sessionInfo()
R version 4.2.2 (2022-10-31) Platform: x86_64-apple-darwin17.0 (64-bit) Running under: macOS Catalina 10.15.7 Matrix products: default BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib locale: [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8 attached base packages: [1] stats graphics grDevices utils datasets methods base loaded via a namespace (and not attached): [1] fansi_1.0.4 crayon_1.5.2 digest_0.6.31 utf8_1.2.2 [5] IRdisplay_1.1 repr_1.1.5 lifecycle_1.0.3 jsonlite_1.8.4 [9] evaluate_0.20 pillar_1.8.1 rlang_1.0.6 cli_3.6.0 [13] uuid_1.1-0 vctrs_0.5.2 IRkernel_1.3.2 tools_4.2.2 [17] glue_1.6.2 fastmap_1.1.0 compiler_4.2.2 base64enc_0.1-3 [21] pbdZMQ_0.3-9 htmltools_0.5.4
Required R packages¶
library(Matrix)
QR Decomposition¶
We learned Cholesky decomposition as one approach for solving linear regression.
Another approach for linear regression uses the QR decomposition.
This is how thelm()function in R does linear regression.
set.seed(2020) # seed
n <- 5
p <- 3
(X <- matrix(rnorm(n * p), nrow=n)) # predictor matrix
(y <- rnorm(n)) # response vector
# find the (minimum L2 norm) least squares solution
lm(y ~ X - 1)
| 0.3769721 | 0.7205735 | -0.8531228 |
| 0.3015484 | 0.9391210 | 0.9092592 |
| -1.0980232 | -0.2293777 | 1.1963730 |
| -1.1304059 | 1.7591313 | -0.3715839 |
| -2.7965343 | 0.1173668 | -0.1232602 |
- 1.80004311672545
- 1.70399587729432
- -3.03876460529759
- -2.28897494991878
- 0.0583034949929225
Call:
lm(formula = y ~ X - 1)
Coefficients:
X1 X2 X3
0.615118 -0.008382 -0.770116
We want to understand what is QR and how it is used for solving least squares problem.
Definitions¶
Assume $\mathbf{X} \in \mathbb{R}^{n \times p}$ has full column rank. Necessarilly $n \ge p$.
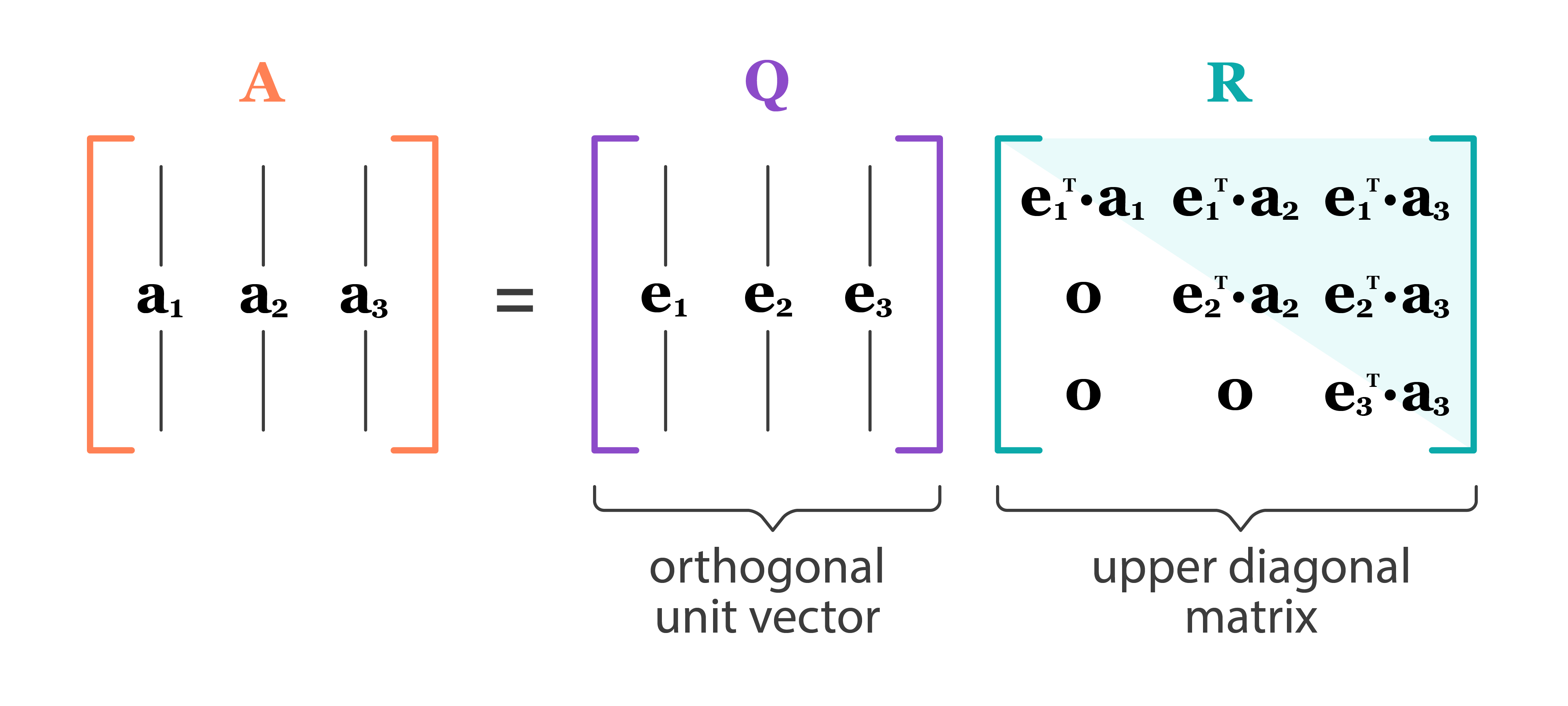
Full QR decomposition:
where
