following image:
3.1.3 - Note 3: Obtaining verse info from otext¶
Back to TOC¶
This is the same info as can be obtained from otext. This will result in the following snippet of code:
for node in F.otype.s('word'):
lemma=F.lemma.v(node)
if lemma == 'μονογενής':
book, chapter, verse = T.sectionFromNode(node)
# Each element on the left hand side corresponds to an element in the tuple.
print (book,chapter,verse)
Luke 7 12 Luke 8 42 Luke 9 38 John 1 14 John 1 18 John 3 16 John 3 18 Hebrews 11 17 I_John 4 9
3.2 - Using show ¶
Back to TOC¶
MonogenesQuery = '''
book
chapter
verse
word lemma=μονογενής
'''
MonogenesResults = N1904.search(MonogenesQuery)
# This will create a list containing ordered tuples consisting of node numbers of the items as they appear in the query
# Just print some of the results
N1904.show(MonogenesResults, start=1, end=1, condensed=True, multiFeatures=False)
0.09s 9 results
verse 1
6 - Required libraries ¶
Back to TOC¶
The scripts in this notebook require (beside text-fabric) the following Python libraries to be installed in the environment:
???
You can install any missing library from within Jupyter Notebook using eitherpip or pip3.