- $\mathbf{Q} \in \mathbb{R}^{n \times n}$, $\mathbf{Q}^T \mathbf{Q} = \mathbf{Q}\mathbf{Q}^T = \mathbf{I}_n$. In other words, $\mathbf{Q}$ is an orthogonal matrix.
- First $p$ columns of $\mathbf{Q}$ form an orthonormal basis of ${\cal R}(\mathbf{X})$ (range or column space of $\mathbf{X}$)
- Last $n-p$ columns of $\mathbf{Q}$ form an orthonormal basis of ${\cal N}(\mathbf{X}^T)$ (null space of $\mathbf{X}^T$)
- Recall that $\mathcal{N}(\mathbf{X}^T)=\mathcal{R}(\mathbf{X})^{\perp}$ and $\mathcal{R}(\mathbf{X}) \oplus \mathcal{N}(\mathbf{X}^T) = \mathbb{R}^n$.
- $\mathbf{R} \in \mathbb{R}^{n \times p}$ is upper triangular with positive diagonal entries.
- The lower $(n-p)\times p$ block of $\mathbf{R}$ is $\mathbf{0}$ (why?).
- Reduced QR decomposition:
where - $\mathbf{Q}_1 \in \mathbb{R}^{n \times p}$, $\mathbf{Q}_1^T \mathbf{Q}_1 = \mathbf{I}_p$. In other words, $\mathbf{Q}_1$ is a partially orthogonal matrix. Note $\mathbf{Q}_1\mathbf{Q}_1^T \neq \mathbf{I}_n$. - $\mathbf{R}_1 \in \mathbb{R}^{p \times p}$ is an upper triangular matrix with positive diagonal entries.
- Given QR decomposition $\mathbf{X} = \mathbf{Q} \mathbf{R}$,
$$
\mathbf{X}^T \mathbf{X} = \mathbf{R}^T \mathbf{Q}^T \mathbf{Q} \mathbf{R} = \mathbf{R}^T \mathbf{R} = \mathbf{R}_1^T \mathbf{R}_1.
$$
- Once we have a (reduced) QR decomposition of $\mathbf{X}$, we automatically have the Cholesky decomposition of the Gram matrix $\mathbf{X}^T \mathbf{X}$.
Least squares¶
- Normal equation
is equivalently written with reduced QR as $$ \mathbf{R}_1^T\mathbf{R}_1\beta = \mathbf{R}_1^T\mathbf{Q}_1^T\mathbf{y} $$
- Since $\mathbf{R}_1$ is invertible, we only need to solve the triangluar system
Multiplication $\mathbf{Q}_1^T \mathbf{y}$ is done implicitly (see below).
This method is numerically more stable than directly solving the normal equation, since $\kappa(\mathbf{X}^T\mathbf{X}) = \kappa(\mathbf{X})^2$!
In case we need standard errors, compute inverse of $\mathbf{R}_1^T \mathbf{R}_1$. This involves triangular solves.
Gram-Schmidt procedure¶
- Wait! Does $\mathbf{X}$ always have a QR decomposition?
- Yes. It is equivalent to the Gram-Schmidt procedure for basis orthonormalization.
Assume $\mathbf{X} = [\mathbf{x}_1 | \dotsb | \mathbf{x}_p] \in \mathbb{R}^{n \times p}$ has full column rank. That is, $\mathbf{x}_1,\ldots,\mathbf{x}_p$ are linearly independent.
Gram-Schmidt (GS) procedure produces nested orthonormal basis vectors $\{\mathbf{q}_1, \dotsc, \mathbf{q}_p\}$ that spans $\mathcal{R}(\mathbf{X})$, i.e.,
and $\langle \mathbf{q}_i, \mathbf{q}_j \rangle = \delta_{ij}$.
- The algorithm: 0. Initialize $\mathbf{q}_1 = \mathbf{x}_1 / \|\mathbf{x}_1\|_2$ 0. For $k=2, \ldots, p$,
GS conducts reduced QR¶
$\mathbf{Q} = [\mathbf{q}_1 | \dotsb | \mathbf{q}_p]$. Obviously $\mathbf{Q}^T \mathbf{Q} = \mathbf{I}_p$.
Where is $\mathbf{R}$?
- Let $r_{jk} = \langle \mathbf{q}_j, \mathbf{x}_k \rangle$ for $j < k$, and $r_{kk} = \|\mathbf{v}_k\|_2$.
- Re-write the above expression:
or
- If we let $r_{jk} = 0$ for $j > k$, then $\mathbf{R}=(r_{jk})$ is upper triangular and $$ \mathbf{X} = \mathbf{Q}\mathbf{R} . $$
Source: https://dsc-spidal.github.io/harp/docs/harpdaal/algorithms/
Classical Gram-Schmidt¶
cgs <- function(X) { # not in-place
n <- dim(X)[1]
p <- dim(X)[2]
Q <- Matrix(0, nrow=n, ncol=p, sparse=FALSE)
R <- Matrix(0, nrow=p, ncol=p, sparse=FALSE)
for (k in seq_len(p)) {
Q[, k] <- X[, k]
for (j in seq_len(k-1)) {
R[j, k] = sum(Q[, j] * X[, k]) # dot product
Q[, k] <- Q[, k] - R[j, k] * Q[, j]
}
R[k, k] <- Matrix::norm(Q[, k, drop=FALSE], "F")
Q[, k] <- Q[, k] / R[k, k]
}
list(Q=Q, R=R)
}
- CGS is unstable (we lose orthogonality due to roundoff errors) when columns of $\mathbf{X}$ are almost collinear.
e <- .Machine$double.eps
(A <- t(Matrix(c(1, 1, 1, e, 0, 0, 0, e, 0, 0, 0, e), nrow=3)))
4 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1.000000e+00 1.000000e+00 1.000000e+00
[2,] 2.220446e-16 0.000000e+00 0.000000e+00
[3,] 0.000000e+00 2.220446e-16 0.000000e+00
[4,] 0.000000e+00 0.000000e+00 2.220446e-16
res <- cgs(A)
res$Q
4 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1.000000e+00 0.0000000 0.0000000
[2,] 2.220446e-16 -0.7071068 -0.7071068
[3,] 0.000000e+00 0.7071068 0.0000000
[4,] 0.000000e+00 0.0000000 0.7071068
with(res, t(Q) %*% Q)
3 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1.000000e+00 -1.570092e-16 -1.570092e-16
[2,] -1.570092e-16 1.000000e+00 5.000000e-01
[3,] -1.570092e-16 5.000000e-01 1.000000e+00
Qis hardly orthogonal.- Where exactly does the problem occur? (HW)
Modified Gram-Schmidt¶
- The algorithm: 0. Initialize $\mathbf{q}_1 = \mathbf{x}_1 / \|\mathbf{x}_1\|_2$ 0. For $k=2, \ldots, p$,
mgs <- function(X) { # in-place
n <- dim(X)[1]
p <- dim(X)[2]
R <- Matrix(0, nrow=p, ncol=p)
for (k in seq_len(p)) {
for (j in seq_len(k-1)) {
R[j, k] <- sum(X[, j] * X[, k]) # dot product
X[, k] <- X[, k] - R[j, k] * X[, j]
}
R[k, k] <- Matrix::norm(X[, k, drop=FALSE], "F")
X[, k] <- X[, k] / R[k, k]
}
list(Q=X, R=R)
}
- $\mathbf{X}$ is overwritten by $\mathbf{Q}$ and $\mathbf{R}$ is stored in a separate array.
mres <- mgs(A)
mres$Q
4 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1.000000e+00 0.0000000 0.0000000
[2,] 2.220446e-16 -0.7071068 -0.4082483
[3,] 0.000000e+00 0.7071068 -0.4082483
[4,] 0.000000e+00 0.0000000 0.8164966
with(mres, t(Q) %*% Q)
3 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1.000000e+00 -1.570092e-16 -9.064933e-17
[2,] -1.570092e-16 1.000000e+00 1.110223e-16
[3,] -9.064933e-17 1.110223e-16 1.000000e+00
- So MGS is more stable than CGS. However, even MGS is not completely immune to instability.
(B <- t(Matrix(c(0.7, 1/sqrt(2), 0.7 + e, 1/sqrt(2)), nrow=2)))
2 x 2 Matrix of class "dgeMatrix"
[,1] [,2]
[1,] 0.7 0.7071068
[2,] 0.7 0.7071068
mres2 <- mgs(B)
mres2$Q
2 x 2 Matrix of class "dgeMatrix"
[,1] [,2]
[1,] 0.7071068 1
[2,] 0.7071068 0
with(mres2, t(Q) %*% Q)
2 x 2 Matrix of class "dgeMatrix"
[,1] [,2]
[1,] 1.0000000 0.7071068
[2,] 0.7071068 1.0000000
Qis hardly orthogonal.- Where exactly does the problem occur? (HW)
Computational cost of CGS and MGS is $\sum_{k=1}^p 4n(k-1) \approx 2np^2$.
There are 3 algorithms to compute QR: (modified) Gram-Schmidt, Householder transform, (fast) Givens transform.
In particular, the Householder transform for QR is implemented in LAPACK and thus used in R, Matlab, and Julia.
QR by Householder transform¶

Alston Scott Householder (1904-1993)
This is the algorithm for solving linear regression in R.
Assume again $\mathbf{X} = [\mathbf{x}_1 | \dotsb | \mathbf{x}_p] \in \mathbb{R}^{n \times p}$ has full column rank.
Gram-Schmidt can be understood as:
where $\mathbf{R}_j$ are a sequence of upper triangular matrices.
- Householder QR does
where $\mathbf{H}_j \in \mathbf{R}^{n \times n}$ are a sequence of Householder transformation matrices.
It yields the **full QR** where $\mathbf{Q} = \mathbf{H}_1 \cdots \mathbf{H}_p \in \mathbb{R}^{n \times n}$. Recall that CGS/MGS only produces the **reduced QR** decomposition.
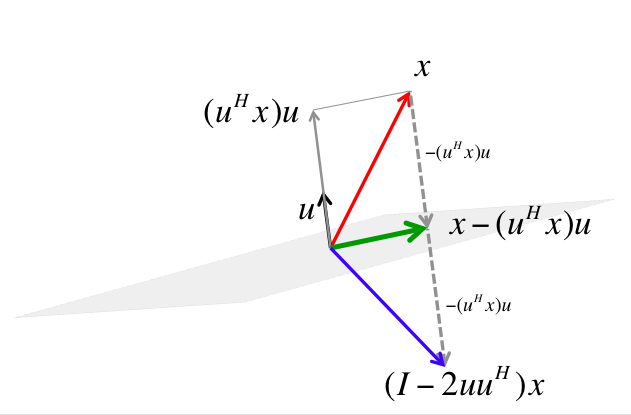
- For arbitrary $\mathbf{x}, \mathbf{w} \in \mathbb{R}^{n}$ with $\|\mathbf{x}\|_2 = \|\mathbf{w}\|_2$, we can construct a Householder matrix (or Householder reflector)
that transforms $\mathbf{x}$ to $\mathbf{w}$: $$ \mathbf{H} \mathbf{x} = \mathbf{w}. $$ To see this, note $\mathbf{u}^T\mathbf{x} = - (\mathbf{x}^T\mathbf{x} - \mathbf{w}^T\mathbf{x})/\Vert \mathbf{x} - \mathbf{w} \Vert_2$. Then $$ \begin{split} \mathbf{H}\mathbf{x} &= \mathbf{x} + \frac{2(\mathbf{x}^T\mathbf{x} - \mathbf{w}^T\mathbf{x})}{\Vert \mathbf{x} - \mathbf{w} \Vert_2}\mathbf{u} = \mathbf{x} - \frac{2(\mathbf{x}^T\mathbf{x} - \mathbf{w}^T\mathbf{x})}{\Vert \mathbf{x} - \mathbf{w} \Vert_2}\frac{\mathbf{x} - \mathbf{w}}{\Vert \mathbf{x} - \mathbf{w} \Vert_2} \\ &= \frac{(\Vert\mathbf{x} - \mathbf{w}\Vert_2^2 - 2\mathbf{x}^T\mathbf{x} + 2\mathbf{w}^T\mathbf{x})\mathbf{x} + 2(\mathbf{x}^T\mathbf{x} - \mathbf{w}^T\mathbf{x})\mathbf{w}}{\Vert \mathbf{x} - \mathbf{w} \Vert_2^2} \\ &= \frac{(\mathbf{x}^T\mathbf{x} + \mathbf{w}^T\mathbf{w} - 2\mathbf{w}^T\mathbf{x} - 2\mathbf{x}^T\mathbf{x} + 2\mathbf{w}^T\mathbf{x})\mathbf{x} + 2(\mathbf{x}^T\mathbf{x} - \mathbf{w}^T\mathbf{x})\mathbf{w}}{\Vert \mathbf{x} - \mathbf{w} \Vert_2^2} \\ &= \frac{(\mathbf{x}^T\mathbf{x} + \mathbf{w}^T\mathbf{w} - 2\mathbf{w}^T\mathbf{x})\mathbf{w}}{\Vert \mathbf{x} - \mathbf{w} \Vert_2^2} \\ &= \frac{\Vert \mathbf{x} - \mathbf{w} \Vert_2^2\mathbf{w}}{\Vert \mathbf{x} - \mathbf{w} \Vert_2^2} = \mathbf{w} \end{split} $$ using $\mathbf{x}^T\mathbf{x} = \mathbf{w}^T\mathbf{w}$.
$\mathbf{H}$ is symmetric and orthogonal. Calculation of Householder vector $\mathbf{u}$ costs $3n$ flops for general $\mathbf{u}$ and $\mathbf{w}$.
Source: https://www.cs.utexas.edu/users/flame/laff/alaff/images/Chapter03/reflector.png
- Now choose $\mathbf{H}_1$ so that
That is, $\mathbf{x} = \mathbf{x}_1$ and $\mathbf{w} = \pm\|\mathbf{x}_1\|_2\mathbf{e}_1$.
- Left-multiplying $\mathbf{H}_1$ zeros out the first column of $\mathbf{X}$ below (1, 1).
- Take $\mathbf{H}_2$ to zero the second column below diagonal:
- In general, choose the $j$-th Householder transform $\mathbf{H}_j = \mathbf{I}_n - 2 \mathbf{u}_j \mathbf{u}_j^T$, where
to zero the $j$-th column below diagonal. $\mathbf{H}_j$ takes the form $$ \mathbf{H}_j = \begin{bmatrix} \mathbf{I}_{j-1} & \\ & \mathbf{I}_{n-j+1} - 2 {\tilde u}_j {\tilde u}_j^T \end{bmatrix} = \begin{bmatrix} \mathbf{I}_{j-1} & \\ & {\tilde H}_{j} \end{bmatrix}. $$
- Applying a Householder transform $\mathbf{H} = \mathbf{I} - 2 \mathbf{u} \mathbf{u}^T$ to a matrix $\mathbf{X} \in \mathbb{R}^{n \times p}$
costs $4np$ flops. Householder updates never entails explicit formation of the Householder matrices.
- Note applying ${\tilde H}_j$ to $\mathbf{X}$ only needs $4(n-j+1)(p-j+1)$ flops.
Algorithm¶
for (j in seq_len(p)) { # in-place
u <- Householer(X[j:n, j])
for (i in j:p)
X[j:n, i] <- X[j:n, i] - 2 * u * sum(u * X[j:n, i])
}
}
The process is done in place. Upper triangular part of $\mathbf{X}$ is overwritten by $\mathbf{R}_1$ and the essential Householder vectors ($\tilde u_{j1}$ is normalized to 1) are stored in $\mathbf{X}[j:n,j]$. Can ensure $u_{j1} \neq 0$ by a clever choice of the sign in determining vector $\mathbf{w}$ above (HW).
At $j$-th stage 0. computing the Householder vector ${\tilde u}_j$ costs $3(n-j+1)$ flops 0. applying the Householder transform ${\tilde H}_j$ to the $\mathbf{X}[j:n, j:p]$ block costs $4(n-j+1)(p-j+1)$ flops
In total we need $\sum_{j=1}^p [3(n-j+1) + 4(n-j+1)(p-j+1)] \approx 2np^2 - \frac 23 p^3$ flops.
Where is $\mathbf{Q}$?
- $\mathbf{Q} = \mathbf{H}_1 \cdots \mathbf{H}_p$. In some applications, it's necessary to form the orthogonal matrix $\mathbf{Q}$.
Accumulating $\mathbf{Q}$ costs another $2np^2 - \frac 23 p^3$ flops.
When computing $\mathbf{Q}^T \mathbf{v}$ or $\mathbf{Q} \mathbf{v}$ as in some applications (e.g., solve linear equation using QR), no need to form $\mathbf{Q}$. Simply apply Householder transforms successively to the vector $\mathbf{v}$. (HW)
Computational cost of Householder QR for linear regression: $2n p^2 - \frac 23 p^3$ (regression coefficients and $\hat \sigma^2$) or more (fitted values, s.e., ...).
X # to recall
y
| 0.3769721 | 0.7205735 | -0.8531228 |
| 0.3015484 | 0.9391210 | 0.9092592 |
| -1.0980232 | -0.2293777 | 1.1963730 |
| -1.1304059 | 1.7591313 | -0.3715839 |
| -2.7965343 | 0.1173668 | -0.1232602 |
- 1.80004311672545
- 1.70399587729432
- -3.03876460529759
- -2.28897494991878
- 0.0583034949929225
coef(lm(y ~ X - 1)) # least squares solution by QR
- X1
- 0.615117663816443
- X2
- -0.00838211603686755
- X3
- -0.770116370364976
# same as
qr.solve(X, y) # or solve(qr(X), y)
- 0.615117663816443
- -0.00838211603686755
- -0.770116370364976
(qrobj <- qr(X, LAPACK=TRUE))
$qr
[,1] [,2] [,3]
[1,] -3.2460924 0.46519442 0.1837043
[2,] 0.0832302 -2.08463446 0.3784090
[3,] -0.3030648 -0.05061826 -1.7211061
[4,] -0.3120027 0.61242637 -0.4073016
[5,] -0.7718699 0.10474144 -0.3750994
$rank
[1] 3
$qraux
[1] 1.116131 1.440301 1.530697
$pivot
[1] 1 2 3
attr(,"useLAPACK")
[1] TRUE
attr(,"class")
[1] "qr"
$qr: a matrix of same size as input matrix$rank: rank of the input matrix$pivot: pivot vector (for rank-deficientX)$aux: normalizing constants of Householder vectors
The upper triangular part of qrobj$qr contains the $\mathbf{R}$ of the decomposition and the lower triangular part contains information on the $\mathbf{Q}$ of the decomposition (stored in compact form using $\mathbf{Q} = \mathbf{H}_1 \cdots \mathbf{H}_p$, HW).
qr.Q(qrobj) # extract Q
| -0.11613105 | -0.3715745 | 0.40159171 |
| -0.09289581 | -0.4712268 | -0.64182039 |
| 0.33825998 | 0.1855167 | -0.61822569 |
| 0.34823590 | -0.7661458 | 0.08461993 |
| 0.86150792 | 0.1359480 | 0.19346097 |
qr.R(qrobj) # extract R
| -3.246092 | 0.4651944 | 0.1837043 |
| 0.000000 | -2.0846345 | 0.3784090 |
| 0.000000 | 0.0000000 | -1.7211061 |
qr.qty(qrobj, y) # this uses the "compact form"
| -2.1421018 |
| -0.2739453 |
| 1.3254520 |
| -3.3263425 |
| 1.7707709 |
t(qr.Q(qrobj)) %*% y # waste of resource
| -2.1421018 |
| -0.2739453 |
| 1.3254520 |
solve(qr.R(qrobj), qr.qty(qrobj, y)[1:p]) # solves R * beta = Q' * y
- 0.615117663816443
- -0.0083821160368676
- -0.770116370364976
Xchol <- Matrix::chol(Matrix::symmpart(t(X) %*% X)) # solution using Cholesky of X'X
solve(Xchol, solve(t(Xchol), t(X) %*% y))
| 0.615117664 |
| -0.008382116 |
| -0.770116370 |
Lets get back to the odd A and B matrices that fooled Gram-Schmidt.
qrA <- qr(A, LAPACK=TRUE)
qr.Q(qrA)
| -1.000000e+00 | 1.570092e-16 | 9.064933e-17 |
| -2.220446e-16 | -7.071068e-01 | -4.082483e-01 |
| 0.000000e+00 | 7.071068e-01 | -4.082483e-01 |
| 0.000000e+00 | 0.000000e+00 | 8.164966e-01 |
t(qr.Q(qrA)) %*% qr.Q(qrA) # orthogonality preserved
| 1 | 0.000000e+00 | 0.000000e+00 |
| 0 | 1.000000e+00 | -1.110223e-16 |
| 0 | -1.110223e-16 | 1.000000e+00 |
qrB <- qr(B, LAPACK=TRUE)
qr.Q(qrB)
| -0.7071068 | -0.7071068 |
| -0.7071068 | 0.7071068 |
t(qr.Q(qrB)) %*% qr.Q(qrB) # orthogonality preserved
| 1.000000e+00 | -1.110223e-16 |
| -1.110223e-16 | 1.000000e+00 |
QR by Givens rotation¶
Householder transform $\mathbf{H}_j$ introduces batch of zeros into a vector.
Givens transform (aka Givens rotation, Jacobi rotation, plane rotation) selectively zeros one element of a vector.
Overall QR by Givens rotation is less efficient than the Householder method, but is better suited for matrices with structured patterns of nonzero elements.
Givens/Jacobi rotations:
where $c = \cos(\theta)$ and $s = \sin(\theta)$. $\mathbf{G}(i,k,\theta)$ is orthogonal.
- Pre-multiplication by $\mathbf{G}(i,k,\theta)^T$ rotates counterclockwise $\theta$ radians in the $(i,k)$ coordinate plane. If $\mathbf{x} \in \mathbb{R}^n$ and $\mathbf{y} = \mathbf{G}(i,k,\theta)^T \mathbf{x}$, then
Apparently if we choose $\tan(\theta) = -x_k / x_i$, or equivalently, $$ \begin{eqnarray*} c = \frac{x_i}{\sqrt{x_i^2 + x_k^2}}, \quad s = \frac{-x_k}{\sqrt{x_i^2 + x_k^2}}, \end{eqnarray*} $$ then $y_k=0$.
- Pre-applying Givens transform $\mathbf{G}(i,k,\theta)^T \in \mathbb{R}^{n \times n}$ to a matrix $\mathbf{A} \in \mathbb{R}^{n \times m}$ only effects two rows of $\mathbf{
A}$: $$ \mathbf{A}([i, k], :) \gets \begin{bmatrix} c & s \\ -s & c \end{bmatrix}^T \mathbf{A}([i, k], :), $$ costing $6m$ flops.
- Post-applying Givens transform $\mathbf{G}(i,k,\theta) \in \mathbb{R}^{m \times m}$ to a matrix $\mathbf{A} \in \mathbb{R}^{n \times m}$ only effects two columns of $\mathbf{A}$:
costing $6n$ flops.
- QR by Givens: $\mathbf{G}_t^T \cdots \mathbf{G}_1^T \mathbf{X} = \begin{bmatrix} \mathbf{R}_1 \\ \mathbf{0} \end{bmatrix}$.

Zeros in $\mathbf{X}$ can also be introduced row-by-row.
If $\mathbf{X} \in \mathbb{R}^{n \times p}$, the total cost is $3np^2 - p^3$ flops and $O(np)$ square roots.
Note each Givens transform can be summarized by a single number, which is stored in the zeroed entry of $\mathbf{X}$.
Conditioning of linear regression by least squares¶
- Recall that for nonsingular linear equation solve, i.e. $\mathbf{A}\mathbf{x} = \mathbf{b}$, the condition number of the problem with $\mathbf{b}$ held fixed is equal to the condition number of matrix $\mathbf{A}$
- If $\mathbf{A}$ is not square, then its condition number is
where $\mathbf{A}^{\dagger}$ is Moore-Penrose pseudoinverse of $\mathbf{A}$.
- Condition number for the least squares problem $\mathbf{y} \approx \mathbf{X}\boldsymbol{\beta}$ is more complicated and depends on the residual. It can be shown that the condition number is
where
$$ \theta = \cos^{-1}\frac{\|\mathbf{X}\boldsymbol{\beta}\|}{\|\boldsymbol{\beta}\|}, \quad \eta = \frac{\|\mathbf{X}\|\|\boldsymbol{\beta}\|}{\|\mathbf{X}\boldsymbol{\beta}\|} . $$- So if $\kappa(\mathbf{X})$ is large ($\mathbf{X}$ is close to collinear), the condition number of the least squares problem is dominated by $\kappa(\mathbf{X})^2$, unless the residuals are small.
- In this case, stable algorithm is preferred.
- This is because the problem is equivalent to the normal equation
- Consider the simple case
Forming normal equation yields a singular Gramian matrix $$ \begin{eqnarray*} \mathbf{X}^T \mathbf{X} = \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix} \end{eqnarray*} $$ if executed with a precision of 6 decimal digits. This has the condition number $\kappa(\mathbf{X}^T\mathbf{X})=\infty$.
Summary of linear regression¶
Methods for solving linear regression $\widehat \beta = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y}$:
| Method | Flops | Remarks | Software | Stability |
|---|---|---|---|---|
| Cholesky | $np^2 + p^3/3$ | unstable | ||
| QR by Householder | $2np^2 - (2/3)p^3$ | R, Julia, MATLAB | stable | |
| QR by MGS | $2np^2$ | $Q_1$ available | stable | |
| QR by SVD | $4n^2p + 8np^2 + 9p^3$ | $X = UDV^T$ | most stable |
Remarks:
- When $n \gg p$, Cholesky is twice faster than QR and need less space.
- Cholesky is based on the Gram matrix $\mathbf{X}^T \mathbf{X}$, which can be dynamically updated with incoming data. They can handle huge $n$, moderate $p$ data sets that cannot fit into memory.
- QR methods are more stable and produce numerically more accurate solution.
- MGS appears slower than Householder, but it yields $\mathbf{Q}_1$.
There is simply no such thing as a universal 'gold standard' when it comes to algorithms.
Underdetermined least squares¶
When the Gram matrix $\mathbf{X}^T\mathbf{X}$ is singular (this happens if $\text{rank}(\mathbf{X})<p$, in particular $n < p$), the normal equation $\mathbf{X}^T\mathbf{X}\boldsymbol{\beta} = \mathbf{X}^T\mathbf{y}$ is underdetermined.
It has many solutions unless an additional condition is added.
Typically we require solution $\mathbf{x}$ has a smallest norm; the solution depends on the choice of the norm.
- Example: minimum $\ell_2$ norm solution
- Solution is closed form: $\hat{\boldsymbol{\beta}} = \mathbf{X}^{\dagger}\mathbf{y}$, where $\mathbf{X}^{\dagger}$ is the Moore-Penrose pseudoinverse of $\mathbf{X}$: $\mathbf{X}^{\dagger} = \mathbf{X}^T(\mathbf{X}\mathbf{X}^T)^{-1}$ if $n<p$ and $\mathbf{X}$ has full row rank.
- In fact $\hat{\boldsymbol{\beta}}$ is a limit of the ridge regression: $\hat{\boldsymbol{\beta}} = \lim_{\lambda\to 0}(\mathbf{X}^T\mathbf{X}+\lambda\mathbf{I})^{-1}\mathbf{X}^T\mathbf{y}$.
- Example: minimum $\ell_0$ "norm" solution
- $\|\mathbf{x}\|_0 \triangleq \sum_{i=1}^p \mathbf{1}_{\{x_i\neq 0\}}$, the "sparsest" solution.
- Model selection problem. Combinatorial (intractable if $p$ large).
- Compromise: minimum $\ell_1$ norm solution
- LASSO.
- Convex optimization problem (linear programming). Tractable.
- Under certain conditions recovers the minimum $\ell_0$ norm solution.